 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Design Methodology for Fault-Tolerant Computing using Astrocyte Neural Networks
Apr 06, 2022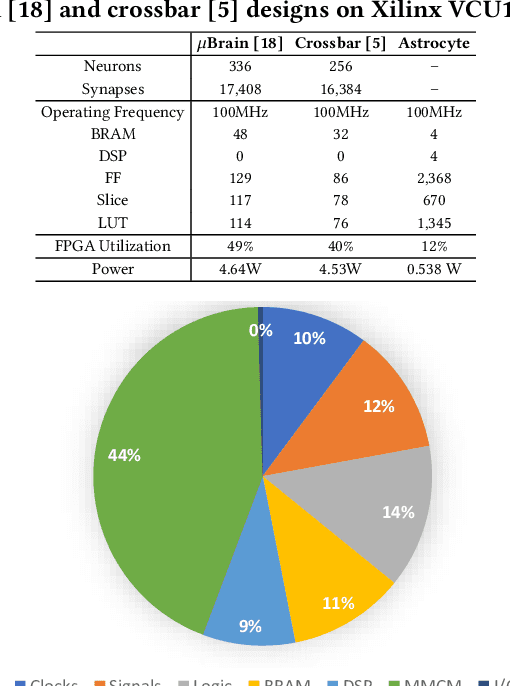
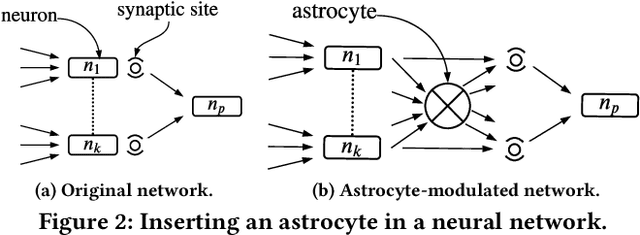
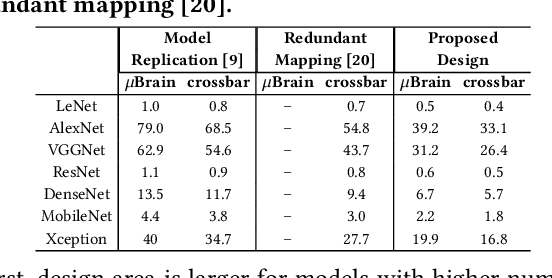
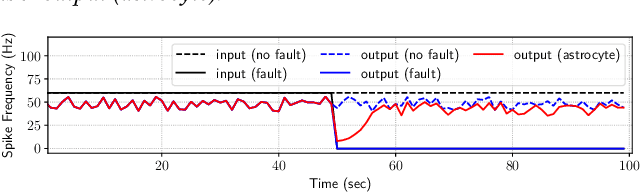
We propose a design methodology to facilitate fault tolerance of deep learning models. First, we implement a many-core fault-tolerant neuromorphic hardware design, where neuron and synapse circuitries in each neuromorphic core are enclosed with astrocyte circuitries, the star-shaped glial cells of the brain that facilitate self-repair by restoring the spike firing frequency of a failed neuron using a closed-loop retrograde feedback signal. Next, we introduce astrocytes in a deep learning model to achieve the required degree of tolerance to hardware faults. Finally, we use a system software to partition the astrocyte-enabled model into clusters and implement them on the proposed fault-tolerant neuromorphic design. We evaluate this design methodology using seven deep learning inference models and show that it is both area and power efficient.
Implementing Spiking Neural Networks on Neuromorphic Architectures: A Review
Feb 17, 2022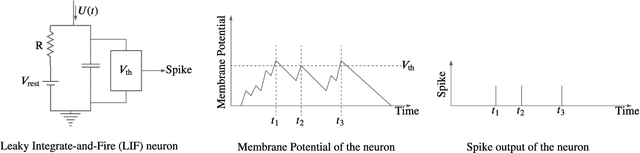


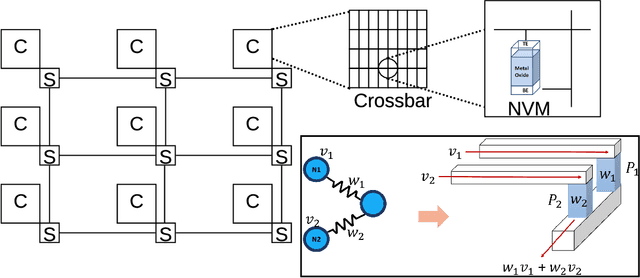
Recently, both industry and academia have proposed several different neuromorphic systems to execute machine learning applications that are designed using Spiking Neural Networks (SNNs). With the growing complexity on design and technology fronts, programming such systems to admit and execute a machine learning application is becoming increasingly challenging. Additionally, neuromorphic systems are required to guarantee real-time performance, consume lower energy, and provide tolerance to logic and memory failures. Consequently, there is a clear need for system software frameworks that can implement machine learning applications on current and emerging neuromorphic systems, and simultaneously address performance, energy, and reliability. Here, we provide a comprehensive overview of such frameworks proposed for both, platform-based design and hardware-software co-design. We highlight challenges and opportunities that the future holds in the area of system software technology for neuromorphic computing.
Design of Many-Core Big Little μBrain for Energy-Efficient Embedded Neuromorphic Computing
Nov 23, 2021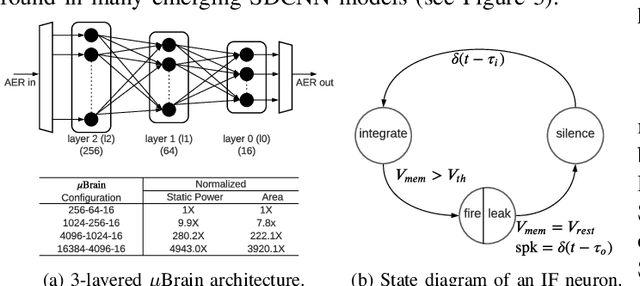
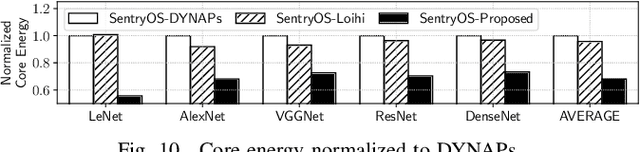
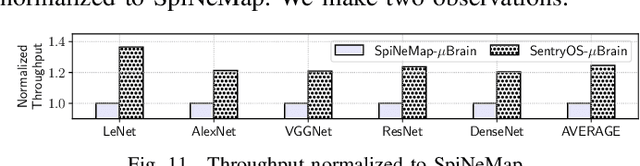
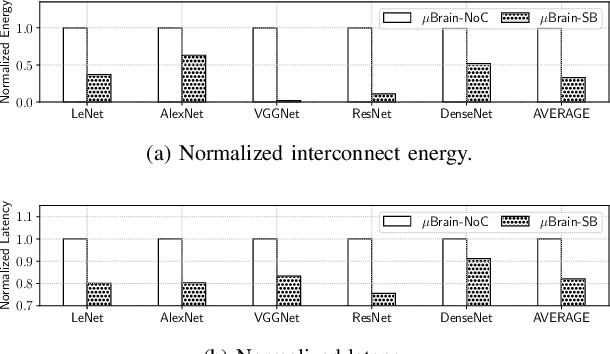
As spiking-based deep learning inference applications are increasing in embedded systems, these systems tend to integrate neuromorphic accelerators such as $\mu$Brain to improve energy efficiency. We propose a $\mu$Brain-based scalable many-core neuromorphic hardware design to accelerate the computations of spiking deep convolutional neural networks (SDCNNs). To increase energy efficiency, cores are designed to be heterogeneous in terms of their neuron and synapse capacity (big cores have higher capacity than the little ones), and they are interconnected using a parallel segmented bus interconnect, which leads to lower latency and energy compared to a traditional mesh-based Network-on-Chip (NoC). We propose a system software framework called SentryOS to map SDCNN inference applications to the proposed design. SentryOS consists of a compiler and a run-time manager. The compiler compiles an SDCNN application into subnetworks by exploiting the internal architecture of big and little $\mu$Brain cores. The run-time manager schedules these sub-networks onto cores and pipeline their execution to improve throughput. We evaluate the proposed big little many-core neuromorphic design and the system software framework with five commonlyused SDCNN inference applications and show that the proposed solution reduces energy (between 37% and 98%), reduces latency (between 9% and 25%), and increases application throughput (between 20% and 36%). We also show that SentryOS can be easily extended for other spiking neuromorphic accelerators.
A Design Flow for Mapping Spiking Neural Networks to Many-Core Neuromorphic Hardware
Aug 27, 2021
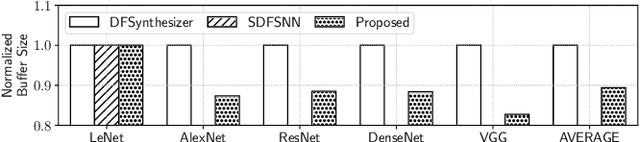
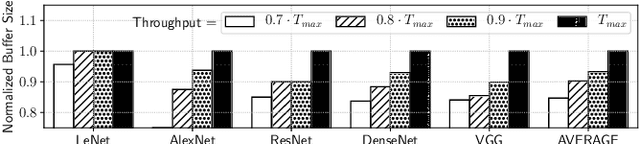
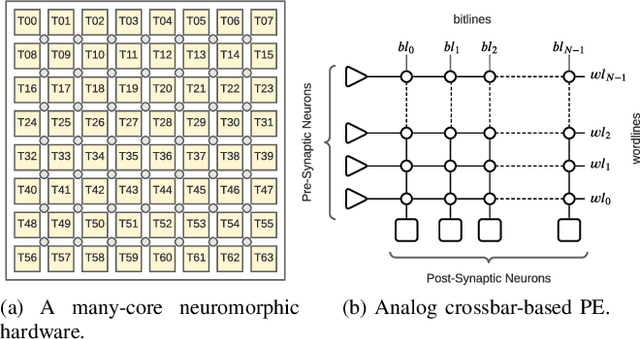
The design of many-core neuromorphic hardware is getting more and more complex as these systems are expected to execute large machine learning models. To deal with the design complexity, a predictable design flow is needed to guarantee real-time performance such as latency and throughput without significantly increasing the buffer requirement of computing cores. Synchronous Data Flow Graphs (SDFGs) are used for predictable mapping of streaming applications to multiprocessor systems. We propose an SDFG-based design flow for mapping spiking neural networks (SNNs) to many-core neuromorphic hardware with the objective of exploring the tradeoff between throughput and buffer size. The proposed design flow integrates an iterative partitioning approach, based on Kernighan-Lin graph partitioning heuristic, creating SNN clusters such that each cluster can be mapped to a core of the hardware. The partitioning approach minimizes the inter-cluster spike communication, which improves latency on the shared interconnect of the hardware. Next, the design flow maps clusters to cores using an instance of the Particle Swarm Optimization (PSO), an evolutionary algorithm, exploring the design space of throughput and buffer size. Pareto optimal mappings are retained from the design flow, allowing system designers to select a Pareto mapping that satisfies throughput and buffer size requirements of the design. We evaluated the design flow using five large-scale convolutional neural network (CNN) models. Results demonstrate 63% higher maximum throughput and 10% lower buffer size requirement compared to state-of-the-art dataflow-based mapping solutions.