 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Self-Pruning Intrinsic Selection Method for Training-Free Multimodal Data Selection
Paper and Code
Feb 17, 2025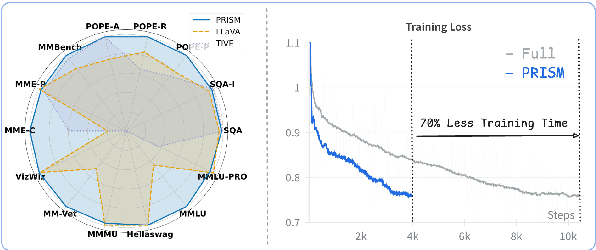
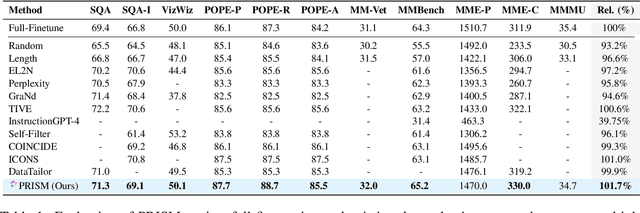
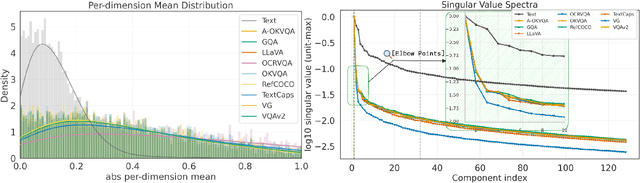
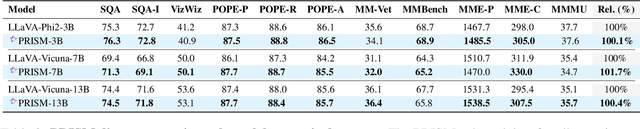
Visual instruction tuning refines pre-trained Multimodal Large Language Models (MLLMs) to enhance their real-world task performance. However, the rapid expansion of visual instruction datasets introduces significant data redundancy, leading to excessive computational costs. Existing data selection methods predominantly rely on proxy models or loss-based metrics, both of which impose substantial computational overheads due to the necessity of model inference and backpropagation. To address this challenge, we propose PRISM, a novel training-free approach for efficient multimodal data selection. Unlike existing methods, PRISM eliminates the reliance on proxy models, warm-up pretraining, and gradient-based optimization. Instead, it leverages Pearson correlation analysis to quantify the intrinsic visual encoding properties of MLLMs, computing a task-specific correlation score to identify high-value instances. This not only enbles data-efficient selection,but maintains the original performance. Empirical evaluations across multiple MLLMs demonstrate that PRISM reduces the overall time required for visual instruction tuning and data selection to just 30% of conventional methods, while surpassing fully fine-tuned models across eight multimodal and three language understanding benchmarks, achieving a 101.7% relative improvement in final performance.