 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFSynthesizer: Dataflow-based Synthesis of Spiking Neural Networks to Neuromorphic Hardware
Aug 04, 2021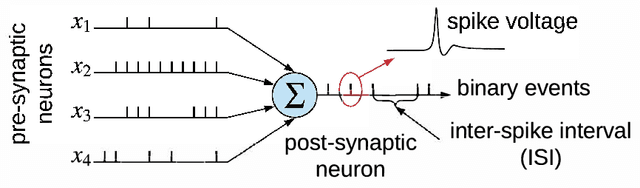

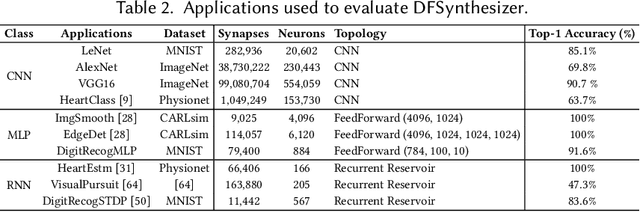
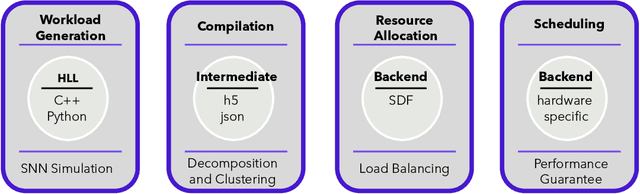
Spiking Neural Networks (SNN) are an emerging computation model, which uses event-driven activation and bio-inspired learning algorithms. SNN-based machine-learning programs are typically executed on tile- based neuromorphic hardware platforms, where each tile consists of a computation unit called crossbar, which maps neurons and synapses of the program. However, synthesizing such programs on an off-the-shelf neuromorphic hardware is challenging. This is because of the inherent resource and latency limitations of the hardware, which impact both model performance, e.g., accuracy, and hardware performance, e.g., throughput. We propose DFSynthesizer, an end-to-end framework for synthesizing SNN-based machine learning programs to neuromorphic hardware. The proposed framework works in four steps. First, it analyzes a machine-learning program and generates SNN workload using representative data. Second, it partitions the SNN workload and generates clusters that fit on crossbars of the target neuromorphic hardware. Third, it exploits the rich semantics of Synchronous Dataflow Graph (SDFG) to represent a clustered SNN program, allowing for performance analysis in terms of key hardware constraints such as number of crossbars, dimension of each crossbar, buffer space on tiles, and tile communication bandwidth. Finally, it uses a novel scheduling algorithm to execute clusters on crossbars of the hardware, guaranteeing hardware performance. We evaluate DFSynthesizer with 10 commonly used machine-learning programs. Our results demonstrate that DFSynthesizer provides much tighter performance guarantee compared to current mapping approaches.
NeuroXplorer 1.0: An Extensible Framework for Architectural Exploration with Spiking Neural Networks
May 04, 2021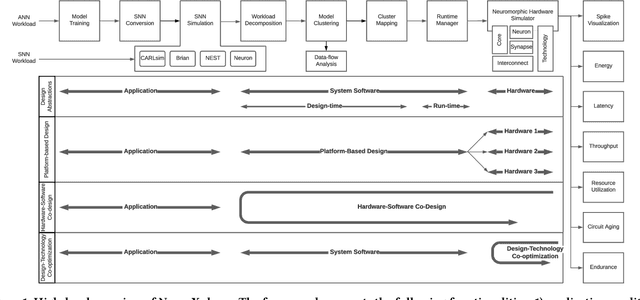
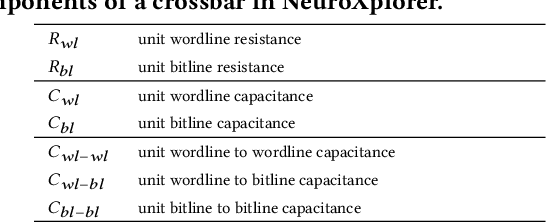
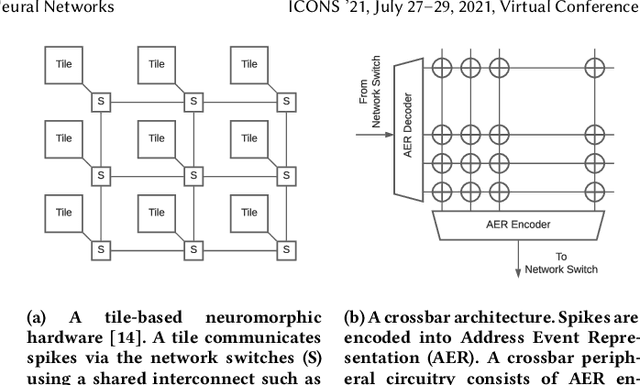

Recently, both industry and academia have proposed many different neuromorphic architectures to execute applications that are designed with Spiking Neural Network (SNN). Consequently, there is a growing need for an extensible simulation framework that can perform architectural explorations with SNNs, including both platform-based design of today's hardware, and hardware-software co-design and design-technology co-optimization of the future. We present NeuroXplorer, a fast and extensible framework that is based on a generalized template for modeling a neuromorphic architecture that can be infused with the specific details of a given hardware and/or technology. NeuroXplorer can perform both low-level cycle-accurate architectural simulations and high-level analysis with data-flow abstractions. NeuroXplorer's optimization engine can incorporate hardware-oriented metrics such as energy, throughput, and latency, as well as SNN-oriented metrics such as inter-spike interval distortion and spike disorder, which directly impact SNN performance. We demonstrate the architectural exploration capabilities of NeuroXplorer through case studies with many state-of-the-art machine learning models.
Enabling Resource-Aware Mapping of Spiking Neural Networks via Spatial Decomposition
Sep 19, 2020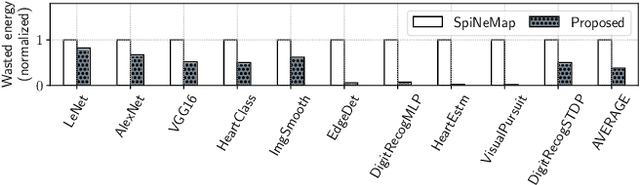
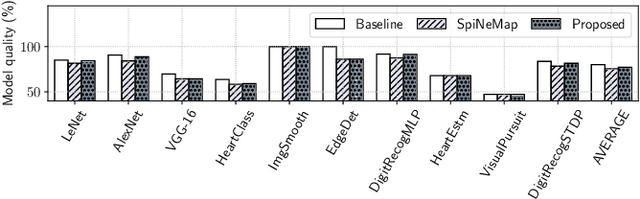
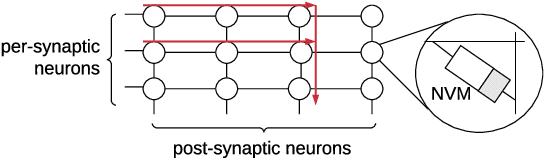
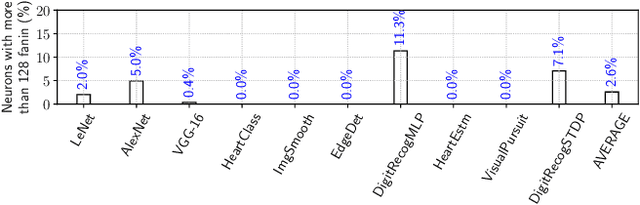
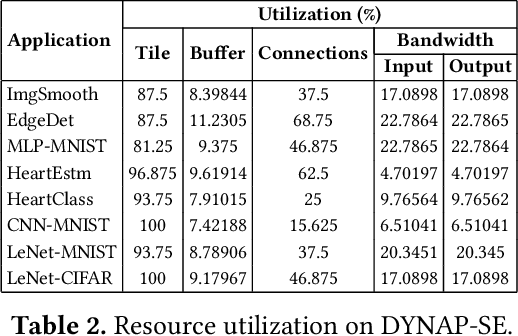
With growing model complexity, mapping Spiking Neural Network (SNN)-based applications to tile-based neuromorphic hardware is becoming increasingly challenging. This is because the synaptic storage resources on a tile, viz. a crossbar, can accommodate only a fixed number of pre-synaptic connections per post-synaptic neuron. For complex SNN models that have many pre-synaptic connections per neuron, some connections may need to be pruned after training to fit onto the tile resources, leading to a loss in model quality, e.g., accuracy. In this work, we propose a novel unrolling technique that decomposes a neuron function with many pre-synaptic connections into a sequence of homogeneous neural units, where each neural unit is a function computation node, with two pre-synaptic connections. This spatial decomposition technique significantly improves crossbar utilization and retains all pre-synaptic connections, resulting in no loss of the model quality derived from connection pruning. We integrate the proposed technique within an existing SNN mapping framework and evaluate it using machine learning applications on the DYNAP-SE state-of-the-art neuromorphic hardware. Our results demonstrate an average 60% lower crossbar requirement, 9x higher synapse utilization, 62% lower wasted energy on the hardware, and between 0.8% and 4.6% increase in model quality.
Compiling Spiking Neural Networks to Neuromorphic Hardware
Apr 07, 2020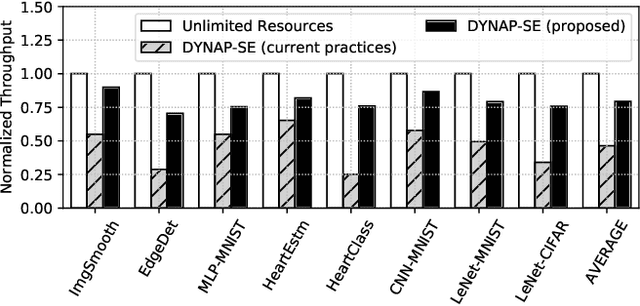
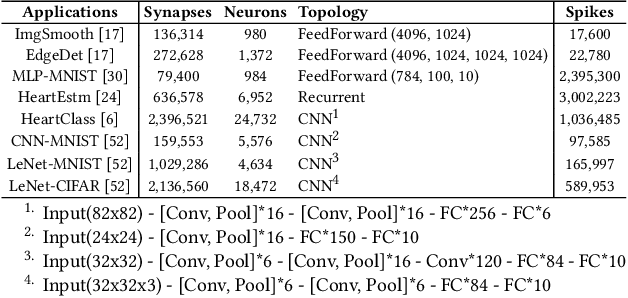
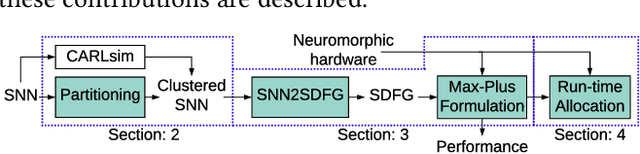
Machine learning applications that are implemented with spike-based computation model, e.g., Spiking Neural Network (SNN), have a great potential to lower the energy consumption when they are executed on a neuromorphic hardware. However, compiling and mapping an SNN to the hardware is challenging, especially when compute and storage resources of the hardware (viz. crossbar) need to be shared among the neurons and synapses of the SNN. We propose an approach to analyze and compile SNNs on a resource-constrained neuromorphic hardware, providing guarantee on key performance metrics such as execution time and throughput. Our approach makes the following three key contributions. First, we propose a greedy technique to partition an SNN into clusters of neurons and synapses such that each cluster can fit on to the resources of a crossbar. Second, we exploit the rich semantics and expressiveness of Synchronous Dataflow Graphs (SDFGs) to represent a clustered SNN and analyze its performance using Max-Plus Algebra, considering the available compute and storage capacities, buffer sizes, and communication bandwidth. Third, we propose a self-timed execution-based fast technique to compile and admit SNN-based applications to a neuromorphic hardware at run-time, adapting dynamically to the available resources on the hardware. We evaluate our approach with standard SNN-based applications and demonstrate a significant performance improvement compared to current practices.