 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Aspect Term Extraction using Spiking Neural Network
Jan 10, 2026Aspect Term Extraction (ATE) identifies aspect terms in review sentences, a key subtask of sentiment analysis. While most existing approaches use energy-intensive deep neural networks (DNNs) for ATE as sequence labeling, this paper proposes a more energy-efficient alternative using Spiking Neural Networks (SNNs). Using sparse activations and event-driven inferences, SNNs capture temporal dependencies between words, making them suitable for ATE. The proposed architecture, SpikeATE, employs ternary spiking neurons and direct spike training fine-tuned with pseudo-gradients. Evaluated on four benchmark SemEval datasets, SpikeATE achieves performance comparable to state-of-the-art DNNs with significantly lower energy consumption. This highlights the use of SNNs as a practical and sustainable choice for ATE tasks.
Wafer2Spike: Spiking Neural Network for Wafer Map Pattern Classification
Nov 29, 2024



In integrated circuit design, the analysis of wafer map patterns is critical to improve yield and detect manufacturing issues. We develop Wafer2Spike, an architecture for wafer map pattern classification using a spiking neural network (SNN), and demonstrate that a well-trained SNN achieves superior performance compared to deep neural network-based solutions. Wafer2Spike achieves an average classification accuracy of 98\% on the WM-811k wafer benchmark dataset. It is also superior to existing approaches for classifying defect patterns that are underrepresented in the original dataset. Wafer2Spike achieves this improved precision with great computational efficiency.
Improving Deformable Image Registration Accuracy through a Hybrid Similarity Metric and CycleGAN Based Auto-Segmentation
Nov 25, 2024



Purpose: Deformable image registration (DIR) is critical in adaptive radiation therapy (ART) to account for anatomical changes. Conventional intensity-based DIR methods often fail when image intensities differ. This study evaluates a hybrid similarity metric combining intensity and structural information, leveraging CycleGAN-based intensity correction and auto-segmentation across three DIR workflows. Methods: A hybrid similarity metric combining a point-to-distance (PD) score and intensity similarity was implemented. Synthetic CT (sCT) images were generated using a 2D CycleGAN model trained on unpaired CT and CBCT images to enhance soft-tissue contrast. DIR workflows compared included: (1) traditional intensity-based (No PD), (2) auto-segmented contours on sCT (CycleGAN PD), and (3) expert manual contours (Expert PD). A 3D U-Net model trained on 56 images and validated on 14 cases segmented the prostate, bladder, and rectum. DIR accuracy was assessed using Dice Similarity Coefficient (DSC), 95% Hausdorff Distance (HD), and fiducial separation. Results: The hybrid metric improved DIR accuracy. For the prostate, DSC increased from 0.61+/-0.18 (No PD) to 0.82+/-0.13 (CycleGAN PD) and 0.89+/-0.05 (Expert PD), with reductions in 95% HD from 11.75 mm to 4.86 mm and 3.27 mm, respectively. Fiducial separation decreased from 8.95 mm to 4.07 mm (CycleGAN PD) and 4.11 mm (Expert PD) (p < 0.05). Improvements were also observed for the bladder and rectum. Conclusion: This study demonstrates that a hybrid similarity metric using CycleGAN-based auto-segmentation improves DIR accuracy, particularly for low-contrast CBCT images. These findings highlight the potential for integrating AI-based image correction and segmentation into ART workflows to enhance precision and streamline clinical processes.
Design-Technology Co-Optimization for NVM-based Neuromorphic Processing Elements
Mar 10, 2022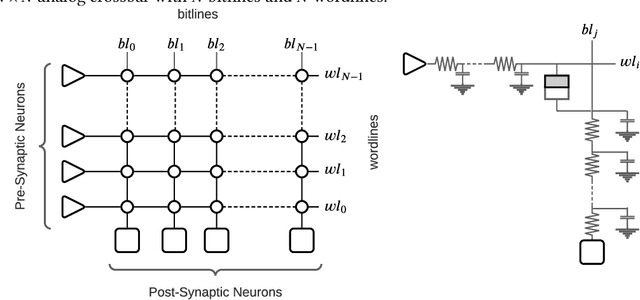
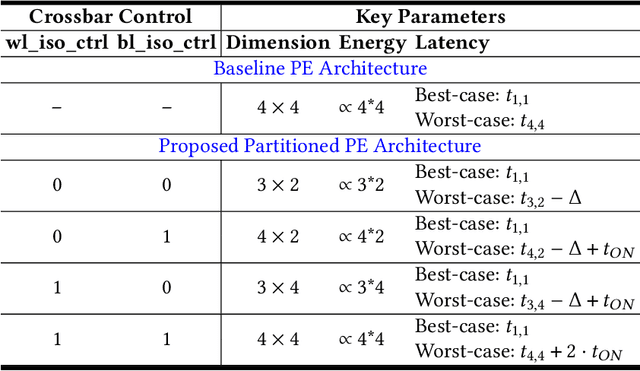
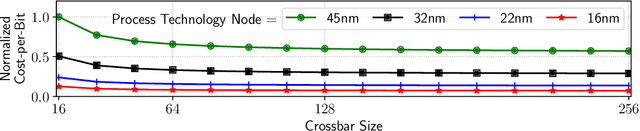
Neuromorphic hardware platforms can significantly lower the energy overhead of a machine learning inference task. We present a design-technology tradeoff analysis to implement such inference tasks on the processing elements (PEs) of a Non- Volatile Memory (NVM)-based neuromorphic hardware. Through detailed circuit-level simulations at scaled process technology nodes, we show the negative impact of technology scaling on the information-processing latency, which impacts the quality-of-service (QoS) of an embedded ML system. At a finer granularity, the latency inside a PE depends on 1) the delay introduced by parasitic components on its current paths, and 2) the varying delay to sense different resistance states of its NVM cells. Based on these two observations, we make the following three contributions. First, on the technology front, we propose an optimization scheme where the NVM resistance state that takes the longest time to sense is set on current paths having the least delay, and vice versa, reducing the average PE latency, which improves the QoS. Second, on the architecture front, we introduce isolation transistors within each PE to partition it into regions that can be individually power-gated, reducing both latency and energy. Finally, on the system-software front, we propose a mechanism to leverage the proposed technological and architectural enhancements when implementing a machine-learning inference task on neuromorphic PEs of the hardware. Evaluations with a recent neuromorphic hardware architecture show that our proposed design-technology co-optimization approach improves both performance and energy efficiency of machine-learning inference tasks without incurring high cost-per-bit.
A Design Flow for Mapping Spiking Neural Networks to Many-Core Neuromorphic Hardware
Aug 27, 2021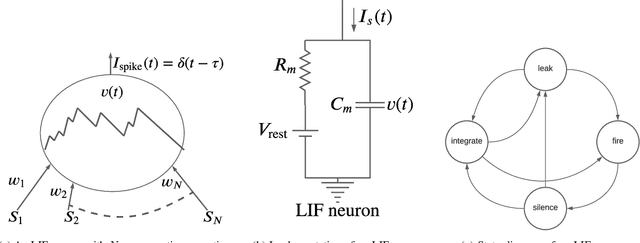
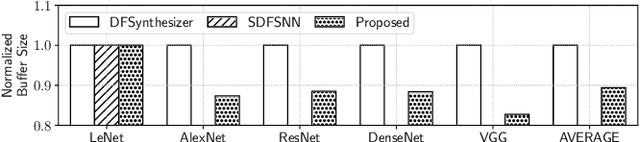
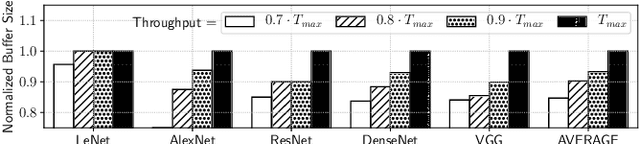
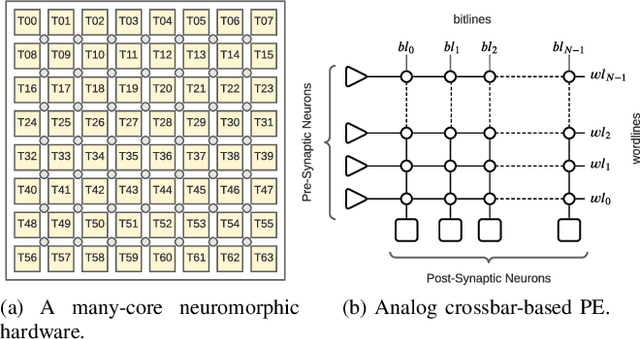
The design of many-core neuromorphic hardware is getting more and more complex as these systems are expected to execute large machine learning models. To deal with the design complexity, a predictable design flow is needed to guarantee real-time performance such as latency and throughput without significantly increasing the buffer requirement of computing cores. Synchronous Data Flow Graphs (SDFGs) are used for predictable mapping of streaming applications to multiprocessor systems. We propose an SDFG-based design flow for mapping spiking neural networks (SNNs) to many-core neuromorphic hardware with the objective of exploring the tradeoff between throughput and buffer size. The proposed design flow integrates an iterative partitioning approach, based on Kernighan-Lin graph partitioning heuristic, creating SNN clusters such that each cluster can be mapped to a core of the hardware. The partitioning approach minimizes the inter-cluster spike communication, which improves latency on the shared interconnect of the hardware. Next, the design flow maps clusters to cores using an instance of the Particle Swarm Optimization (PSO), an evolutionary algorithm, exploring the design space of throughput and buffer size. Pareto optimal mappings are retained from the design flow, allowing system designers to select a Pareto mapping that satisfies throughput and buffer size requirements of the design. We evaluated the design flow using five large-scale convolutional neural network (CNN) models. Results demonstrate 63% higher maximum throughput and 10% lower buffer size requirement compared to state-of-the-art dataflow-based mapping solutions.
DFSynthesizer: Dataflow-based Synthesis of Spiking Neural Networks to Neuromorphic Hardware
Aug 04, 2021

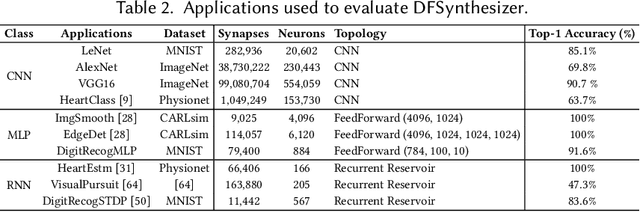
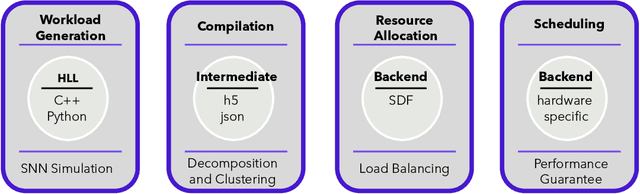
Spiking Neural Networks (SNN) are an emerging computation model, which uses event-driven activation and bio-inspired learning algorithms. SNN-based machine-learning programs are typically executed on tile- based neuromorphic hardware platforms, where each tile consists of a computation unit called crossbar, which maps neurons and synapses of the program. However, synthesizing such programs on an off-the-shelf neuromorphic hardware is challenging. This is because of the inherent resource and latency limitations of the hardware, which impact both model performance, e.g., accuracy, and hardware performance, e.g., throughput. We propose DFSynthesizer, an end-to-end framework for synthesizing SNN-based machine learning programs to neuromorphic hardware. The proposed framework works in four steps. First, it analyzes a machine-learning program and generates SNN workload using representative data. Second, it partitions the SNN workload and generates clusters that fit on crossbars of the target neuromorphic hardware. Third, it exploits the rich semantics of Synchronous Dataflow Graph (SDFG) to represent a clustered SNN program, allowing for performance analysis in terms of key hardware constraints such as number of crossbars, dimension of each crossbar, buffer space on tiles, and tile communication bandwidth. Finally, it uses a novel scheduling algorithm to execute clusters on crossbars of the hardware, guaranteeing hardware performance. We evaluate DFSynthesizer with 10 commonly used machine-learning programs. Our results demonstrate that DFSynthesizer provides much tighter performance guarantee compared to current mapping approaches.
Dynamic Reliability Management in Neuromorphic Computing
May 05, 2021
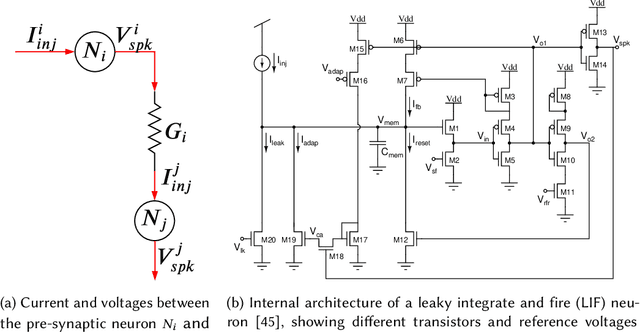
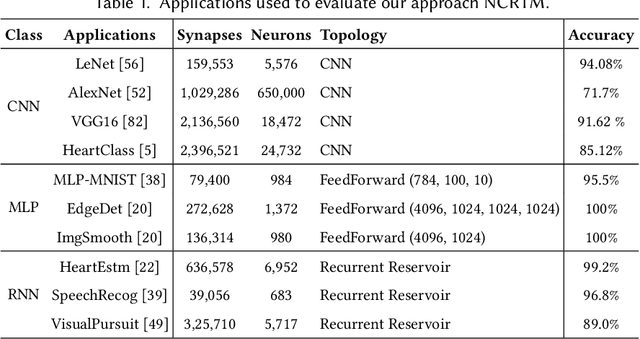

Neuromorphic computing systems uses non-volatile memory (NVM) to implement high-density and low-energy synaptic storage. Elevated voltages and currents needed to operate NVMs cause aging of CMOS-based transistors in each neuron and synapse circuit in the hardware, drifting the transistor's parameters from their nominal values. Aggressive device scaling increases power density and temperature, which accelerates the aging, challenging the reliable operation of neuromorphic systems. Existing reliability-oriented techniques periodically de-stress all neuron and synapse circuits in the hardware at fixed intervals, assuming worst-case operating conditions, without actually tracking their aging at run time. To de-stress these circuits, normal operation must be interrupted, which introduces latency in spike generation and propagation, impacting the inter-spike interval and hence, performance, e.g., accuracy. We propose a new architectural technique to mitigate the aging-related reliability problems in neuromorphic systems, by designing an intelligent run-time manager (NCRTM), which dynamically destresses neuron and synapse circuits in response to the short-term aging in their CMOS transistors during the execution of machine learning workloads, with the objective of meeting a reliability target. NCRTM de-stresses these circuits only when it is absolutely necessary to do so, otherwise reducing the performance impact by scheduling de-stress operations off the critical path. We evaluate NCRTM with state-of-the-art machine learning workloads on a neuromorphic hardware. Our results demonstrate that NCRTM significantly improves the reliability of neuromorphic hardware, with marginal impact on performance.
NeuroXplorer 1.0: An Extensible Framework for Architectural Exploration with Spiking Neural Networks
May 04, 2021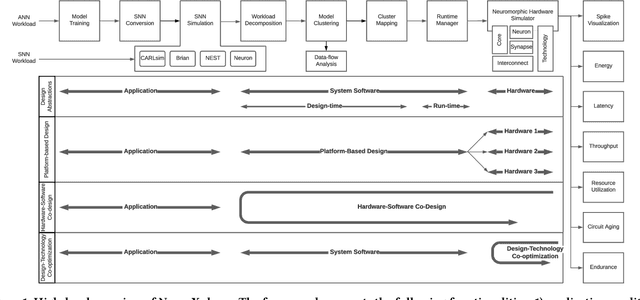
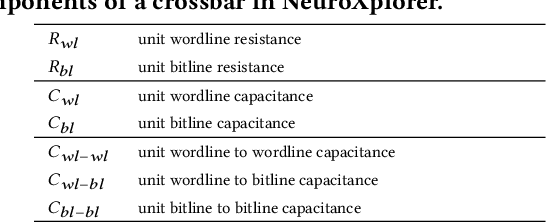
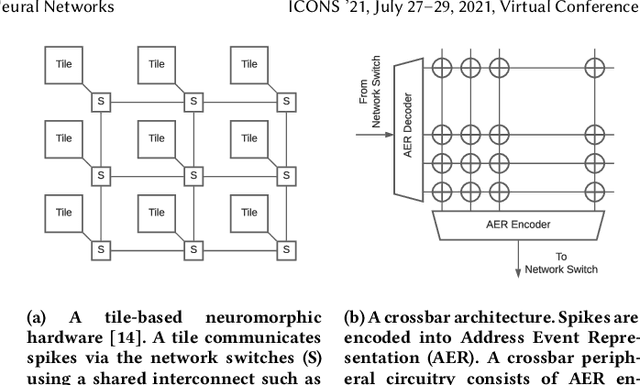

Recently, both industry and academia have proposed many different neuromorphic architectures to execute applications that are designed with Spiking Neural Network (SNN). Consequently, there is a growing need for an extensible simulation framework that can perform architectural explorations with SNNs, including both platform-based design of today's hardware, and hardware-software co-design and design-technology co-optimization of the future. We present NeuroXplorer, a fast and extensible framework that is based on a generalized template for modeling a neuromorphic architecture that can be infused with the specific details of a given hardware and/or technology. NeuroXplorer can perform both low-level cycle-accurate architectural simulations and high-level analysis with data-flow abstractions. NeuroXplorer's optimization engine can incorporate hardware-oriented metrics such as energy, throughput, and latency, as well as SNN-oriented metrics such as inter-spike interval distortion and spike disorder, which directly impact SNN performance. We demonstrate the architectural exploration capabilities of NeuroXplorer through case studies with many state-of-the-art machine learning models.
Endurance-Aware Mapping of Spiking Neural Networks to Neuromorphic Hardware
Mar 09, 2021
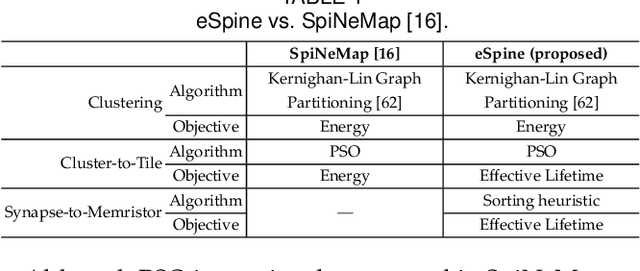
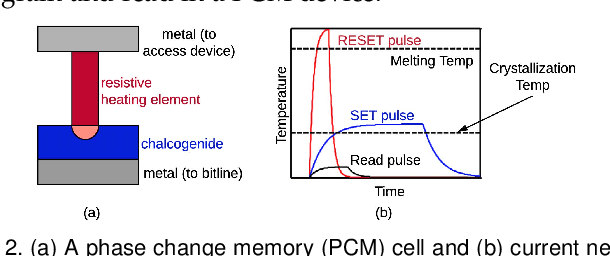
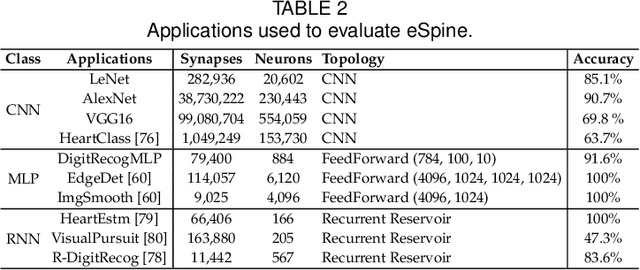
Neuromorphic computing systems are embracing memristors to implement high density and low power synaptic storage as crossbar arrays in hardware. These systems are energy efficient in executing Spiking Neural Networks (SNNs). We observe that long bitlines and wordlines in a memristive crossbar are a major source of parasitic voltage drops, which create current asymmetry. Through circuit simulations, we show the significant endurance variation that results from this asymmetry. Therefore, if the critical memristors (ones with lower endurance) are overutilized, they may lead to a reduction of the crossbar's lifetime. We propose eSpine, a novel technique to improve lifetime by incorporating the endurance variation within each crossbar in mapping machine learning workloads, ensuring that synapses with higher activation are always implemented on memristors with higher endurance, and vice versa. eSpine works in two steps. First, it uses the Kernighan-Lin Graph Partitioning algorithm to partition a workload into clusters of neurons and synapses, where each cluster can fit in a crossbar. Second, it uses an instance of Particle Swarm Optimization (PSO) to map clusters to tiles, where the placement of synapses of a cluster to memristors of a crossbar is performed by analyzing their activation within the workload. We evaluate eSpine for a state-of-the-art neuromorphic hardware model with phase-change memory (PCM)-based memristors. Using 10 SNN workloads, we demonstrate a significant improvement in the effective lifetime.
Enabling Resource-Aware Mapping of Spiking Neural Networks via Spatial Decomposition
Sep 19, 2020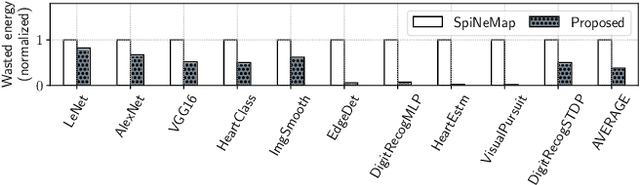
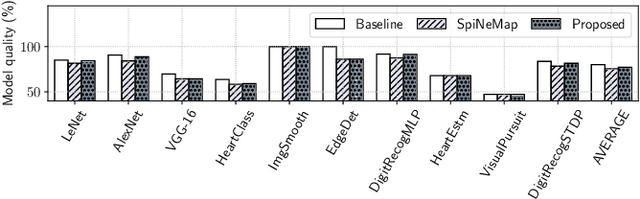
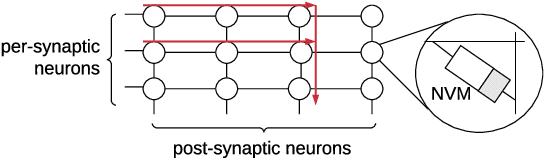
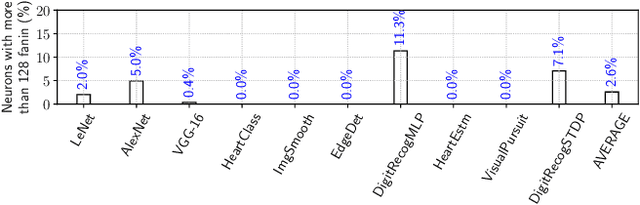
With growing model complexity, mapping Spiking Neural Network (SNN)-based applications to tile-based neuromorphic hardware is becoming increasingly challenging. This is because the synaptic storage resources on a tile, viz. a crossbar, can accommodate only a fixed number of pre-synaptic connections per post-synaptic neuron. For complex SNN models that have many pre-synaptic connections per neuron, some connections may need to be pruned after training to fit onto the tile resources, leading to a loss in model quality, e.g., accuracy. In this work, we propose a novel unrolling technique that decomposes a neuron function with many pre-synaptic connections into a sequence of homogeneous neural units, where each neural unit is a function computation node, with two pre-synaptic connections. This spatial decomposition technique significantly improves crossbar utilization and retains all pre-synaptic connections, resulting in no loss of the model quality derived from connection pruning. We integrate the proposed technique within an existing SNN mapping framework and evaluate it using machine learning applications on the DYNAP-SE state-of-the-art neuromorphic hardware. Our results demonstrate an average 60% lower crossbar requirement, 9x higher synapse utilization, 62% lower wasted energy on the hardware, and between 0.8% and 4.6% increase in model quality.