 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRM-Hair: Single Image Head Mesh Reconstruction via 3D Morphable Hair
Mar 08, 20253D Morphable Models (3DMMs) have played a pivotal role as a fundamental representation or initialization for 3D avatar animation and reconstruction. However, extending 3DMMs to hair remains challenging due to the difficulty of enforcing vertex-level consistent semantic meaning across hair shapes. This paper introduces a novel method, Semantic-consistent Ray Modeling of Hair (SRM-Hair), for making 3D hair morphable and controlled by coefficients. The key contribution lies in semantic-consistent ray modeling, which extracts ordered hair surface vertices and exhibits notable properties such as additivity for hairstyle fusion, adaptability, flipping, and thickness modification. We collect a dataset of over 250 high-fidelity real hair scans paired with 3D face data to serve as a prior for the 3D morphable hair. Based on this, SRM-Hair can reconstruct a hair mesh combined with a 3D head from a single image. Note that SRM-Hair produces an independent hair mesh, facilitating applications in virtual avatar creation, realistic animation, and high-fidelity hair rendering. Both quantitative and qualitative experiments demonstrate that SRM-Hair achieves state-of-the-art performance in 3D mesh reconstruction. Our project is available at https://github.com/wang-zidu/SRM-Hair
Revisiting Marr in Face: The Building of 2D--2.5D--3D Representations in Deep Neural Networks
Nov 25, 2024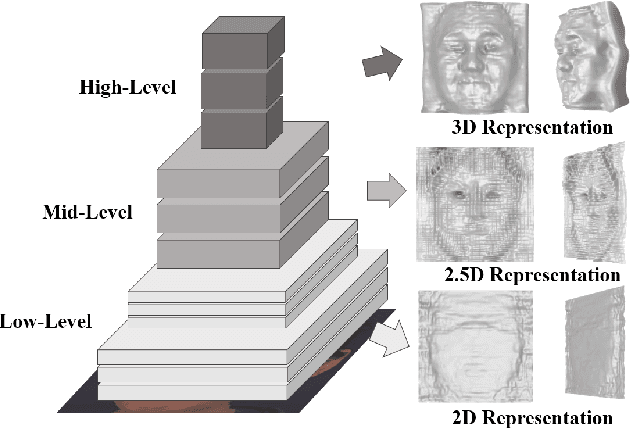



David Marr's seminal theory of vision proposes that the human visual system operates through a sequence of three stages, known as the 2D sketch, the 2.5D sketch, and the 3D model. In recent years, Deep Neural Networks (DNN) have been widely thought to have reached a level comparable to human vision. However, the mechanisms by which DNNs accomplish this and whether they adhere to Marr's 2D--2.5D--3D construction theory remain unexplored. In this paper, we delve into the perception task to explore these questions and find evidence supporting Marr's theory. We introduce a graphics probe, a sub-network crafted to reconstruct the original image from the network's intermediate layers. The key to the graphics probe is its flexible architecture that supports image in both 2D and 3D formats, as well as in a transitional state between them. By injecting graphics probes into neural networks, and analyzing their behavior in reconstructing images, we find that DNNs initially encode images as 2D representations in low-level layers, and finally construct 3D representations in high-level layers. Intriguingly, in mid-level layers, DNNs exhibit a hybrid state, building a geometric representation that s sur normals within a narrow depth range, akin to the appearance of a low-relief sculpture. This stage resembles the 2.5D representations, providing a view of how DNNs evolve from 2D to 3D in the perception process. The graphics probe therefore serves as a tool for peering into the mechanisms of DNN, providing empirical support for Marr's theory.