 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRM-Hair: Single Image Head Mesh Reconstruction via 3D Morphable Hair
Mar 08, 20253D Morphable Models (3DMMs) have played a pivotal role as a fundamental representation or initialization for 3D avatar animation and reconstruction. However, extending 3DMMs to hair remains challenging due to the difficulty of enforcing vertex-level consistent semantic meaning across hair shapes. This paper introduces a novel method, Semantic-consistent Ray Modeling of Hair (SRM-Hair), for making 3D hair morphable and controlled by coefficients. The key contribution lies in semantic-consistent ray modeling, which extracts ordered hair surface vertices and exhibits notable properties such as additivity for hairstyle fusion, adaptability, flipping, and thickness modification. We collect a dataset of over 250 high-fidelity real hair scans paired with 3D face data to serve as a prior for the 3D morphable hair. Based on this, SRM-Hair can reconstruct a hair mesh combined with a 3D head from a single image. Note that SRM-Hair produces an independent hair mesh, facilitating applications in virtual avatar creation, realistic animation, and high-fidelity hair rendering. Both quantitative and qualitative experiments demonstrate that SRM-Hair achieves state-of-the-art performance in 3D mesh reconstruction. Our project is available at https://github.com/wang-zidu/SRM-Hair
S2TD-Face: Reconstruct a Detailed 3D Face with Controllable Texture from a Single Sketch
Aug 02, 2024



3D textured face reconstruction from sketches applicable in many scenarios such as animation, 3D avatars, artistic design, missing people search, etc., is a highly promising but underdeveloped research topic. On the one hand, the stylistic diversity of sketches leads to existing sketch-to-3D-face methods only being able to handle pose-limited and realistically shaded sketches. On the other hand, texture plays a vital role in representing facial appearance, yet sketches lack this information, necessitating additional texture control in the reconstruction process. This paper proposes a novel method for reconstructing controllable textured and detailed 3D faces from sketches, named S2TD-Face. S2TD-Face introduces a two-stage geometry reconstruction framework that directly reconstructs detailed geometry from the input sketch. To keep geometry consistent with the delicate strokes of the sketch, we propose a novel sketch-to-geometry loss that ensures the reconstruction accurately fits the input features like dimples and wrinkles. Our training strategies do not rely on hard-to-obtain 3D face scanning data or labor-intensive hand-drawn sketches. Furthermore, S2TD-Face introduces a texture control module utilizing text prompts to select the most suitable textures from a library and seamlessly integrate them into the geometry, resulting in a 3D detailed face with controllable texture. S2TD-Face surpasses existing state-of-the-art methods in extensive quantitative and qualitative experiments. Our project is available at https://github.com/wang-zidu/S2TD-Face .
3D Face Reconstruction with the Geometric Guidance of Facial Part Segmentation
Dec 04, 2023



3D Morphable Models (3DMMs) provide promising 3D face reconstructions in various applications. However, existing methods struggle to reconstruct faces with extreme expressions due to deficiencies in supervisory signals, such as sparse or inaccurate landmarks. Segmentation information contains effective geometric contexts for face reconstruction. Certain attempts intuitively depend on differentiable renderers to compare the rendered silhouettes of reconstruction with segmentation, which is prone to issues like local optima and gradient instability. In this paper, we fully utilize the facial part segmentation geometry by introducing Part Re-projection Distance Loss (PRDL). Specifically, PRDL transforms facial part segmentation into 2D points and re-projects the reconstruction onto the image plane. Subsequently, by introducing grid anchors and computing different statistical distances from these anchors to the point sets, PRDL establishes geometry descriptors to optimize the distribution of the point sets for face reconstruction. PRDL exhibits a clear gradient compared to the renderer-based methods and presents state-of-the-art reconstruction performance in extensive quantitative and qualitative experiments. The project will be publicly available.
HP-Capsule: Unsupervised Face Part Discovery by Hierarchical Parsing Capsule Network
Mar 21, 2022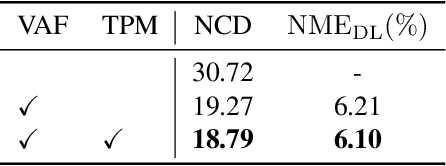

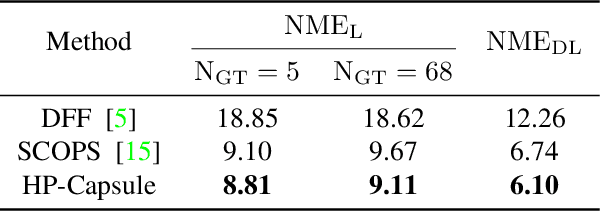
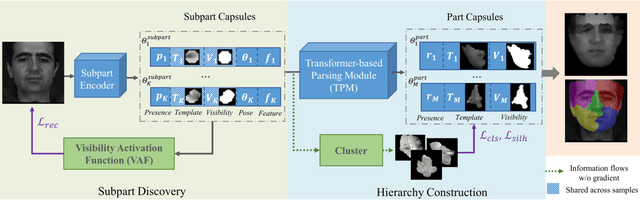
Capsule networks are designed to present the objects by a set of parts and their relationships, which provide an insight into the procedure of visual perception. Although recent works have shown the success of capsule networks on simple objects like digits, the human faces with homologous structures, which are suitable for capsules to describe, have not been explored. In this paper, we propose a Hierarchical Parsing Capsule Network (HP-Capsule) for unsupervised face subpart-part discovery. When browsing large-scale face images without labels, the network first encodes the frequently observed patterns with a set of explainable subpart capsules. Then, the subpart capsules are assembled into part-level capsules through a Transformer-based Parsing Module (TPM) to learn the compositional relations between them. During training, as the face hierarchy is progressively built and refined, the part capsules adaptively encode the face parts with semantic consistency. HP-Capsule extends the application of capsule networks from digits to human faces and takes a step forward to show how the neural networks understand homologous objects without human intervention. Besides, HP-Capsule gives unsupervised face segmentation results by the covered regions of part capsules, enabling qualitative and quantitative evaluation. Experiments on BP4D and Multi-PIE datasets show the effectiveness of our method.
Model Pruning Based on Quantified Similarity of Feature Maps
May 13, 2021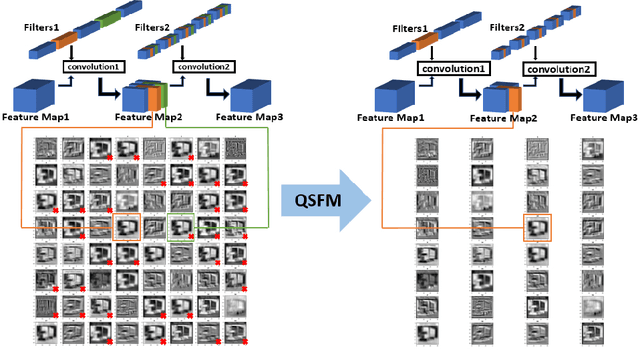

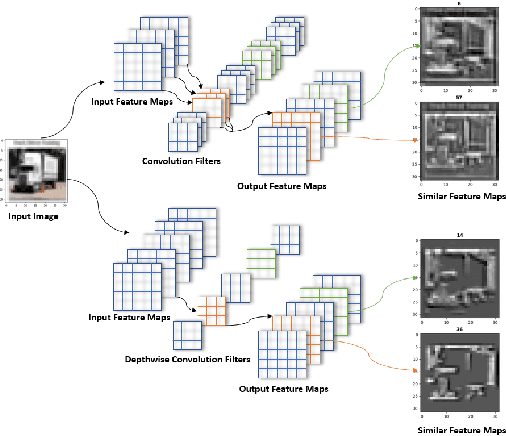
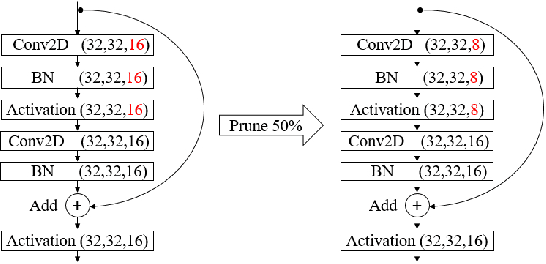
A high-accuracy CNN is often accompanied by huge parameters, which are usually stored in the high-dimensional tensors. However, there are few methods can figure out the redundant information of the parameters stored in the high-dimensional tensors, which leads to the lack of theoretical guidance for the compression of CNNs. In this paper, we propose a novel theory to find redundant information in three dimensional tensors, namely Quantified Similarity of Feature Maps (QSFM), and use this theory to prune convolutional neural networks to enhance the inference speed. Our method belongs to filter pruning, which can be implemented without using any special libraries. We perform our method not only on common convolution layers but also on special convolution layers, such as depthwise separable convolution layers. The experiments prove that QSFM can find the redundant information in the neural network effectively. Without any fine-tuning operation, QSFM can compress ResNet-56 on CIFAR-10 significantly (48.27% FLOPs and 57.90% parameters reduction) with only a loss of 0.54% in the top-1 accuracy. QSFM also prunes ResNet-56, VGG-16 and MobileNetV2 with fine-tuning operation, which also shows excellent results.