 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evolutionary Network Architecture Search Framework with Adaptive Multimodal Fusion for Hand Gesture Recognition
Mar 27, 2024Hand gesture recognition (HGR) based on multimodal data has attracted considerable attention owing to its great potential in applications. Various manually designed multimodal deep networks have performed well in multimodal HGR (MHGR), but most of existing algorithms require a lot of expert experience and time-consuming manual trials. To address these issues, we propose an evolutionary network architecture search framework with the adaptive multimodel fusion (AMF-ENAS). Specifically, we design an encoding space that simultaneously considers fusion positions and ratios of the multimodal data, allowing for the automatic construction of multimodal networks with different architectures through decoding. Additionally, we consider three input streams corresponding to intra-modal surface electromyography (sEMG), intra-modal accelerometer (ACC), and inter-modal sEMG-ACC. To automatically adapt to various datasets, the ENAS framework is designed to automatically search a MHGR network with appropriate fusion positions and ratios. To the best of our knowledge, this is the first time that ENAS has been utilized in MHGR to tackle issues related to the fusion position and ratio of multimodal data. Experimental results demonstrate that AMF-ENAS achieves state-of-the-art performance on the Ninapro DB2, DB3, and DB7 datasets.
Design-Technology Co-Optimization for NVM-based Neuromorphic Processing Elements
Mar 10, 2022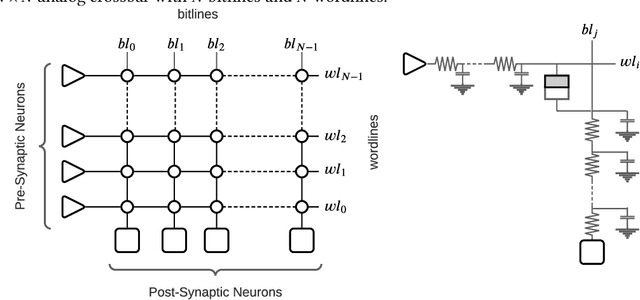
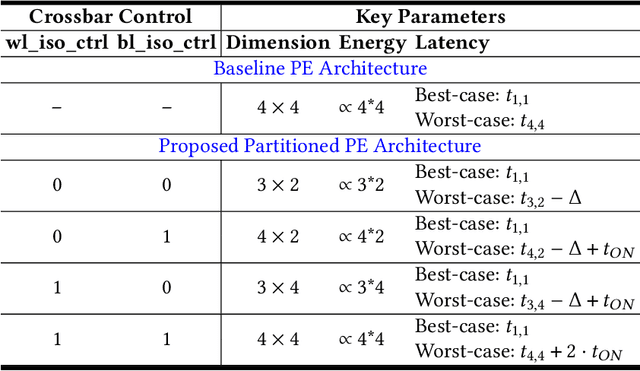
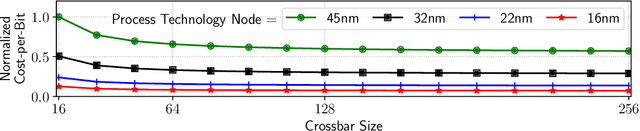
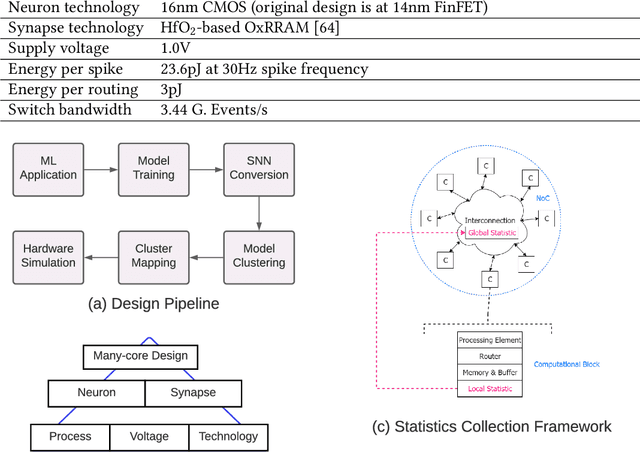
Neuromorphic hardware platforms can significantly lower the energy overhead of a machine learning inference task. We present a design-technology tradeoff analysis to implement such inference tasks on the processing elements (PEs) of a Non- Volatile Memory (NVM)-based neuromorphic hardware. Through detailed circuit-level simulations at scaled process technology nodes, we show the negative impact of technology scaling on the information-processing latency, which impacts the quality-of-service (QoS) of an embedded ML system. At a finer granularity, the latency inside a PE depends on 1) the delay introduced by parasitic components on its current paths, and 2) the varying delay to sense different resistance states of its NVM cells. Based on these two observations, we make the following three contributions. First, on the technology front, we propose an optimization scheme where the NVM resistance state that takes the longest time to sense is set on current paths having the least delay, and vice versa, reducing the average PE latency, which improves the QoS. Second, on the architecture front, we introduce isolation transistors within each PE to partition it into regions that can be individually power-gated, reducing both latency and energy. Finally, on the system-software front, we propose a mechanism to leverage the proposed technological and architectural enhancements when implementing a machine-learning inference task on neuromorphic PEs of the hardware. Evaluations with a recent neuromorphic hardware architecture show that our proposed design-technology co-optimization approach improves both performance and energy efficiency of machine-learning inference tasks without incurring high cost-per-bit.
On the Mitigation of Read Disturbances in Neuromorphic Inference Hardware
Jan 27, 2022
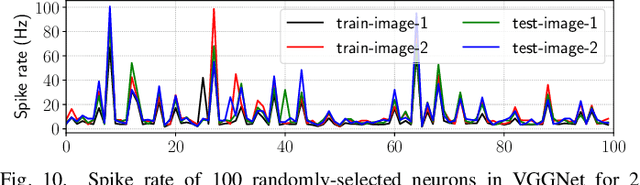
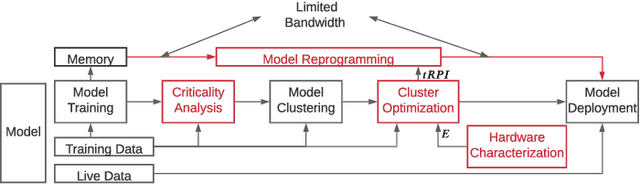
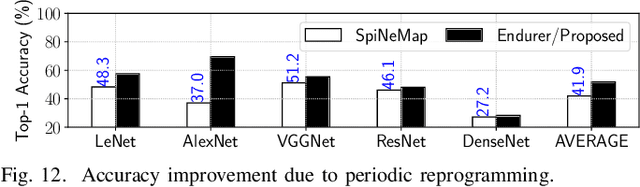
Non-Volatile Memory (NVM) cells are used in neuromorphic hardware to store model parameters, which are programmed as resistance states. NVMs suffer from the read disturb issue, where the programmed resistance state drifts upon repeated access of a cell during inference. Resistance drifts can lower the inference accuracy. To address this, it is necessary to periodically reprogram model parameters (a high overhead operation). We study read disturb failures of an NVM cell. Our analysis show both a strong dependency on model characteristics such as synaptic activation and criticality, and on the voltage used to read resistance states during inference. We propose a system software framework to incorporate such dependencies in programming model parameters on NVM cells of a neuromorphic hardware. Our framework consists of a convex optimization formulation which aims to implement synaptic weights that have more activations and are critical, i.e., those that have high impact on accuracy on NVM cells that are exposed to lower voltages during inference. In this way, we increase the time interval between two consecutive reprogramming of model parameters. We evaluate our system software with many emerging inference models on a neuromorphic hardware simulator and show a significant reduction in the system overhead.
Design Technology Co-Optimization for Neuromorphic Computing
Oct 15, 2021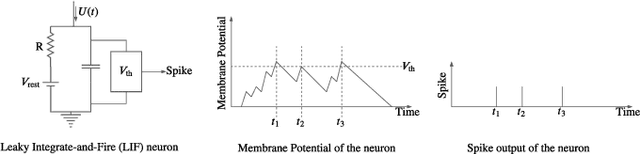
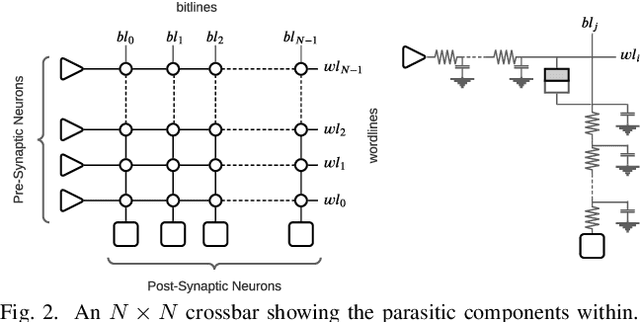
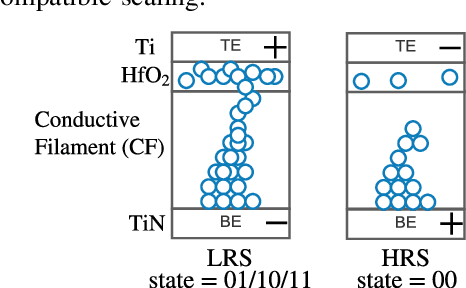
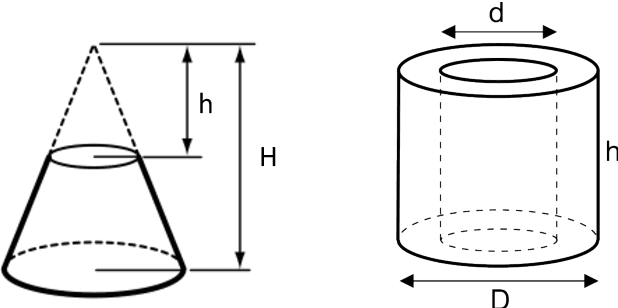
We present a design-technology tradeoff analysis in implementing machine-learning inference on the processing cores of a Non-Volatile Memory (NVM)-based many-core neuromorphic hardware. Through detailed circuit-level simulations for scaled process technology nodes, we show the negative impact of design scaling on read endurance of NVMs, which directly impacts their inference lifetime. At a finer granularity, the inference lifetime of a core depends on 1) the resistance state of synaptic weights programmed on the core (design) and 2) the voltage variation inside the core that is introduced by the parasitic components on current paths (technology). We show that such design and technology characteristics can be incorporated in a design flow to significantly improve the inference lifetime.
A Design Flow for Mapping Spiking Neural Networks to Many-Core Neuromorphic Hardware
Aug 27, 2021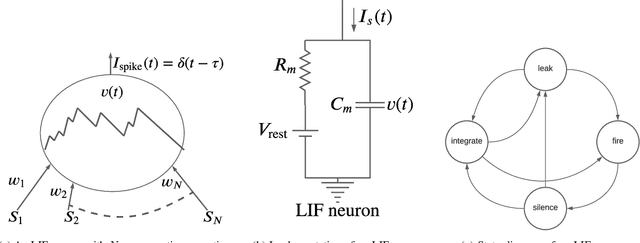
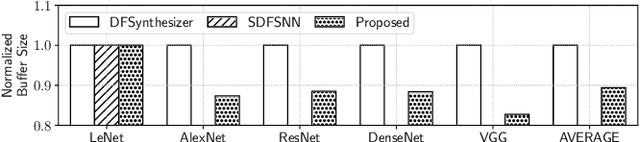
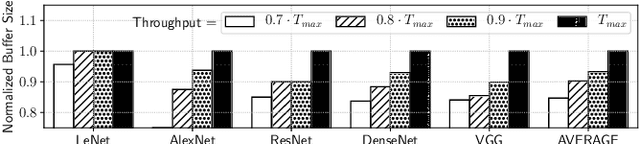
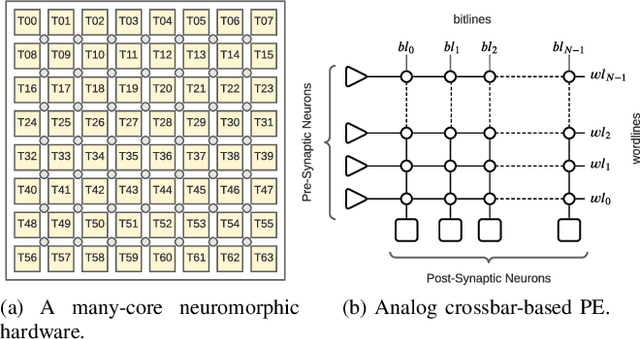
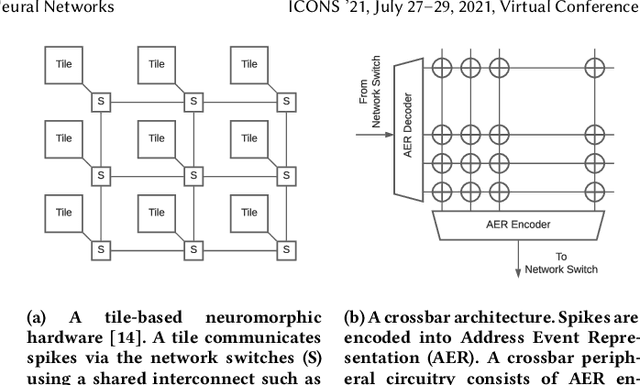
The design of many-core neuromorphic hardware is getting more and more complex as these systems are expected to execute large machine learning models. To deal with the design complexity, a predictable design flow is needed to guarantee real-time performance such as latency and throughput without significantly increasing the buffer requirement of computing cores. Synchronous Data Flow Graphs (SDFGs) are used for predictable mapping of streaming applications to multiprocessor systems. We propose an SDFG-based design flow for mapping spiking neural networks (SNNs) to many-core neuromorphic hardware with the objective of exploring the tradeoff between throughput and buffer size. The proposed design flow integrates an iterative partitioning approach, based on Kernighan-Lin graph partitioning heuristic, creating SNN clusters such that each cluster can be mapped to a core of the hardware. The partitioning approach minimizes the inter-cluster spike communication, which improves latency on the shared interconnect of the hardware. Next, the design flow maps clusters to cores using an instance of the Particle Swarm Optimization (PSO), an evolutionary algorithm, exploring the design space of throughput and buffer size. Pareto optimal mappings are retained from the design flow, allowing system designers to select a Pareto mapping that satisfies throughput and buffer size requirements of the design. We evaluated the design flow using five large-scale convolutional neural network (CNN) models. Results demonstrate 63% higher maximum throughput and 10% lower buffer size requirement compared to state-of-the-art dataflow-based mapping solutions.
DFSynthesizer: Dataflow-based Synthesis of Spiking Neural Networks to Neuromorphic Hardware
Aug 04, 2021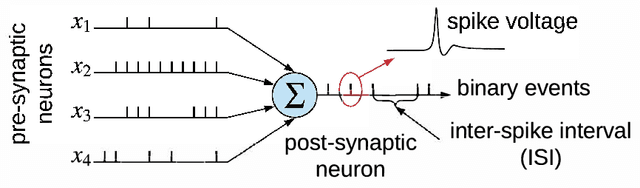

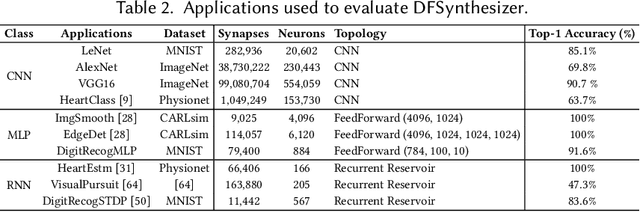
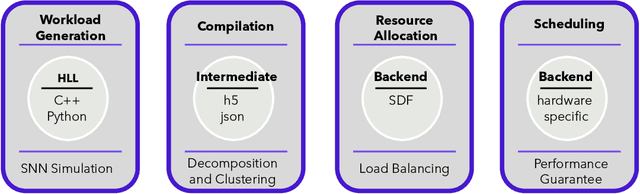
Spiking Neural Networks (SNN) are an emerging computation model, which uses event-driven activation and bio-inspired learning algorithms. SNN-based machine-learning programs are typically executed on tile- based neuromorphic hardware platforms, where each tile consists of a computation unit called crossbar, which maps neurons and synapses of the program. However, synthesizing such programs on an off-the-shelf neuromorphic hardware is challenging. This is because of the inherent resource and latency limitations of the hardware, which impact both model performance, e.g., accuracy, and hardware performance, e.g., throughput. We propose DFSynthesizer, an end-to-end framework for synthesizing SNN-based machine learning programs to neuromorphic hardware. The proposed framework works in four steps. First, it analyzes a machine-learning program and generates SNN workload using representative data. Second, it partitions the SNN workload and generates clusters that fit on crossbars of the target neuromorphic hardware. Third, it exploits the rich semantics of Synchronous Dataflow Graph (SDFG) to represent a clustered SNN program, allowing for performance analysis in terms of key hardware constraints such as number of crossbars, dimension of each crossbar, buffer space on tiles, and tile communication bandwidth. Finally, it uses a novel scheduling algorithm to execute clusters on crossbars of the hardware, guaranteeing hardware performance. We evaluate DFSynthesizer with 10 commonly used machine-learning programs. Our results demonstrate that DFSynthesizer provides much tighter performance guarantee compared to current mapping approaches.
Improving Inference Lifetime of Neuromorphic Systems via Intelligent Synapse Mapping
Jun 16, 2021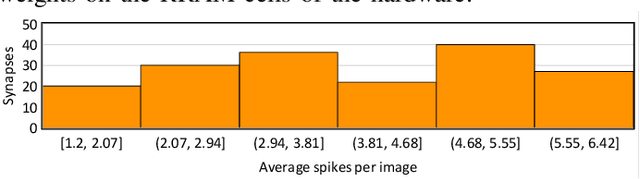
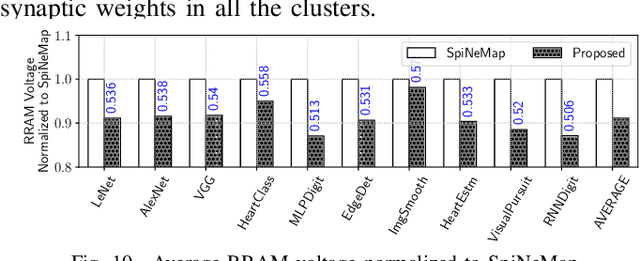
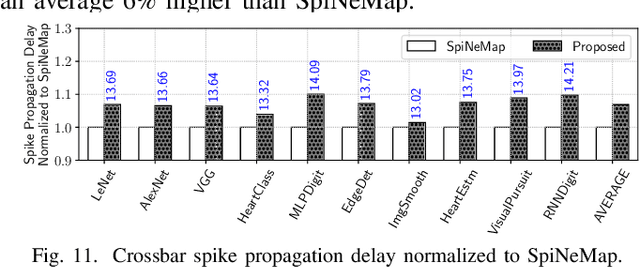
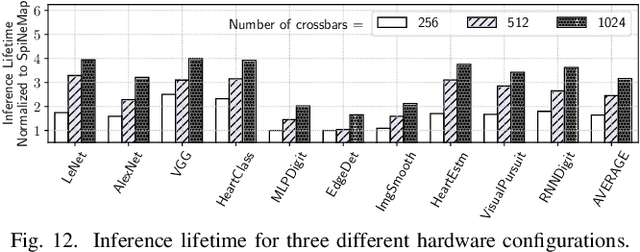
Non-Volatile Memories (NVMs) such as Resistive RAM (RRAM) are used in neuromorphic systems to implement high-density and low-power analog synaptic weights. Unfortunately, an RRAM cell can switch its state after reading its content a certain number of times. Such behavior challenges the integrity and program-once-read-many-times philosophy of implementing machine learning inference on neuromorphic systems, impacting the Quality-of-Service (QoS). Elevated temperatures and frequent usage can significantly shorten the number of times an RRAM cell can be reliably read before it becomes absolutely necessary to reprogram. We propose an architectural solution to extend the read endurance of RRAM-based neuromorphic systems. We make two key contributions. First, we formulate the read endurance of an RRAM cell as a function of the programmed synaptic weight and its activation within a machine learning workload. Second, we propose an intelligent workload mapping strategy incorporating the endurance formulation to place the synapses of a machine learning model onto the RRAM cells of the hardware. The objective is to extend the inference lifetime, defined as the number of times the model can be used to generate output (inference) before the trained weights need to be reprogrammed on the RRAM cells of the system. We evaluate our architectural solution with machine learning workloads on a cycle-accurate simulator of an RRAM-based neuromorphic system. Our results demonstrate a significant increase in inference lifetime with only a minimal performance impact.
Dynamic Reliability Management in Neuromorphic Computing
May 05, 2021
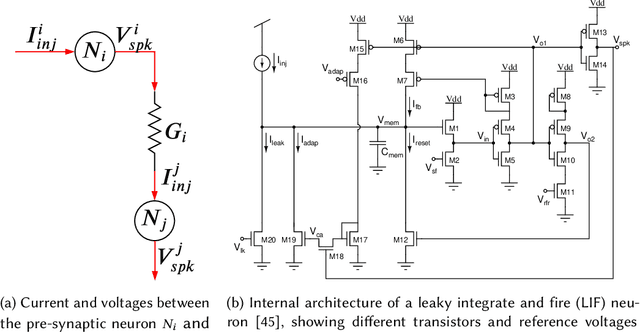
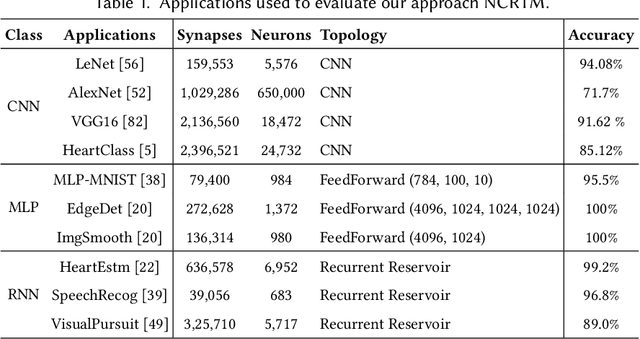

Neuromorphic computing systems uses non-volatile memory (NVM) to implement high-density and low-energy synaptic storage. Elevated voltages and currents needed to operate NVMs cause aging of CMOS-based transistors in each neuron and synapse circuit in the hardware, drifting the transistor's parameters from their nominal values. Aggressive device scaling increases power density and temperature, which accelerates the aging, challenging the reliable operation of neuromorphic systems. Existing reliability-oriented techniques periodically de-stress all neuron and synapse circuits in the hardware at fixed intervals, assuming worst-case operating conditions, without actually tracking their aging at run time. To de-stress these circuits, normal operation must be interrupted, which introduces latency in spike generation and propagation, impacting the inter-spike interval and hence, performance, e.g., accuracy. We propose a new architectural technique to mitigate the aging-related reliability problems in neuromorphic systems, by designing an intelligent run-time manager (NCRTM), which dynamically destresses neuron and synapse circuits in response to the short-term aging in their CMOS transistors during the execution of machine learning workloads, with the objective of meeting a reliability target. NCRTM de-stresses these circuits only when it is absolutely necessary to do so, otherwise reducing the performance impact by scheduling de-stress operations off the critical path. We evaluate NCRTM with state-of-the-art machine learning workloads on a neuromorphic hardware. Our results demonstrate that NCRTM significantly improves the reliability of neuromorphic hardware, with marginal impact on performance.
NeuroXplorer 1.0: An Extensible Framework for Architectural Exploration with Spiking Neural Networks
May 04, 2021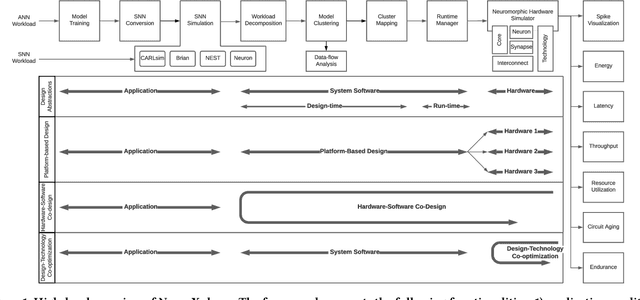
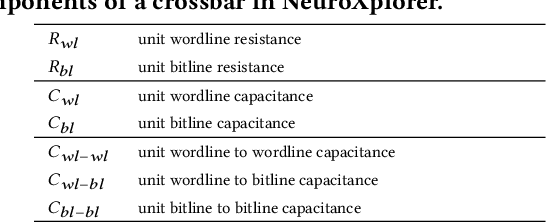

Recently, both industry and academia have proposed many different neuromorphic architectures to execute applications that are designed with Spiking Neural Network (SNN). Consequently, there is a growing need for an extensible simulation framework that can perform architectural explorations with SNNs, including both platform-based design of today's hardware, and hardware-software co-design and design-technology co-optimization of the future. We present NeuroXplorer, a fast and extensible framework that is based on a generalized template for modeling a neuromorphic architecture that can be infused with the specific details of a given hardware and/or technology. NeuroXplorer can perform both low-level cycle-accurate architectural simulations and high-level analysis with data-flow abstractions. NeuroXplorer's optimization engine can incorporate hardware-oriented metrics such as energy, throughput, and latency, as well as SNN-oriented metrics such as inter-spike interval distortion and spike disorder, which directly impact SNN performance. We demonstrate the architectural exploration capabilities of NeuroXplorer through case studies with many state-of-the-art machine learning models.
On the Role of System Software in Energy Management of Neuromorphic Computing
Mar 22, 2021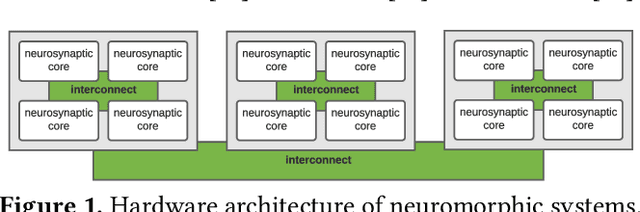
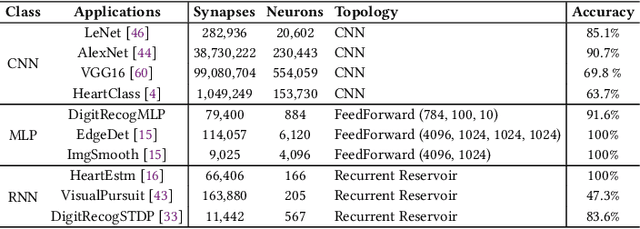


Neuromorphic computing systems such as DYNAPs and Loihi have recently been introduced to the computing community to improve performance and energy efficiency of machine learning programs, especially those that are implemented using Spiking Neural Network (SNN). The role of a system software for neuromorphic systems is to cluster a large machine learning model (e.g., with many neurons and synapses) and map these clusters to the computing resources of the hardware. In this work, we formulate the energy consumption of a neuromorphic hardware, considering the power consumed by neurons and synapses, and the energy consumed in communicating spikes on the interconnect. Based on such formulation, we first evaluate the role of a system software in managing the energy consumption of neuromorphic systems. Next, we formulate a simple heuristic-based mapping approach to place the neurons and synapses onto the computing resources to reduce energy consumption. We evaluate our approach with 10 machine learning applications and demonstrate that the proposed mapping approach leads to a significant reduction of energy consumption of neuromorphic computing systems.