 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Immune Algorithm for Multiparty Multiobjective Optimization
Mar 29, 2026Traditional multiobjective optimization problems (MOPs) are insufficiently equipped for scenarios involving multiple decision makers (DMs), which are prevalent in many practical applications. These scenarios are categorized as multiparty multiobjective optimization problems (MPMOPs). For MPMOPs, the goal is to find a solution set that is as close to the Pareto front of each DM as much as possible. This poses challenges for evolutionary algorithms in terms of searching and selecting. To better solve MPMOPs, this paper proposes a novel approach called the multiparty immune algorithm (MPIA). The MPIA incorporates an inter-party guided crossover strategy based on the individual's non-dominated sorting ranks from different DM perspectives and an adaptive activation strategy based on the proposed multiparty cover metric (MCM). These strategies enable MPIA to activate suitable individuals for the next operations, maintain population diversity from different DM perspectives, and enhance the algorithm's search capability. To evaluate the performance of MPIA, we compare it with ordinary multiobjective evolutionary algorithms (MOEAs) and state-of-the-art multiparty multiobjective optimization evolutionary algorithms (MPMOEAs) by solving synthetic multiparty multiobjective problems and real-world biparty multiobjective unmanned aerial vehicle path planning (BPUAV-PP) problems involving multiple DMs. Experimental results demonstrate that MPIA outperforms other algorithms.
* \c{opyright} 2026 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Fairness-Aware Performance Evaluation for Multi-Party Multi-Objective Optimization
Jan 30, 2026In multiparty multiobjective optimization problems, solution sets are usually evaluated using classical performance metrics, aggregated across DMs. However, such mean-based evaluations may be unfair by favoring certain parties, as they assume identical geometric approximation quality to each party's PF carries comparable evaluative significance. Moreover, prevailing notions of MPMOP optimal solutions are restricted to strictly common Pareto optimal solutions, representing a narrow form of cooperation in multiparty decision making scenarios. These limitations obscure whether a solution set reflects balanced relative gains or meaningful consensus among heterogeneous DMs. To address these issues, this paper develops a fairness-aware performance evaluation framework grounded in a generalized notion of consensus solutions. From a cooperative game-theoretic perspective, we formalize four axioms that a fairness-aware evaluation function for MPMOPs should satisfy. By introducing a concession rate vector to quantify acceptable compromises by individual DMs, we generalize the classical definition of MPMOP optimal solutions and embed classical performance metrics into a Nash-product-based evaluation framework, which is theoretically shown to satisfy all axioms. To support empirical validation, we further construct benchmark problems that extend existing MPMOP suites by incorporating consensus-deficient negotiation structures. Experimental results demonstrate that the proposed evaluation framework is able to distinguish algorithmic performance in a manner consistent with consensus-aware fairness considerations. Specifically, algorithms converging toward strictly common solutions are assigned higher evaluation scores when such solutions exist, whereas in the absence of strictly common solutions, algorithms that effectively cover the commonly acceptable region are more favorably evaluated.
Decomposability-Guaranteed Cooperative Coevolution for Large-Scale Itinerary Planning
Jun 06, 2025Large-scale itinerary planning is a variant of the traveling salesman problem, aiming to determine an optimal path that maximizes the collected points of interest (POIs) scores while minimizing travel time and cost, subject to travel duration constraints. This paper analyzes the decomposability of large-scale itinerary planning, proving that strict decomposability is difficult to satisfy, and introduces a weak decomposability definition based on a necessary condition, deriving the corresponding graph structures that fulfill this property. With decomposability guaranteed, we propose a novel multi-objective cooperative coevolutionary algorithm for large-scale itinerary planning, addressing the challenges of component imbalance and interactions. Specifically, we design a dynamic decomposition strategy based on the normalized fitness within each component, define optimization potential considering component scale and contribution, and develop a computational resource allocation strategy. Finally, we evaluate the proposed algorithm on a set of real-world datasets. Comparative experiments with state-of-the-art multi-objective itinerary planning algorithms demonstrate the superiority of our approach, with performance advantages increasing as the problem scale grows.
Narrative-Driven Travel Planning: Geoculturally-Grounded Script Generation with Evolutionary Itinerary Optimization
Feb 20, 2025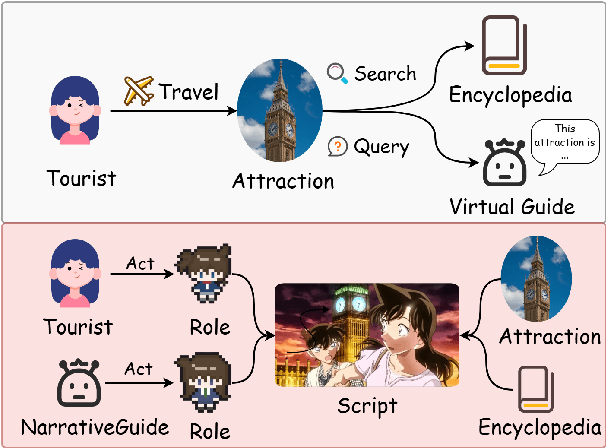
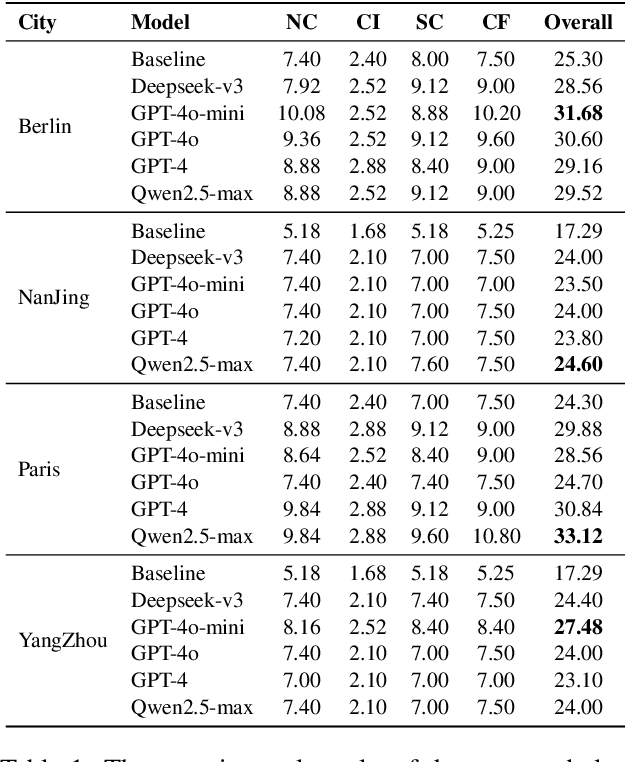
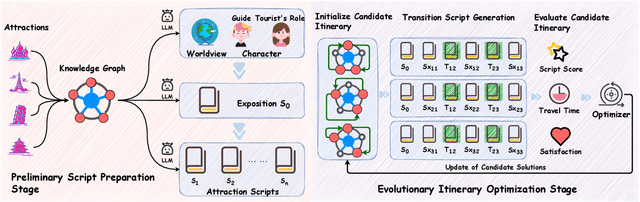
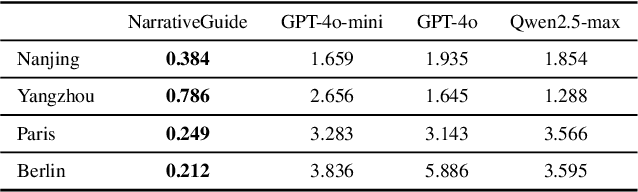
To enhance tourists' experiences and immersion, this paper proposes a narrative-driven travel planning framework called NarrativeGuide, which generates a geoculturally-grounded narrative script for travelers, offering a novel, role-playing experience for their journey. In the initial stage, NarrativeGuide constructs a knowledge graph for attractions within a city, then configures the worldview, character setting, and exposition based on the knowledge graph. Using this foundation, the knowledge graph is combined to generate an independent scene unit for each attraction. During the itinerary planning stage, NarrativeGuide models narrative-driven travel planning as an optimization problem, utilizing a genetic algorithm (GA) to refine the itinerary. Before evaluating the candidate itinerary, transition scripts are generated for each pair of adjacent attractions, which, along with the scene units, form a complete script. The weighted sum of script coherence, travel time, and attraction scores is then used as the fitness value to update the candidate solution set. Experimental results across four cities, i.e., Nanjing and Yangzhou in China, Paris in France, and Berlin in Germany, demonstrate significant improvements in narrative coherence and cultural fit, alongside a notable reduction in travel time and an increase in the quality of visited attractions. Our study highlights that incorporating external evolutionary optimization effectively addresses the limitations of large language models in travel planning.Our codes are available at https://github.com/Evan01225/Narrative-Driven-Travel-Planning.
Graph Retrieval Augmented Trustworthiness Reasoning
Aug 22, 2024Trustworthiness reasoning is crucial in multiplayer games with incomplete information, enabling agents to identify potential allies and adversaries, thereby enhancing reasoning and decision-making processes. Traditional approaches relying on pre-trained models necessitate extensive domain-specific data and considerable reward feedback, with their lack of real-time adaptability hindering their effectiveness in dynamic environments. In this paper, we introduce the Graph Retrieval Augmented Reasoning (GRATR) framework, leveraging the Retrieval-Augmented Generation (RAG) technique to bolster trustworthiness reasoning in agents. GRATR constructs a dynamic trustworthiness graph, updating it in real-time with evidential information, and retrieves relevant trust data to augment the reasoning capabilities of Large Language Models (LLMs). We validate our approach through experiments on the multiplayer game "Werewolf," comparing GRATR against baseline LLM and LLM enhanced with Native RAG and Rerank RAG. Our results demonstrate that GRATR surpasses the baseline methods by over 30\% in winning rate, with superior reasoning performance. Moreover, GRATR effectively mitigates LLM hallucinations, such as identity and objective amnesia, and crucially, it renders the reasoning process more transparent and traceable through the use of the trustworthiness graph.
Benchmark for CEC 2024 Competition on Multiparty Multiobjective Optimization
Feb 03, 2024The competition focuses on Multiparty Multiobjective Optimization Problems (MPMOPs), where multiple decision makers have conflicting objectives, as seen in applications like UAV path planning. Despite their importance, MPMOPs remain understudied in comparison to conventional multiobjective optimization. The competition aims to address this gap by encouraging researchers to explore tailored modeling approaches. The test suite comprises two parts: problems with common Pareto optimal solutions and Biparty Multiobjective UAV Path Planning (BPMO-UAVPP) problems with unknown solutions. Optimization algorithms for the first part are evaluated using Multiparty Inverted Generational Distance (MPIGD), and the second part is evaluated using Multiparty Hypervolume (MPHV) metrics. The average algorithm ranking across all problems serves as a performance benchmark.