 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling Spiking Neural Networks to Neuromorphic Hardware
Paper and Code
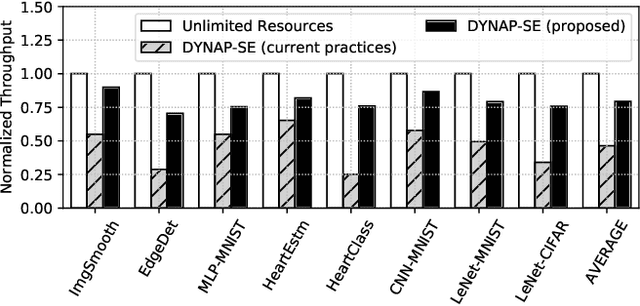
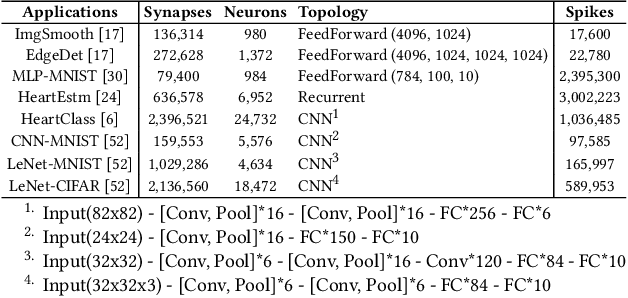
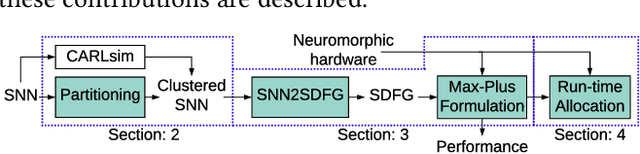
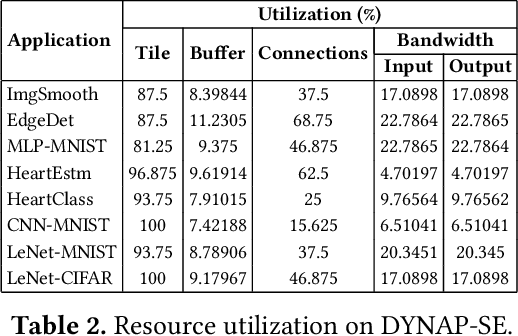
Machine learning applications that are implemented with spike-based computation model, e.g., Spiking Neural Network (SNN), have a great potential to lower the energy consumption when they are executed on a neuromorphic hardware. However, compiling and mapping an SNN to the hardware is challenging, especially when compute and storage resources of the hardware (viz. crossbar) need to be shared among the neurons and synapses of the SNN. We propose an approach to analyze and compile SNNs on a resource-constrained neuromorphic hardware, providing guarantee on key performance metrics such as execution time and throughput. Our approach makes the following three key contributions. First, we propose a greedy technique to partition an SNN into clusters of neurons and synapses such that each cluster can fit on to the resources of a crossbar. Second, we exploit the rich semantics and expressiveness of Synchronous Dataflow Graphs (SDFGs) to represent a clustered SNN and analyze its performance using Max-Plus Algebra, considering the available compute and storage capacities, buffer sizes, and communication bandwidth. Third, we propose a self-timed execution-based fast technique to compile and admit SNN-based applications to a neuromorphic hardware at run-time, adapting dynamically to the available resources on the hardware. We evaluate our approach with standard SNN-based applications and demonstrate a significant performance improvement compared to current practices.