 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraming Migration News with LLMs: Structured CoT as a Support for Human Interpretation
Jun 02, 2026Frame analysis of migration news is a socially consequential task: media scholars and researchers who study how migration is narrated need tools that are not only accurate, but transparent, auditable, and accessible within the resource constraints typical of academic research groups. Existing LLM-based approaches rely on proprietary APIs and large models that raise concerns about data privacy, reproducibility and equitable access among media researchers. This work studies how a locally deployable open-source LLM can support interpretable frame analysis as an assistive tool. We introduce a Structured Chain-of-Thought (SCoT) prompting approach using Llama3-8B, enabling step-by-step justifications grounded in predefined framing categories. This structured design allows users to audit model outputs and examine alternative interpretations in a task that is inherently subjective. We evaluate our approach on a dataset of migration-related news and show that SCoT improves classification performance over zero-shot and few-shot baselines while remaining feasible on a single GPU. Then, we conduct a human-centered evaluation in which annotators assess the coherence and influence of "the model's reasoning". Results indicate that SCoT explanations are generally perceived as logical (mean score 4.1/5, though with notable variation across texts) and can prompt reflection on initial interpretations, even when disagreement persists. Our findings highlight both the potential and risks of LLM-assisted frame analysis. While structured reasoning can increase the traceability of model outputs and support critical interpretation, it can also influence human judgment in subtle ways. By enabling local deployment and emphasizing human-in-the-loop interaction, this work contributes to discussions on responsible and accessible computational tools for the study of socially impactful media narratives.
Seeing Without Eyes: 4D Human-Scene Understanding from Wearable IMUs
Apr 23, 2026Understanding human activities and their surrounding environments typically relies on visual perception, yet cameras pose persistent challenges in privacy, safety, energy efficiency, and scalability. We explore an alternative: 4D perception without vision. Its goal is to reconstruct human motion and 3D scene layouts purely from everyday wearable sensors. For this we introduce IMU-to-4D, a framework that repurposes large language models for non-visual spatiotemporal understanding of human-scene dynamics. IMU-to-4D uses data from a few inertial sensors from earbuds, watches, or smartphones and predicts detailed 4D human motion together with coarse scene structure. Experiments across diverse human-scene datasets show that IMU-to-4D yields more coherent and temporally stable results than SoTA cascaded pipelines, suggesting wearable motion sensors alone can support rich 4D understanding.
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
LIFe-GoM: Generalizable Human Rendering with Learned Iterative Feedback Over Multi-Resolution Gaussians-on-Mesh
Feb 13, 2025
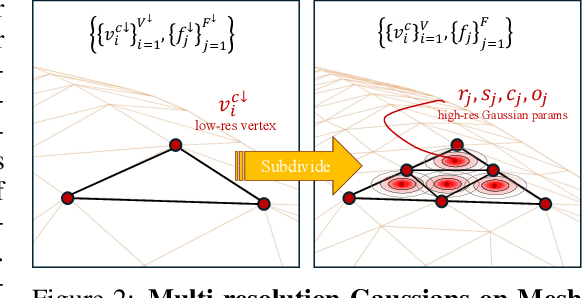


Generalizable rendering of an animatable human avatar from sparse inputs relies on data priors and inductive biases extracted from training on large data to avoid scene-specific optimization and to enable fast reconstruction. This raises two main challenges: First, unlike iterative gradient-based adjustment in scene-specific optimization, generalizable methods must reconstruct the human shape representation in a single pass at inference time. Second, rendering is preferably computationally efficient yet of high resolution. To address both challenges we augment the recently proposed dual shape representation, which combines the benefits of a mesh and Gaussian points, in two ways. To improve reconstruction, we propose an iterative feedback update framework, which successively improves the canonical human shape representation during reconstruction. To achieve computationally efficient yet high-resolution rendering, we study a coupled-multi-resolution Gaussians-on-Mesh representation. We evaluate the proposed approach on the challenging THuman2.0, XHuman and AIST++ data. Our approach reconstructs an animatable representation from sparse inputs in less than 1s, renders views with 95.1FPS at $1024 \times 1024$, and achieves PSNR/LPIPS*/FID of 24.65/110.82/51.27 on THuman2.0, outperforming the state-of-the-art in rendering quality.
AnyTaskTune: Advanced Domain-Specific Solutions through Task-Fine-Tuning
Jul 09, 2024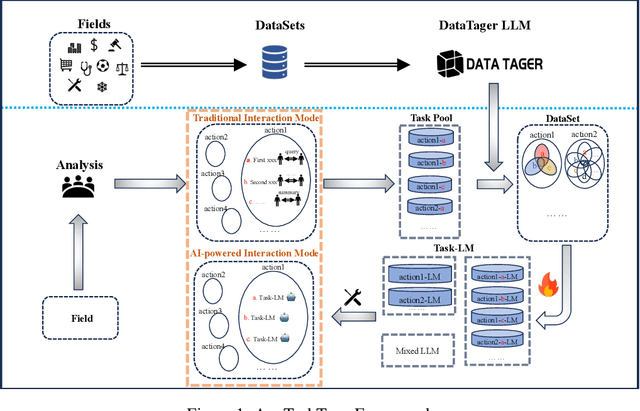
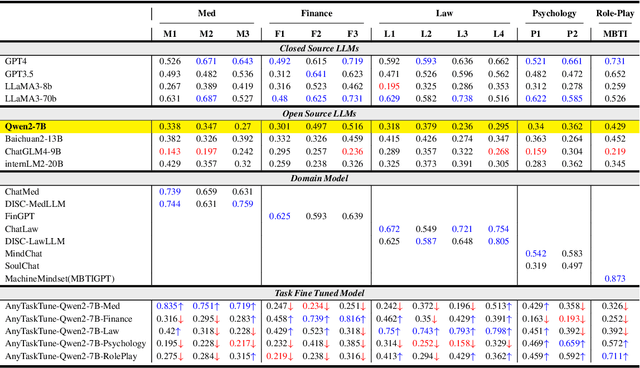


The pervasive deployment of Large Language Models-LLMs in various sectors often neglects the nuanced requirements of individuals and small organizations, who benefit more from models precisely tailored to their specific business contexts rather than those with broadly superior general capabilities. This work introduces \textbf{AnyTaskTune}, a novel fine-tuning methodology coined as \textbf{Task-Fine-Tune}, specifically developed to elevate model performance on a diverse array of domain-specific tasks. This method involves a meticulous process to identify and define targeted sub-tasks within a domain, followed by the creation of specialized enhancement datasets for fine-tuning, thereby optimizing task-specific model performance. We conducted comprehensive fine-tuning experiments not only in the legal domain for tasks such as keyword extraction and sentence prediction but across over twenty different sub-tasks derived from the domains of finance, healthcare, law, psychology, consumer services, and human resources. To substantiate our approach and facilitate community engagement, we will open-source these bilingual task datasets. Our findings demonstrate that models fine-tuned using the \textbf{Task-Fine-Tune} methodology not only achieve superior performance on these specific tasks but also significantly outperform models with higher general capabilities in their respective domains. Our work is publicly available at \url{https://github.com/PandaVT/DataTager}.
PuFace: Defending against Facial Cloaking Attacks for Facial Recognition Models
Jun 04, 2024The recently proposed facial cloaking attacks add invisible perturbation (cloaks) to facial images to protect users from being recognized by unauthorized facial recognition models. However, we show that the "cloaks" are not robust enough and can be removed from images. This paper introduces PuFace, an image purification system leveraging the generalization ability of neural networks to diminish the impact of cloaks by pushing the cloaked images towards the manifold of natural (uncloaked) images before the training process of facial recognition models. Specifically, we devise a purifier that takes all the training images including both cloaked and natural images as input and generates the purified facial images close to the manifold where natural images lie. To meet the defense goal, we propose to train the purifier on particularly amplified cloaked images with a loss function that combines image loss and feature loss. Our empirical experiment shows PuFace can effectively defend against two state-of-the-art facial cloaking attacks and reduces the attack success rate from 69.84\% to 7.61\% on average without degrading the normal accuracy for various facial recognition models. Moreover, PuFace is a model-agnostic defense mechanism that can be applied to any facial recognition model without modifying the model structure.
HOLMES: to Detect Adversarial Examples with Multiple Detectors
May 30, 2024



Deep neural networks (DNNs) can easily be cheated by some imperceptible but purposeful noise added to images, and erroneously classify them. Previous defensive work mostly focused on retraining the models or detecting the noise, but has either shown limited success rates or been attacked by new adversarial examples. Instead of focusing on adversarial images or the interior of DNN models, we observed that adversarial examples generated by different algorithms can be identified based on the output of DNNs (logits). Logit can serve as an exterior feature to train detectors. Then, we propose HOLMES (Hierarchically Organized Light-weight Multiple dEtector System) to reinforce DNNs by detecting potential adversarial examples to minimize the threats they may bring in practical. HOLMES is able to distinguish \textit{unseen} adversarial examples from multiple attacks with high accuracy and low false positive rates than single detector systems even in an adaptive model. To ensure the diversity and randomness of detectors in HOLMES, we use two methods: training dedicated detectors for each label and training detectors with top-k logits. Our effective and inexpensive strategies neither modify original DNN models nor require its internal parameters. HOLMES is not only compatible with all kinds of learning models (even only with external APIs), but also complementary to other defenses to achieve higher detection rates (may also fully protect the system against various adversarial examples).
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Apr 11, 2024We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
Machine Mindset: An MBTI Exploration of Large Language Models
Dec 30, 2023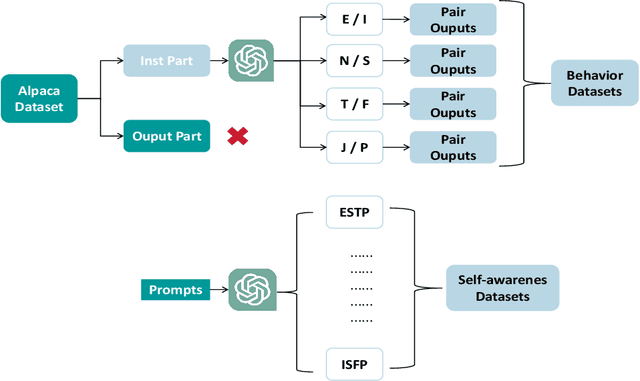
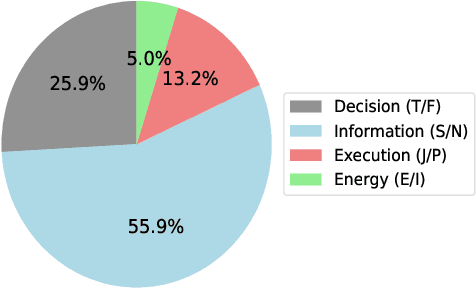
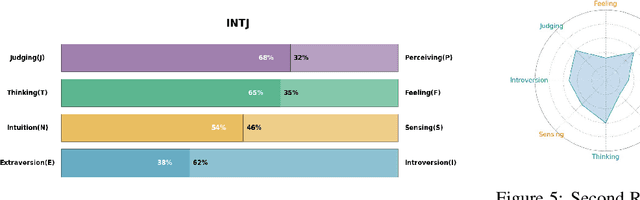
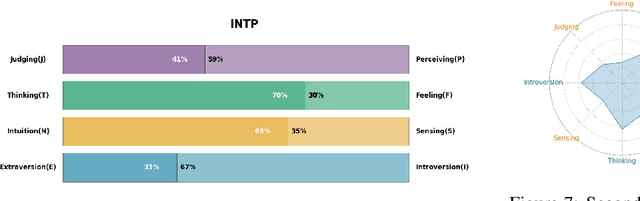
We present a novel approach for integrating Myers-Briggs Type Indicator (MBTI) personality traits into large language models (LLMs), addressing the challenges of personality consistency in personalized AI. Our method, "Machine Mindset," involves a two-phase fine-tuning and Direct Preference Optimization (DPO) to embed MBTI traits into LLMs. This approach ensures that models internalize these traits, offering a stable and consistent personality profile. We demonstrate the effectiveness of our models across various domains, showing alignment between model performance and their respective MBTI traits. The paper highlights significant contributions in the development of personality datasets and a new training methodology for personality integration in LLMs, enhancing the potential for personalized AI applications. We also open-sourced our model and part of the data at \url{https://github.com/PKU-YuanGroup/Machine-Mindset}.
A multi view multi stage and multi window framework for pulmonary artery segmentation from CT scans
Sep 14, 2022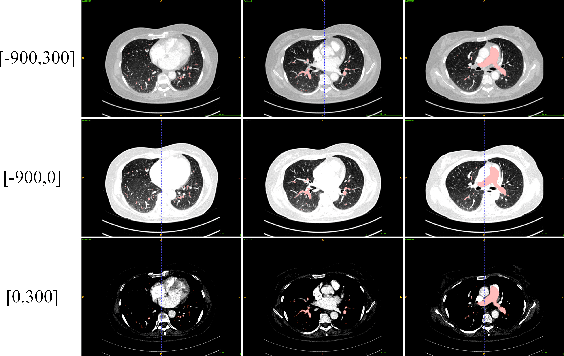


This is the technical report of the 9th place in the final result of PARSE2022 Challenge. We solve the segmentation problem of the pulmonary artery by using a two-stage method based on a 3D CNN network. The coarse model is used to locate the ROI, and the fine model is used to refine the segmentation result. In addition, in order to improve the segmentation performance, we adopt multi-view and multi-window level method, at the same time we employ a fine-tune strategy to mitigate the impact of inconsistent labeling.