 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADICA: a new dataset for coronary artery disease detection by using invasive coronary angiography
Feb 01, 2024Coronary artery disease (CAD) remains the leading cause of death globally and invasive coronary angiography (ICA) is considered the gold standard of anatomical imaging evaluation when CAD is suspected. However, risk evaluation based on ICA has several limitations, such as visual assessment of stenosis severity, which has significant interobserver variability. This motivates to development of a lesion classification system that can support specialists in their clinical procedures. Although deep learning classification methods are well-developed in other areas of medical imaging, ICA image classification is still at an early stage. One of the most important reasons is the lack of available and high-quality open-access datasets. In this paper, we reported a new annotated ICA images dataset, CADICA, to provide the research community with a comprehensive and rigorous dataset of coronary angiography consisting of a set of acquired patient videos and associated disease-related metadata. This dataset can be used by clinicians to train their skills in angiographic assessment of CAD severity and by computer scientists to create computer-aided diagnostic systems to help in such assessment. In addition, baseline classification methods are proposed and analyzed, validating the functionality of CADICA and giving the scientific community a starting point to improve CAD detection.
Enforcing Morphological Information in Fully Convolutional Networks to Improve Cell Instance Segmentation in Fluorescence Microscopy Images
Jun 10, 2021
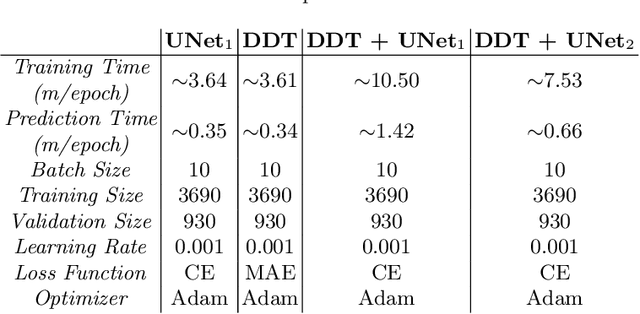
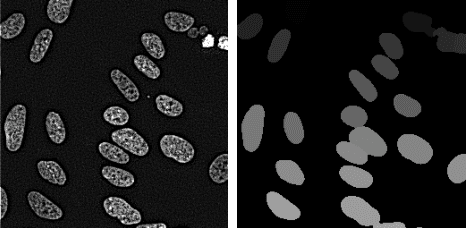
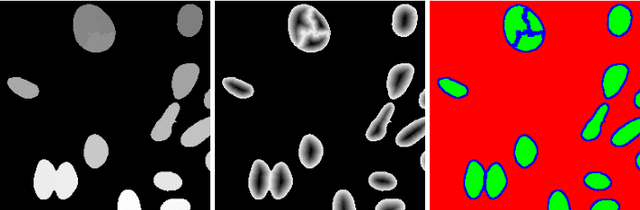
Cell instance segmentation in fluorescence microscopy images is becoming essential for cancer dynamics and prognosis. Data extracted from cancer dynamics allows to understand and accurately model different metabolic processes such as proliferation. This enables customized and more precise cancer treatments. However, accurate cell instance segmentation, necessary for further cell tracking and behavior analysis, is still challenging in scenarios with high cell concentration and overlapping edges. Within this framework, we propose a novel cell instance segmentation approach based on the well-known U-Net architecture. To enforce the learning of morphological information per pixel, a deep distance transformer (DDT) acts as a back-bone model. The DDT output is subsequently used to train a top-model. The following top-models are considered: a three-class (\emph{e.g.,} foreground, background and cell border) U-net, and a watershed transform. The obtained results suggest a performance boost over traditional U-Net architectures. This opens an interesting research line around the idea of injecting morphological information into a fully convolutional model.
Correcting Data Imbalance for Semi-Supervised Covid-19 Detection Using X-ray Chest Images
Aug 20, 2020
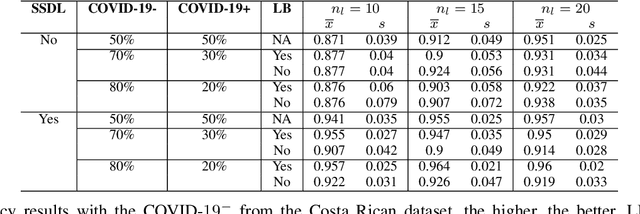
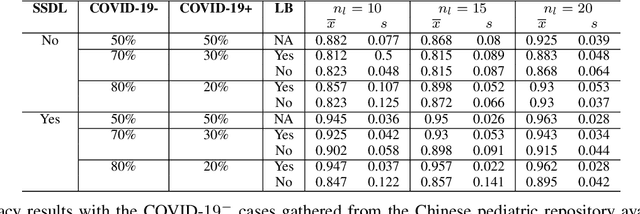
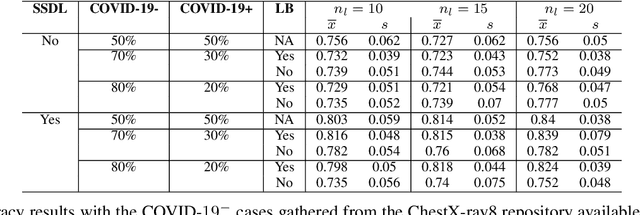
The Corona Virus (COVID-19) is an internationalpandemic that has quickly propagated throughout the world. The application of deep learning for image classification of chest X-ray images of Covid-19 patients, could become a novel pre-diagnostic detection methodology. However, deep learning architectures require large labelled datasets. This is often a limitation when the subject of research is relatively new as in the case of the virus outbreak, where dealing with small labelled datasets is a challenge. Moreover, in the context of a new highly infectious disease, the datasets are also highly imbalanced,with few observations from positive cases of the new disease. In this work we evaluate the performance of the semi-supervised deep learning architecture known as MixMatch using a very limited number of labelled observations and highly imbalanced labelled dataset. We propose a simple approach for correcting data imbalance, re-weight each observationin the loss function, giving a higher weight to the observationscorresponding to the under-represented class. For unlabelled observations, we propose the usage of the pseudo and augmentedlabels calculated by MixMatch to choose the appropriate weight. The MixMatch method combined with the proposed pseudo-label based balance correction improved classification accuracy by up to 10%, with respect to the non balanced MixMatch algorithm, with statistical significance. We tested our proposed approach with several available datasets using 10, 15 and 20 labelledobservations. Additionally, a new dataset is included among thetested datasets, composed of chest X-ray images of Costa Rican adult patients
Radial basis function kernel optimization for Support Vector Machine classifiers
Jul 16, 2020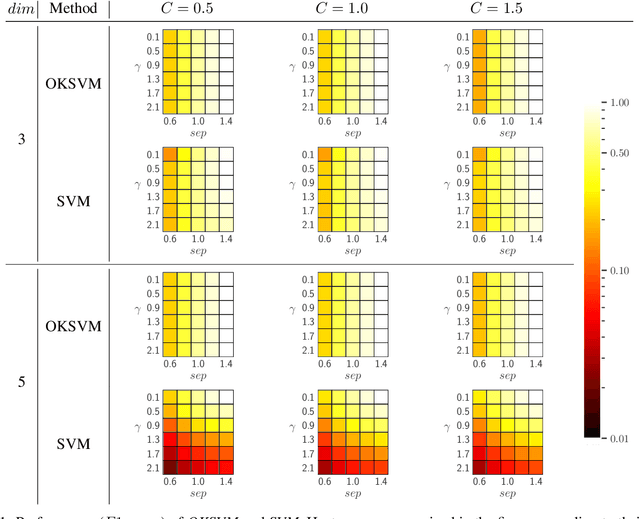
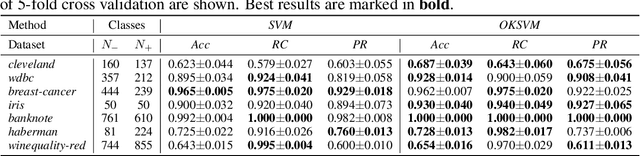

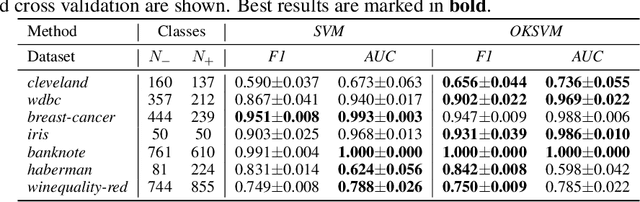
Support Vector Machines (SVMs) are still one of the most popular and precise classifiers. The Radial Basis Function (RBF) kernel has been used in SVMs to separate among classes with considerable success. However, there is an intrinsic dependence on the initial value of the kernel hyperparameter. In this work, we propose OKSVM, an algorithm that automatically learns the RBF kernel hyperparameter and adjusts the SVM weights simultaneously. The proposed optimization technique is based on a gradient descent method. We analyze the performance of our approach with respect to the classical SVM for classification on synthetic and real data. Experimental results show that OKSVM performs better irrespective of the initial values of the RBF hyperparameter.
MixMOOD: A systematic approach to class distribution mismatch in semi-supervised learning using deep dataset dissimilarity measures
Jun 14, 2020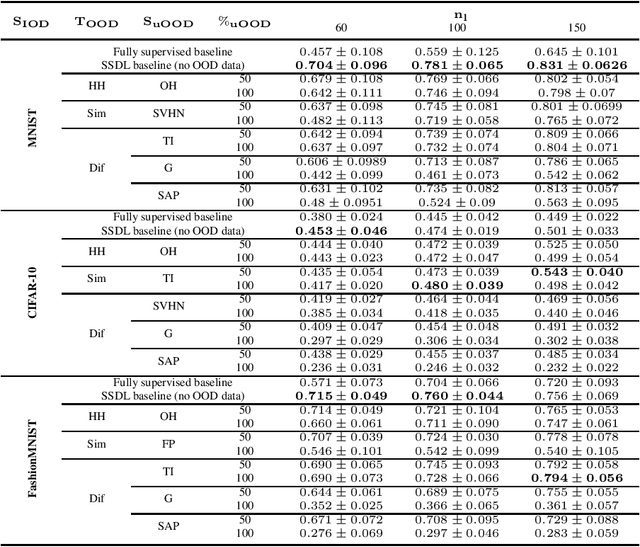
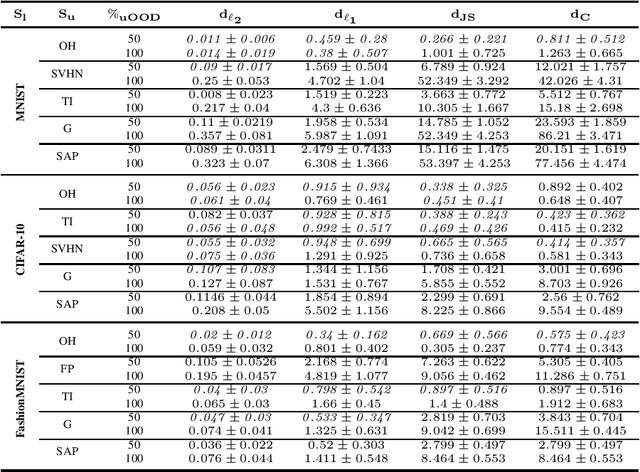
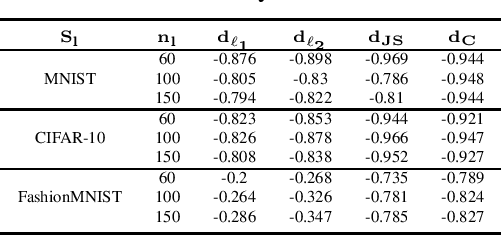
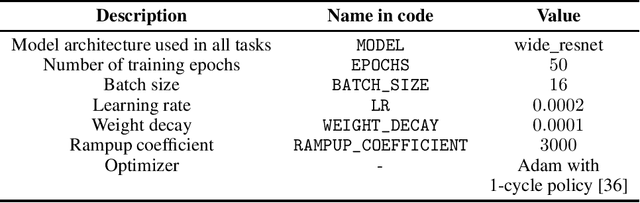
In this work, we propose MixMOOD - a systematic approach to mitigate effect of class distribution mismatch in semi-supervised deep learning (SSDL) with MixMatch. This work is divided into two components: (i) an extensive out of distribution (OOD) ablation test bed for SSDL and (ii) a quantitative unlabelled dataset selection heuristic referred to as MixMOOD. In the first part, we analyze the sensitivity of MixMatch accuracy under 90 different distribution mismatch scenarios across three multi-class classification tasks. These are designed to systematically understand how OOD unlabelled data affects MixMatch performance. In the second part, we propose an efficient and effective method, called deep dataset dissimilarity measures (DeDiMs), to compare labelled and unlabelled datasets. The proposed DeDiMs are quick to evaluate and model agnostic. They use the feature space of a generic Wide-ResNet and can be applied prior to learning. Our test results reveal that supposed semantic similarity between labelled and unlabelled data is not a good heuristic for unlabelled data selection. In contrast, strong correlation between MixMatch accuracy and the proposed DeDiMs allow us to quantitatively rank different unlabelled datasets ante hoc according to expected MixMatch accuracy. This is what we call MixMOOD. Furthermore, we argue that the MixMOOD approach can aid to standardize the evaluation of different semi-supervised learning techniques under real world scenarios involving out of distribution data.