 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Autoregressive Evolution for Dynamic Multi-Objective Optimisation
May 22, 2023



Dynamic multi-objective optimisation (DMO) handles optimisation problems with multiple (often conflicting) objectives in varying environments. Such problems pose various challenges to evolutionary algorithms, which have popularly been used to solve complex optimisation problems, due to their dynamic nature and resource restrictions in changing environments. This paper proposes vector autoregressive evolution (VARE) consisting of vector autoregression (VAR) and environment-aware hypermutation to address environmental changes in DMO. VARE builds a VAR model that considers mutual relationship between decision variables to effectively predict the moving solutions in dynamic environments. Additionally, VARE introduces EAH to address the blindness of existing hypermutation strategies in increasing population diversity in dynamic scenarios where predictive approaches are unsuitable. A seamless integration of VAR and EAH in an environment-adaptive manner makes VARE effective to handle a wide range of dynamic environments and competitive with several popular DMO algorithms, as demonstrated in extensive experimental studies. Specially, the proposed algorithm is computationally 50 times faster than two widely-used algorithms (i.e., TrDMOEA and MOEA/D-SVR) while producing significantly better results.
CoLAKE: Contextualized Language and Knowledge Embedding
Oct 01, 2020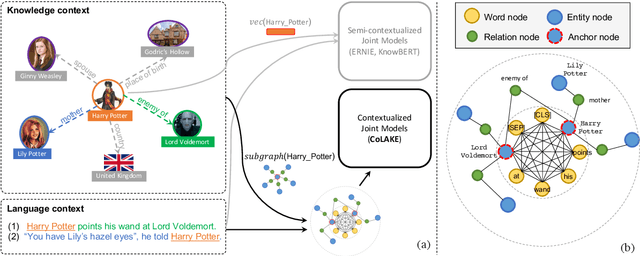


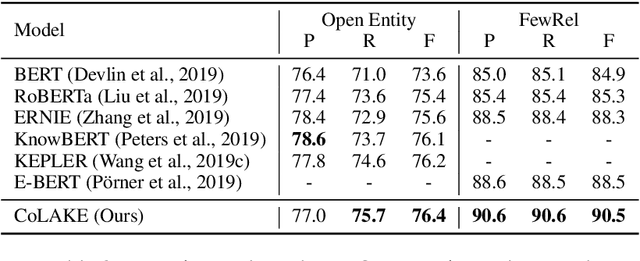
With the emerging branch of incorporating factual knowledge into pre-trained language models such as BERT, most existing models consider shallow, static, and separately pre-trained entity embeddings, which limits the performance gains of these models. Few works explore the potential of deep contextualized knowledge representation when injecting knowledge. In this paper, we propose the Contextualized Language and Knowledge Embedding (CoLAKE), which jointly learns contextualized representation for both language and knowledge with the extended MLM objective. Instead of injecting only entity embeddings, CoLAKE extracts the knowledge context of an entity from large-scale knowledge bases. To handle the heterogeneity of knowledge context and language context, we integrate them in a unified data structure, word-knowledge graph (WK graph). CoLAKE is pre-trained on large-scale WK graphs with the modified Transformer encoder. We conduct experiments on knowledge-driven tasks, knowledge probing tasks, and language understanding tasks. Experimental results show that CoLAKE outperforms previous counterparts on most of the tasks. Besides, CoLAKE achieves surprisingly high performance on our synthetic task called word-knowledge graph completion, which shows the superiority of simultaneously contextualizing language and knowledge representation.