 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Dataset for Financial Education Text Simplification in Spanish
Dec 15, 2023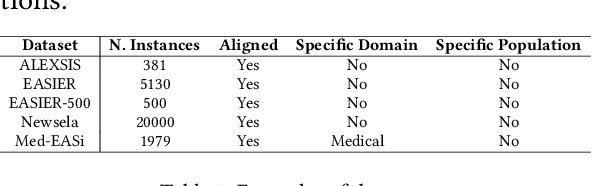
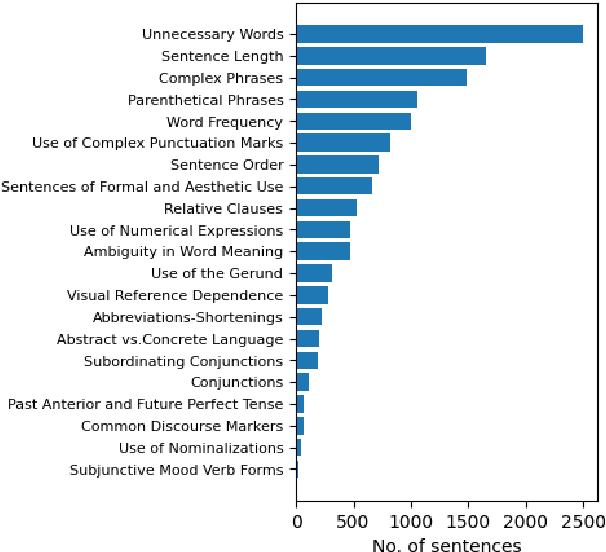
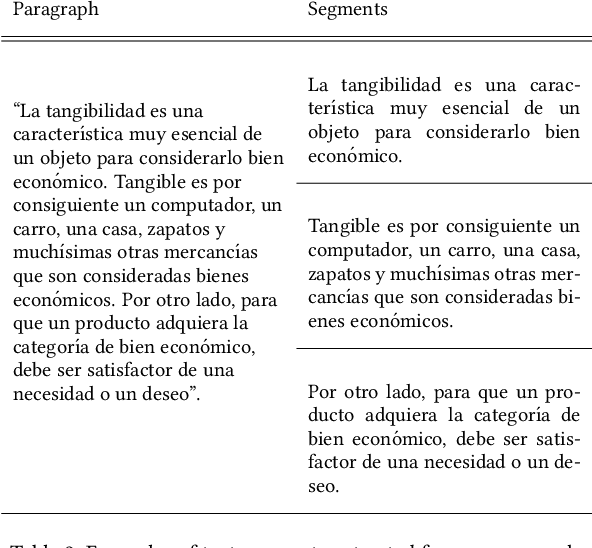
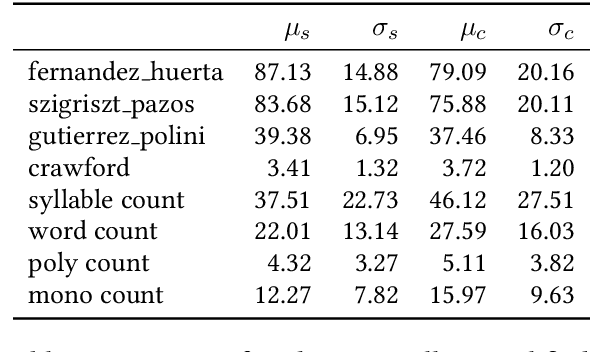
Text simplification, crucial in natural language processing, aims to make texts more comprehensible, particularly for specific groups like visually impaired Spanish speakers, a less-represented language in this field. In Spanish, there are few datasets that can be used to create text simplification systems. Our research has the primary objective to develop a Spanish financial text simplification dataset. We created a dataset with 5,314 complex and simplified sentence pairs using established simplification rules. We also compared our dataset with the simplifications generated from GPT-3, Tuner, and MT5, in order to evaluate the feasibility of data augmentation using these systems. In this manuscript we present the characteristics of our dataset and the findings of the comparisons with other systems. The dataset is available at Hugging face, saul1917/FEINA.
Improving Semi-supervised Deep Learning by using Automatic Thresholding to Deal with Out of Distribution Data for COVID-19 Detection using Chest X-ray Images
Nov 03, 2022
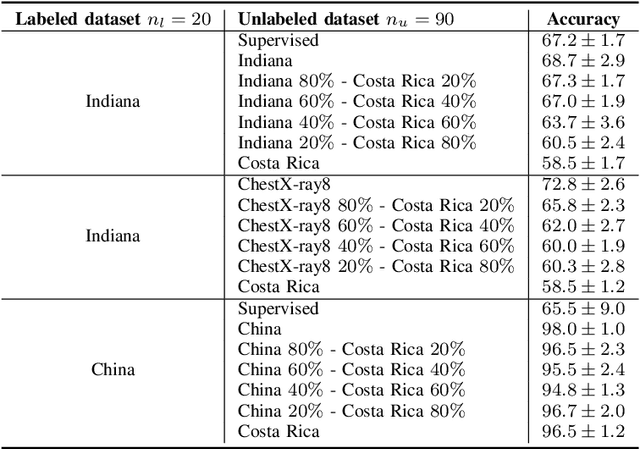
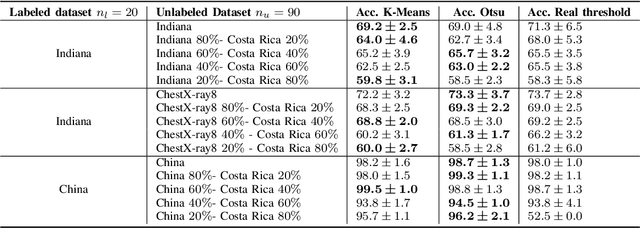
Semi-supervised learning (SSL) leverages both labeled and unlabeled data for training models when the labeled data is limited and the unlabeled data is vast. Frequently, the unlabeled data is more widely available than the labeled data, hence this data is used to improve the level of generalization of a model when the labeled data is scarce. However, in real-world settings unlabeled data might depict a different distribution than the labeled dataset distribution. This is known as distribution mismatch. Such problem generally occurs when the source of unlabeled data is different from the labeled data. For instance, in the medical imaging domain, when training a COVID-19 detector using chest X-ray images, different unlabeled datasets sampled from different hospitals might be used. In this work, we propose an automatic thresholding method to filter out-of-distribution data in the unlabeled dataset. We use the Mahalanobis distance between the labeled and unlabeled datasets using the feature space built by a pre-trained Image-net Feature Extractor (FE) to score each unlabeled observation. We test two simple automatic thresholding methods in the context of training a COVID-19 detector using chest X-ray images. The tested methods provide an automatic manner to define what unlabeled data to preserve when training a semi-supervised deep learning architecture.
Semi-supervised Deep Learning for Image Classification with Distribution Mismatch: A Survey
Mar 10, 2022
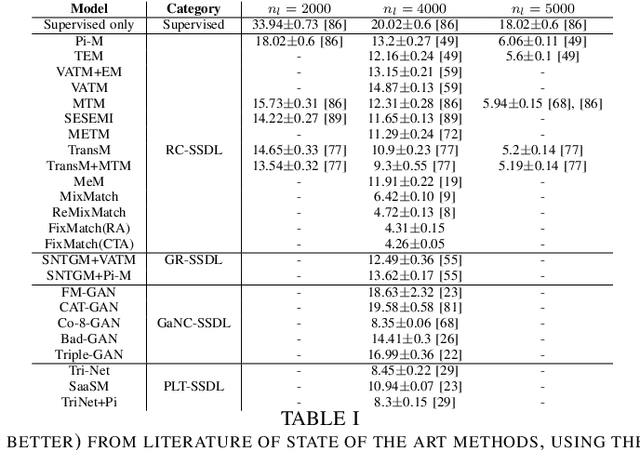
Deep learning methodologies have been employed in several different fields, with an outstanding success in image recognition applications, such as material quality control, medical imaging, autonomous driving, etc. Deep learning models rely on the abundance of labelled observations to train a prospective model. These models are composed of millions of parameters to estimate, increasing the need of more training observations. Frequently it is expensive to gather labelled observations of data, making the usage of deep learning models not ideal, as the model might over-fit data. In a semi-supervised setting, unlabelled data is used to improve the levels of accuracy and generalization of a model with small labelled datasets. Nevertheless, in many situations different unlabelled data sources might be available. This raises the risk of a significant distribution mismatch between the labelled and unlabelled datasets. Such phenomena can cause a considerable performance hit to typical semi-supervised deep learning frameworks, which often assume that both labelled and unlabelled datasets are drawn from similar distributions. Therefore, in this paper we study the latest approaches for semi-supervised deep learning for image recognition. Emphasis is made in semi-supervised deep learning models designed to deal with a distribution mismatch between the labelled and unlabelled datasets. We address open challenges with the aim to encourage the community to tackle them, and overcome the high data demand of traditional deep learning pipelines under real-world usage settings.
Dealing with Distribution Mismatch in Semi-supervised Deep Learning for Covid-19 Detection Using Chest X-ray Images: A Novel Approach Using Feature Densities
Aug 17, 2021

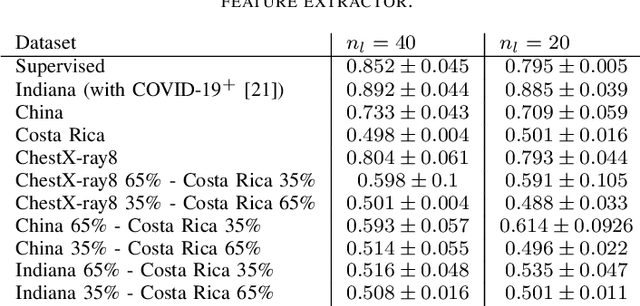
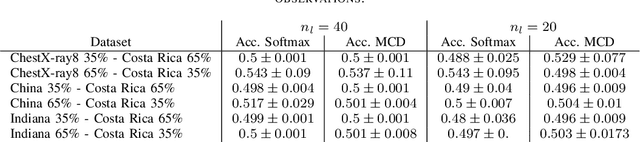
In the context of the global coronavirus pandemic, different deep learning solutions for infected subject detection using chest X-ray images have been proposed. However, deep learning models usually need large labelled datasets to be effective. Semi-supervised deep learning is an attractive alternative, where unlabelled data is leveraged to improve the overall model's accuracy. However, in real-world usage settings, an unlabelled dataset might present a different distribution than the labelled dataset (i.e. the labelled dataset was sampled from a target clinic and the unlabelled dataset from a source clinic). This results in a distribution mismatch between the unlabelled and labelled datasets. In this work, we assess the impact of the distribution mismatch between the labelled and the unlabelled datasets, for a semi-supervised model trained with chest X-ray images, for COVID-19 detection. Under strong distribution mismatch conditions, we found an accuracy hit of almost 30\%, suggesting that the unlabelled dataset distribution has a strong influence in the behaviour of the model. Therefore, we propose a straightforward approach to diminish the impact of such distribution mismatch. Our proposed method uses a density approximation of the feature space. It is built upon the target dataset to filter out the observations in the source unlabelled dataset that might harm the accuracy of the semi-supervised model. It assumes that a small labelled source dataset is available together with a larger source unlabelled dataset. Our proposed method does not require any model training, it is simple and computationally cheap. We compare our proposed method against two popular state of the art out-of-distribution data detectors, which are also cheap and simple to implement. In our tests, our method yielded accuracy gains of up to 32\%, when compared to the previous state of the art methods.
A Real Use Case of Semi-Supervised Learning for Mammogram Classification in a Local Clinic of Costa Rica
Jul 24, 2021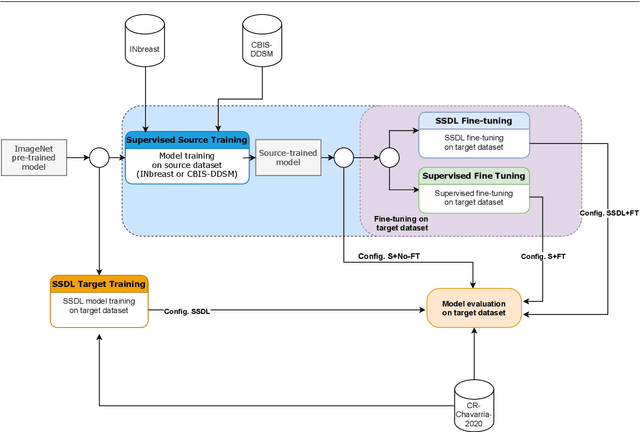
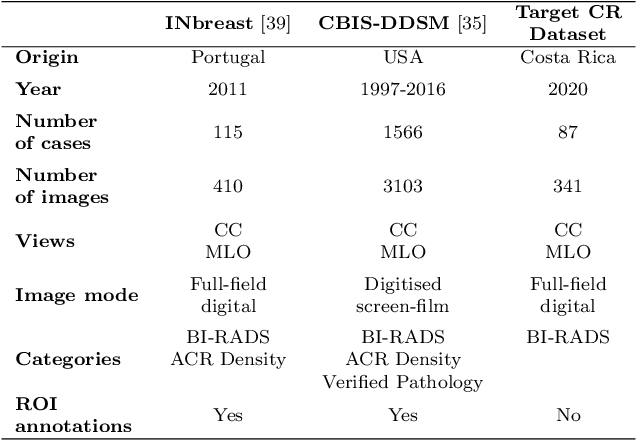
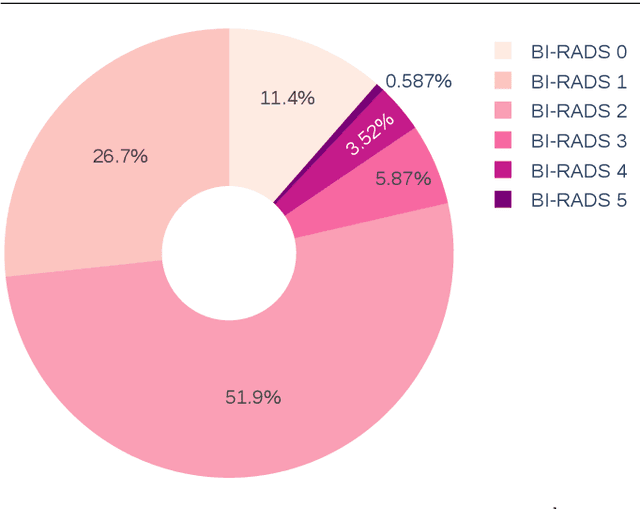
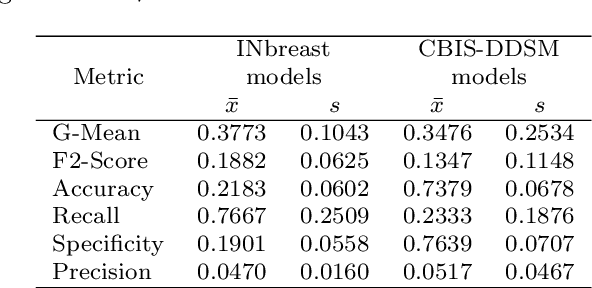
The implementation of deep learning based computer aided diagnosis systems for the classification of mammogram images can help in improving the accuracy, reliability, and cost of diagnosing patients. However, training a deep learning model requires a considerable amount of labeled images, which can be expensive to obtain as time and effort from clinical practitioners is required. A number of publicly available datasets have been built with data from different hospitals and clinics. However, using models trained on these datasets for later work on images sampled from a different hospital or clinic might result in lower performance. This is due to the distribution mismatch of the datasets, which include different patient populations and image acquisition protocols. The scarcity of labeled data can also bring a challenge towards the application of transfer learning with models trained using these source datasets. In this work, a real world scenario is evaluated where a novel target dataset sampled from a private Costa Rican clinic is used, with few labels and heavily imbalanced data. The use of two popular and publicly available datasets (INbreast and CBIS-DDSM) as source data, to train and test the models on the novel target dataset, is evaluated. The use of the semi-supervised deep learning approach known as MixMatch, to leverage the usage of unlabeled data from the target dataset, is proposed and evaluated. In the tests, the performance of models is extensively measured, using different metrics to assess the performance of a classifier under heavy data imbalance conditions. It is shown that the use of semi-supervised deep learning combined with fine-tuning can provide a meaningful advantage when using scarce labeled observations. We make available the novel dataset for the benefit of the community.
Enforcing Morphological Information in Fully Convolutional Networks to Improve Cell Instance Segmentation in Fluorescence Microscopy Images
Jun 10, 2021
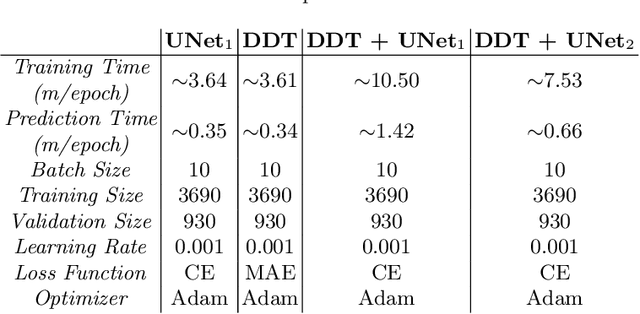
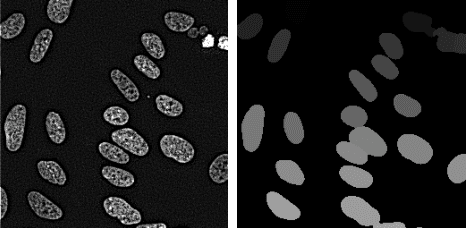
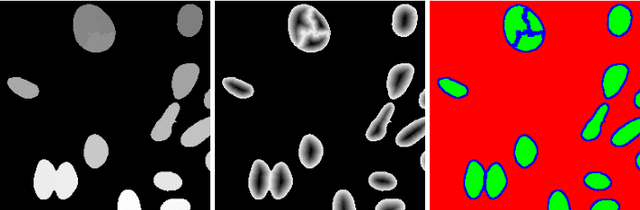
Cell instance segmentation in fluorescence microscopy images is becoming essential for cancer dynamics and prognosis. Data extracted from cancer dynamics allows to understand and accurately model different metabolic processes such as proliferation. This enables customized and more precise cancer treatments. However, accurate cell instance segmentation, necessary for further cell tracking and behavior analysis, is still challenging in scenarios with high cell concentration and overlapping edges. Within this framework, we propose a novel cell instance segmentation approach based on the well-known U-Net architecture. To enforce the learning of morphological information per pixel, a deep distance transformer (DDT) acts as a back-bone model. The DDT output is subsequently used to train a top-model. The following top-models are considered: a three-class (\emph{e.g.,} foreground, background and cell border) U-net, and a watershed transform. The obtained results suggest a performance boost over traditional U-Net architectures. This opens an interesting research line around the idea of injecting morphological information into a fully convolutional model.
More Than Meets The Eye: Semi-supervised Learning Under Non-IID Data
Apr 20, 2021
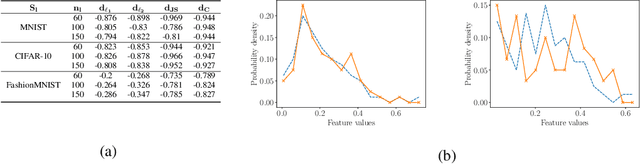

A common heuristic in semi-supervised deep learning (SSDL) is to select unlabelled data based on a notion of semantic similarity to the labelled data. For example, labelled images of numbers should be paired with unlabelled images of numbers instead of, say, unlabelled images of cars. We refer to this practice as semantic data set matching. In this work, we demonstrate the limits of semantic data set matching. We show that it can sometimes even degrade the performance for a state of the art SSDL algorithm. We present and make available a comprehensive simulation sandbox, called non-IID-SSDL, for stress testing an SSDL algorithm under different degrees of distribution mismatch between the labelled and unlabelled data sets. In addition, we demonstrate that simple density based dissimilarity measures in the feature space of a generic classifier offer a promising and more reliable quantitative matching criterion to select unlabelled data before SSDL training.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 20, 2020
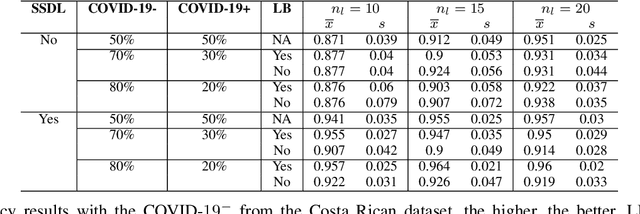
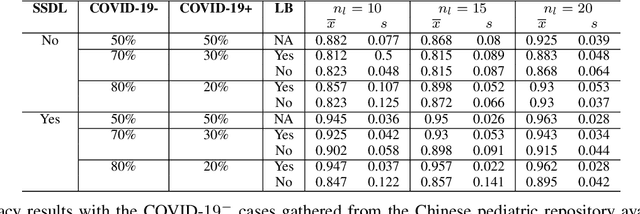
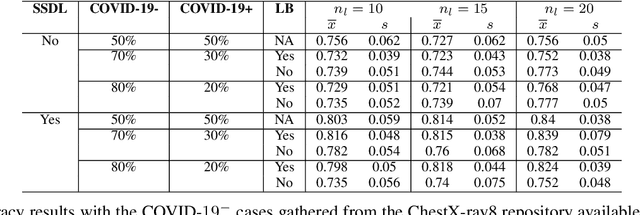
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients
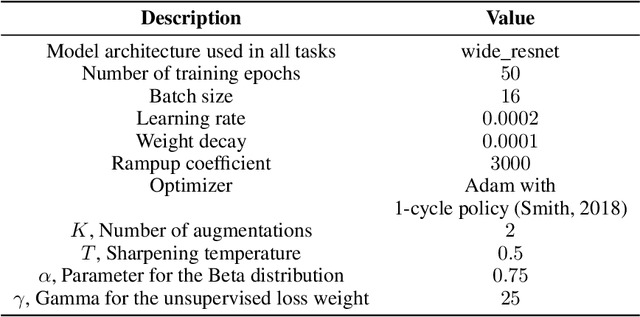
MixMOOD: A systematic approach to class distribution mismatch in semi-supervised learning using deep dataset dissimilarity measures
Jun 14, 2020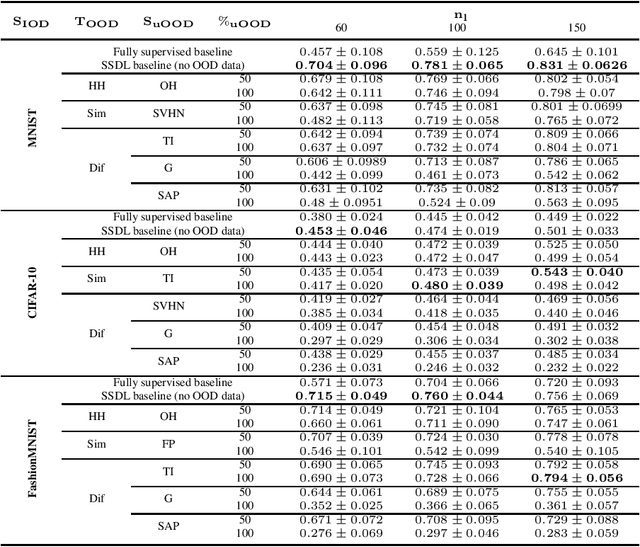
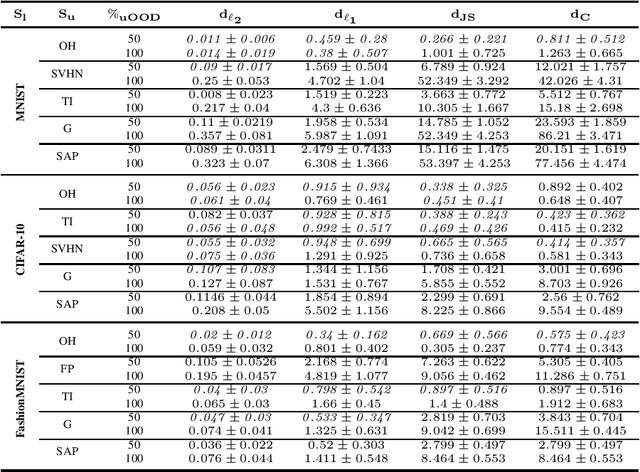
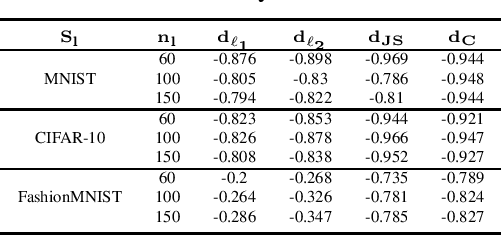
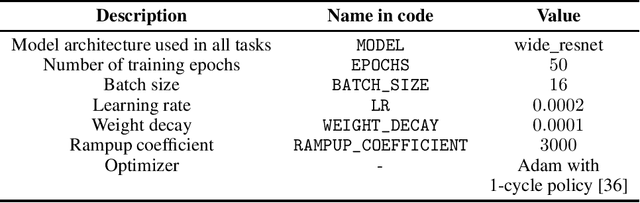
In this work, we propose MixMOOD - a systematic approach to mitigate effect of class distribution mismatch in semi-supervised deep learning (SSDL) with MixMatch. This work is divided into two components: (i) an extensive out of distribution (OOD) ablation test bed for SSDL and (ii) a quantitative unlabelled dataset selection heuristic referred to as MixMOOD. In the first part, we analyze the sensitivity of MixMatch accuracy under 90 different distribution mismatch scenarios across three multi-class classification tasks. These are designed to systematically understand how OOD unlabelled data affects MixMatch performance. In the second part, we propose an efficient and effective method, called deep dataset dissimilarity measures (DeDiMs), to compare labelled and unlabelled datasets. The proposed DeDiMs are quick to evaluate and model agnostic. They use the feature space of a generic Wide-ResNet and can be applied prior to learning. Our test results reveal that supposed semantic similarity between labelled and unlabelled data is not a good heuristic for unlabelled data selection. In contrast, strong correlation between MixMatch accuracy and the proposed DeDiMs allow us to quantitatively rank different unlabelled datasets ante hoc according to expected MixMatch accuracy. This is what we call MixMOOD. Furthermore, we argue that the MixMOOD approach can aid to standardize the evaluation of different semi-supervised learning techniques under real world scenarios involving out of distribution data.