 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrift-Aware Online Dynamic Learning for Nonstationary Multivariate Time Series: Application to Sintering Quality Prediction
Apr 10, 2026Accurate prediction of nonstationary multivariate time series remains a critical challenge in complex industrial systems such as iron ore sintering. In practice, pronounced concept drift compounded by significant label verification latency rapidly degrades the performance of offline-trained models. Existing methods based on static architectures or passive update strategies struggle to simultaneously extract multi-scale spatiotemporal features and overcome the stability-plasticity dilemma without immediate supervision. To address these limitations, a Drift-Aware Multi-Scale Dynamic Learning (DA-MSDL) framework is proposed to maintain robust multi-output predictive performance via online adaptive mechanisms on nonstationary data streams. The framework employs a multi-scale bi-branch convolutional network as its backbone to disentangle local fluctuations from long-term trends, thereby enhancing representational capacity for complex dynamic patterns. To circumvent the label latency bottleneck, DA-MSDL leverages Maximum Mean Discrepancy (MMD) for unsupervised drift detection. By quantifying online statistical deviations in feature distributions, DA-MSDL proactively triggers model adaptation prior to inference. Furthermore, a drift-severity-guided hierarchical fine-tuning strategy is developed. Supported by prioritized experience replay from a dynamic memory queue, this approach achieves rapid distribution alignment while effectively mitigating catastrophic forgetting. Long-horizon experiments on real-world industrial sintering data and a public benchmark dataset demonstrate that DA-MSDL consistently outperforms representative baselines under severe concept drift. Exhibiting strong cross-domain generalization and predictive stability, the proposed framework provides an effective online dynamic learning paradigm for quality monitoring in nonstationary environments.
Auto-Configured Networks for Multi-Scale Multi-Output Time-Series Forecasting
Apr 08, 2026Industrial forecasting often involves multi-source asynchronous signals and multi-output targets, while deployment requires explicit trade-offs between prediction error and model complexity. Current practices typically fix alignment strategies or network designs, making it difficult to systematically co-design preprocessing, architecture, and hyperparameters in budget-limited training-based evaluations. To address this issue, we propose an auto-configuration framework that outputs a deployable Pareto set of forecasting models balancing error and complexity. At the model level, a Multi-Scale Bi-Branch Convolutional Neural Network (MS--BCNN) is developed, where short- and long-kernel branches capture local fluctuations and long-term trends, respectively, for multi-output regression. At the search level, we unify alignment operators, architectural choices, and training hyperparameters into a hierarchical-conditional mixed configuration space, and apply Player-based Hybrid Multi-Objective Evolutionary Algorithm (PHMOEA) to approximate the error--complexity Pareto frontier within a limited computational budget. Experiments on hierarchical synthetic benchmarks and a real-world sintering dataset demonstrate that our framework outperforms competitive baselines under the same budget and offers flexible deployment choices.
Variable Search Stepsize for Randomized Local Search in Multi-Objective Combinatorial Optimization
Feb 05, 2026Over the past two decades, research in evolutionary multi-objective optimization has predominantly focused on continuous domains, with comparatively limited attention given to multi-objective combinatorial optimization problems (MOCOPs). Combinatorial problems differ significantly from continuous ones in terms of problem structure and landscape. Recent studies have shown that on MOCOPs multi-objective evolutionary algorithms (MOEAs) can even be outperformed by simple randomised local search. Starting with a randomly sampled solution in search space, randomised local search iteratively draws a random solution (from an archive) to perform local variation within its neighbourhood. However, in most existing methods, the local variation relies on a fixed neighbourhood, which limits exploration and makes the search easy to get trapped in local optima. In this paper, we present a simple yet effective local search method, called variable stepsize randomized local search (VS-RLS), which adjusts the stepsize during the search. VS-RLS transitions gradually from a broad, exploratory search in the early phases to a more focused, fine-grained search as the search progresses. We demonstrate the effectiveness and generalizability of VS-RLS through extensive evaluations against local search and MOEAs methods on diverse MOCOPs.
Nearest-Better Network for Visualizing and Analyzing Combinatorial Optimization Problems: A Unified Tool
Jul 30, 2025The Nearest-Better Network (NBN) is a powerful method to visualize sampled data for continuous optimization problems while preserving multiple landscape features. However, the calculation of NBN is very time-consuming, and the extension of the method to combinatorial optimization problems is challenging but very important for analyzing the algorithm's behavior. This paper provides a straightforward theoretical derivation showing that the NBN network essentially functions as the maximum probability transition network for algorithms. This paper also presents an efficient NBN computation method with logarithmic linear time complexity to address the time-consuming issue. By applying this efficient NBN algorithm to the OneMax problem and the Traveling Salesman Problem (TSP), we have made several remarkable discoveries for the first time: The fitness landscape of OneMax exhibits neutrality, ruggedness, and modality features. The primary challenges of TSP problems are ruggedness, modality, and deception. Two state-of-the-art TSP algorithms (i.e., EAX and LKH) have limitations when addressing challenges related to modality and deception, respectively. LKH, based on local search operators, fails when there are deceptive solutions near global optima. EAX, which is based on a single population, can efficiently maintain diversity. However, when multiple attraction basins exist, EAX retains individuals within multiple basins simultaneously, reducing inter-basin interaction efficiency and leading to algorithm's stagnation.
An Evolutionary Network Architecture Search Framework with Adaptive Multimodal Fusion for Hand Gesture Recognition
Mar 27, 2024



Hand gesture recognition (HGR) based on multimodal data has attracted considerable attention owing to its great potential in applications. Various manually designed multimodal deep networks have performed well in multimodal HGR (MHGR), but most of existing algorithms require a lot of expert experience and time-consuming manual trials. To address these issues, we propose an evolutionary network architecture search framework with the adaptive multimodel fusion (AMF-ENAS). Specifically, we design an encoding space that simultaneously considers fusion positions and ratios of the multimodal data, allowing for the automatic construction of multimodal networks with different architectures through decoding. Additionally, we consider three input streams corresponding to intra-modal surface electromyography (sEMG), intra-modal accelerometer (ACC), and inter-modal sEMG-ACC. To automatically adapt to various datasets, the ENAS framework is designed to automatically search a MHGR network with appropriate fusion positions and ratios. To the best of our knowledge, this is the first time that ENAS has been utilized in MHGR to tackle issues related to the fusion position and ratio of multimodal data. Experimental results demonstrate that AMF-ENAS achieves state-of-the-art performance on the Ninapro DB2, DB3, and DB7 datasets.
Benchmark for CEC 2024 Competition on Multiparty Multiobjective Optimization
Feb 03, 2024The competition focuses on Multiparty Multiobjective Optimization Problems (MPMOPs), where multiple decision makers have conflicting objectives, as seen in applications like UAV path planning. Despite their importance, MPMOPs remain understudied in comparison to conventional multiobjective optimization. The competition aims to address this gap by encouraging researchers to explore tailored modeling approaches. The test suite comprises two parts: problems with common Pareto optimal solutions and Biparty Multiobjective UAV Path Planning (BPMO-UAVPP) problems with unknown solutions. Optimization algorithms for the first part are evaluated using Multiparty Inverted Generational Distance (MPIGD), and the second part is evaluated using Multiparty Hypervolume (MPHV) metrics. The average algorithm ranking across all problems serves as a performance benchmark.
An Evolving Population Approach to Data-Stream Classification with Extreme Verification Latency
Dec 07, 2023Recognising and reacting to change in non-stationary data-streams is a challenging task. The majority of research in this area assumes that the true class label of incoming points are available, either at each time step or intermittently with some latency. In the worse case this latency approaches infinity and we can assume that no labels are available beyond the initial training set. When change is expected and no further training labels are provided the challenge of maintaining a high classification accuracy is very great. The challenge is to propagate the original training information through several timesteps, possibly indefinitely, while adapting to underlying change in the data-stream. In this paper we conduct an initial study into the effectiveness of using an evolving, population-based approach as the mechanism for adapting to change. An ensemble of one-class-classifiers is maintained for each class. Each classifier is considered as an agent in the sub-population and is subject to selection pressure to find interesting areas of the feature space. This selection pressure forces the ensemble to adapt to the underlying change in the data-stream.
Vector Autoregressive Evolution for Dynamic Multi-Objective Optimisation
May 22, 2023



Dynamic multi-objective optimisation (DMO) handles optimisation problems with multiple (often conflicting) objectives in varying environments. Such problems pose various challenges to evolutionary algorithms, which have popularly been used to solve complex optimisation problems, due to their dynamic nature and resource restrictions in changing environments. This paper proposes vector autoregressive evolution (VARE) consisting of vector autoregression (VAR) and environment-aware hypermutation to address environmental changes in DMO. VARE builds a VAR model that considers mutual relationship between decision variables to effectively predict the moving solutions in dynamic environments. Additionally, VARE introduces EAH to address the blindness of existing hypermutation strategies in increasing population diversity in dynamic scenarios where predictive approaches are unsuitable. A seamless integration of VAR and EAH in an environment-adaptive manner makes VARE effective to handle a wide range of dynamic environments and competitive with several popular DMO algorithms, as demonstrated in extensive experimental studies. Specially, the proposed algorithm is computationally 50 times faster than two widely-used algorithms (i.e., TrDMOEA and MOEA/D-SVR) while producing significantly better results.
Semi-supervised Deep Learning for Image Classification with Distribution Mismatch: A Survey
Mar 10, 2022
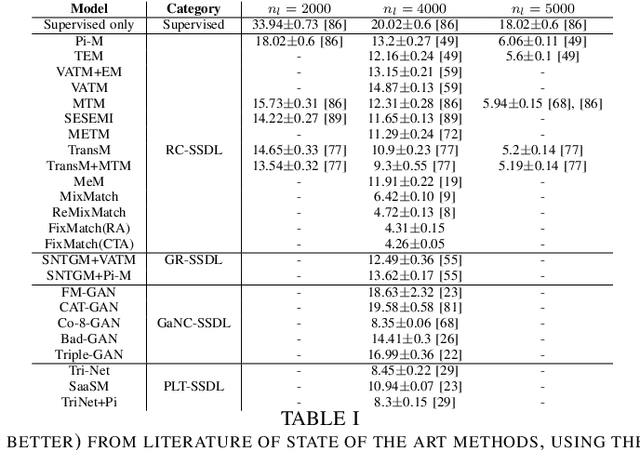
Deep learning methodologies have been employed in several different fields, with an outstanding success in image recognition applications, such as material quality control, medical imaging, autonomous driving, etc. Deep learning models rely on the abundance of labelled observations to train a prospective model. These models are composed of millions of parameters to estimate, increasing the need of more training observations. Frequently it is expensive to gather labelled observations of data, making the usage of deep learning models not ideal, as the model might over-fit data. In a semi-supervised setting, unlabelled data is used to improve the levels of accuracy and generalization of a model with small labelled datasets. Nevertheless, in many situations different unlabelled data sources might be available. This raises the risk of a significant distribution mismatch between the labelled and unlabelled datasets. Such phenomena can cause a considerable performance hit to typical semi-supervised deep learning frameworks, which often assume that both labelled and unlabelled datasets are drawn from similar distributions. Therefore, in this paper we study the latest approaches for semi-supervised deep learning for image recognition. Emphasis is made in semi-supervised deep learning models designed to deal with a distribution mismatch between the labelled and unlabelled datasets. We address open challenges with the aim to encourage the community to tackle them, and overcome the high data demand of traditional deep learning pipelines under real-world usage settings.
Benchmark Functions for CEC 2022 Competition on Seeking Multiple Optima in Dynamic Environments
Jan 06, 2022
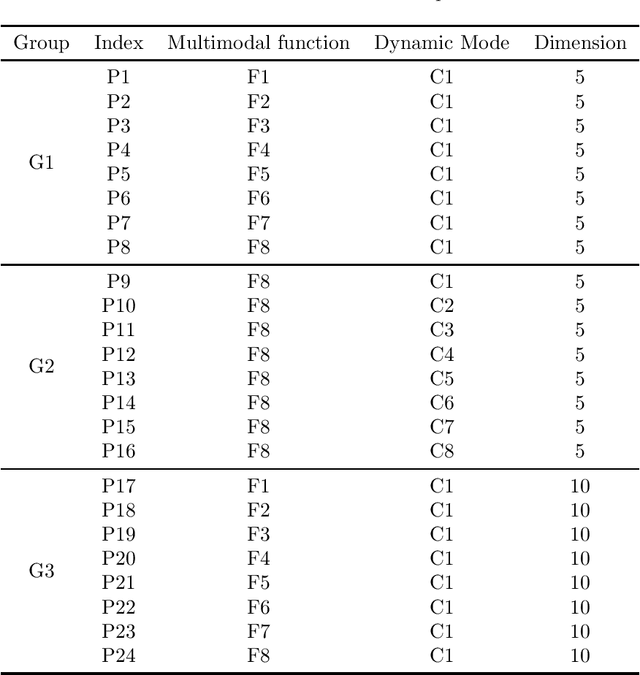
Dynamic and multimodal features are two important properties and widely existed in many real-world optimization problems. The former illustrates that the objectives and/or constraints of the problems change over time, while the latter means there is more than one optimal solution (sometimes including the accepted local solutions) in each environment. The dynamic multimodal optimization problems (DMMOPs) have both of these characteristics, which have been studied in the field of evolutionary computation and swarm intelligence for years, and attract more and more attention. Solving such problems requires optimization algorithms to simultaneously track multiple optima in the changing environments. So that the decision makers can pick out one optimal solution in each environment according to their experiences and preferences, or quickly turn to other solutions when the current one cannot work well. This is very helpful for the decision makers, especially when facing changing environments. In this competition, a test suit about DMMOPs is given, which models the real-world applications. Specifically, this test suit adopts 8 multimodal functions and 8 change modes to construct 24 typical dynamic multimodal optimization problems. Meanwhile, the metric is also given to measure the algorithm performance, which considers the average number of optimal solutions found in all environments. This competition will be very helpful to promote the development of dynamic multimodal optimization algorithms.