 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Dataset for Financial Education Text Simplification in Spanish
Dec 15, 2023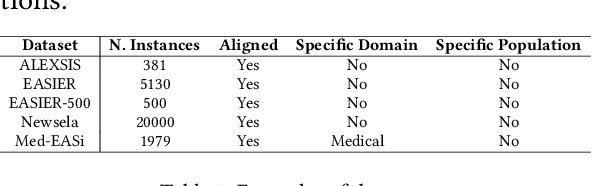
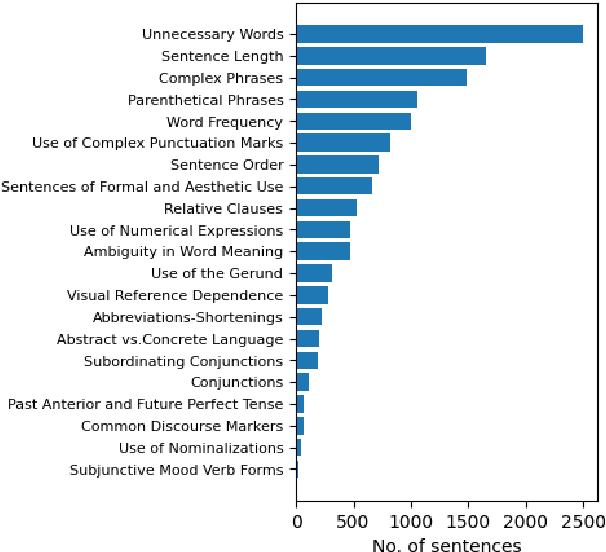
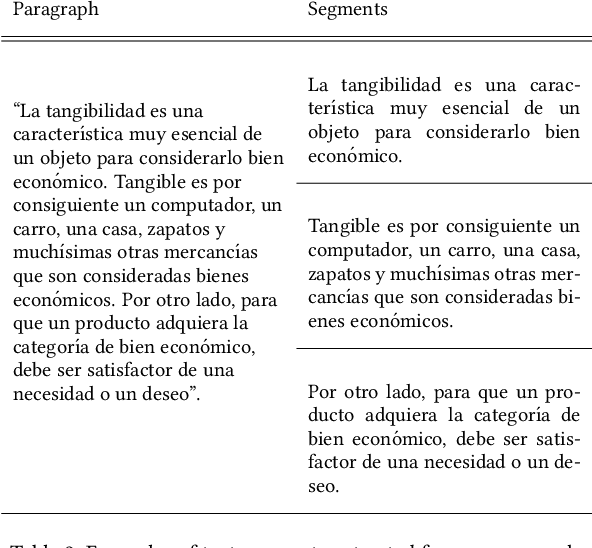
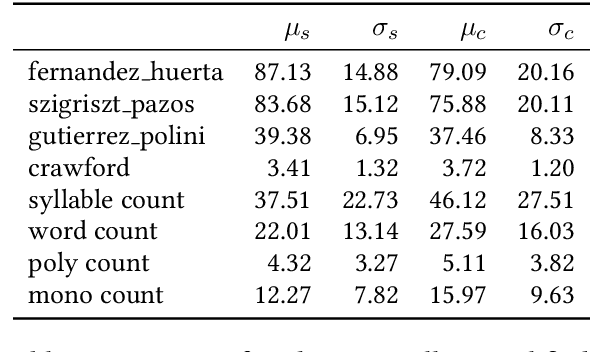
Text simplification, crucial in natural language processing, aims to make texts more comprehensible, particularly for specific groups like visually impaired Spanish speakers, a less-represented language in this field. In Spanish, there are few datasets that can be used to create text simplification systems. Our research has the primary objective to develop a Spanish financial text simplification dataset. We created a dataset with 5,314 complex and simplified sentence pairs using established simplification rules. We also compared our dataset with the simplifications generated from GPT-3, Tuner, and MT5, in order to evaluate the feasibility of data augmentation using these systems. In this manuscript we present the characteristics of our dataset and the findings of the comparisons with other systems. The dataset is available at Hugging face, saul1917/FEINA.