 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenUS: A Fully Open-Source Foundation Model for Ultrasound Image Analysis via Self-Adaptive Masked Contrastive Learning
Nov 14, 2025Ultrasound (US) is one of the most widely used medical imaging modalities, thanks to its low cost, portability, real-time feedback, and absence of ionizing radiation. However, US image interpretation remains highly operator-dependent and varies significantly across anatomical regions, acquisition protocols, and device types. These variations, along with unique challenges such as speckle, low contrast, and limited standardized annotations, hinder the development of generalizable, label-efficient ultrasound AI models. In this paper, we propose OpenUS, the first reproducible, open-source ultrasound foundation model built on a large collection of public data. OpenUS employs a vision Mamba backbone, capturing both local and global long-range dependencies across the image. To extract rich features during pre-training, we introduce a novel self-adaptive masking framework that combines contrastive learning with masked image modeling. This strategy integrates the teacher's attention map with student reconstruction loss, adaptively refining clinically-relevant masking to enhance pre-training effectiveness. OpenUS also applies a dynamic learning schedule to progressively adjust the difficulty of the pre-training process. To develop the foundation model, we compile the largest to-date public ultrasound dataset comprising over 308K images from 42 publicly available datasets, covering diverse anatomical regions, institutions, imaging devices, and disease types. Our pre-trained OpenUS model can be easily adapted to specific downstream tasks by serving as a backbone for label-efficient fine-tuning. Code is available at https://github.com/XZheng0427/OpenUS.
XFMamba: Cross-Fusion Mamba for Multi-View Medical Image Classification
Mar 04, 2025Compared to single view medical image classification, using multiple views can significantly enhance predictive accuracy as it can account for the complementarity of each view while leveraging correlations between views. Existing multi-view approaches typically employ separate convolutional or transformer branches combined with simplistic feature fusion strategies. However, these approaches inadvertently disregard essential cross-view correlations, leading to suboptimal classification performance, and suffer from challenges with limited receptive field (CNNs) or quadratic computational complexity (transformers). Inspired by state space sequence models, we propose XFMamba, a pure Mamba-based cross-fusion architecture to address the challenge of multi-view medical image classification. XFMamba introduces a novel two-stage fusion strategy, facilitating the learning of single-view features and their cross-view disparity. This mechanism captures spatially long-range dependencies in each view while enhancing seamless information transfer between views. Results on three public datasets, MURA, CheXpert and DDSM, illustrate the effectiveness of our approach across diverse multi-view medical image classification tasks, showing that it outperforms existing convolution-based and transformer-based multi-view methods. Code is available at https://github.com/XZheng0427/XFMamba.
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
Joint Attention Mechanism Learning to Facilitate Opto-physiological Monitoring during Physical Activity
Feb 13, 2025Opto-physiological monitoring is a non-contact technique for measuring cardiac signals, i.e., photoplethysmography (PPG). Quality PPG signals directly lead to reliable physiological readings. However, PPG signal acquisition procedures are often accompanied by spurious motion artefacts (MAs), especially during low-to-high-intensity physical activity. This study proposes a practical adversarial learning approach for opto-physiological monitoring by using a generative adversarial network with an attention mechanism (AM-GAN) to model motion noise and to allow MA removal. The AM-GAN learns an MA-resistant mapping from raw and noisy signals to clear PPG signals in an adversarial manner, guided by an attention mechanism to directly translate the motion reference of triaxial acceleration to the MAs appearing in the raw signal. The AM-GAN was experimented with three various protocols engaged with 39 subjects in various physical activities. The average absolute error for heart rate (HR) derived from the MA-free PPG signal via the AM-GAN, is 1.81 beats/min for the IEEE-SPC dataset and 3.86 beats/min for the PPGDalia dataset. The same procedure applied to an in-house LU dataset resulted in average absolute errors for HR and respiratory rate (RR) of less than 1.37 beats/min and 2.49 breaths/min, respectively. The study demonstrates the robustness and resilience of AM-GAN, particularly during low-to-high-intensity physical activities.
GTransPDM: A Graph-embedded Transformer with Positional Decoupling for Pedestrian Crossing Intention Prediction
Sep 30, 2024



Understanding and predicting pedestrian crossing behavioral intention is crucial for autonomous vehicles driving safety. Nonetheless, challenges emerge when using promising images or environmental context masks to extract various factors for time-series network modeling, causing pre-processing errors or a loss in efficiency. Typically, pedestrian positions captured by onboard cameras are often distorted and do not accurately reflect their actual movements. To address these issues, GTransPDM -- a Graph-embedded Transformer with a Position Decoupling Module -- was developed for pedestrian crossing intention prediction by leveraging multi-modal features. First, a positional decoupling module was proposed to decompose the pedestrian lateral movement and simulate depth variations in the image view. Then, a graph-embedded Transformer was designed to capture the spatial-temporal dynamics of human pose skeletons, integrating essential factors such as position, skeleton, and ego-vehicle motion. Experimental results indicate that the proposed method achieves 92% accuracy on the PIE dataset and 87% accuracy on the JAAD dataset, with a processing speed of 0.05ms. It outperforms the state-of-the-art in comparison.
TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models
Apr 14, 2024



Multimodal Large Language Models (MLLMs) have shown impressive results on various multimodal tasks. However, most existing MLLMs are not well suited for document-oriented tasks, which require fine-grained image perception and information compression. In this paper, we present TextHawk, a MLLM that is specifically designed for document-oriented tasks, while preserving the general capabilities of MLLMs. TextHawk is aimed to explore efficient fine-grained perception by designing four dedicated components. Firstly, a ReSampling and ReArrangement (ReSA) module is proposed to reduce the redundancy in the document texts and lower the computational cost of the MLLM. We explore encoding the positions of each local feature by presenting Scalable Positional Embeddings (SPEs), which can preserve the scalability of various image sizes. A Query Proposal Network (QPN) is then adopted to initialize the queries dynamically among different sub-images. To further enhance the fine-grained visual perceptual ability of the MLLM, we design a Multi-Level Cross-Attention (MLCA) mechanism that captures the hierarchical structure and semantic relations of document images. Furthermore, we create a new instruction-tuning dataset for document-oriented tasks by enriching the multimodal document data with Gemini Pro. We conduct extensive experiments on both general and document-oriented MLLM benchmarks, and show that TextHawk outperforms the state-of-the-art methods, demonstrating its effectiveness and superiority in fine-grained document perception and general abilities.
Morphy: A Datamorphic Software Test Automation Tool
Dec 20, 2019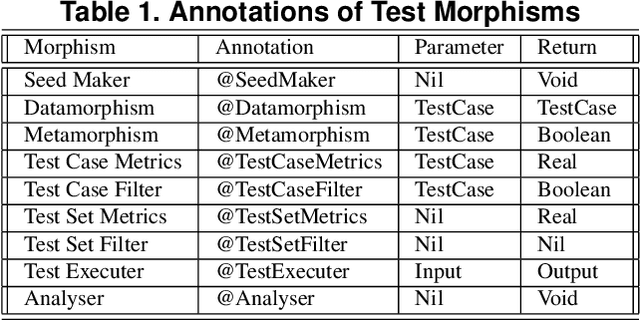
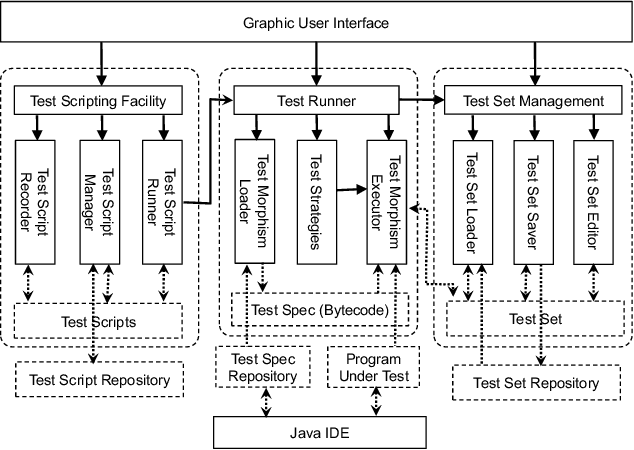
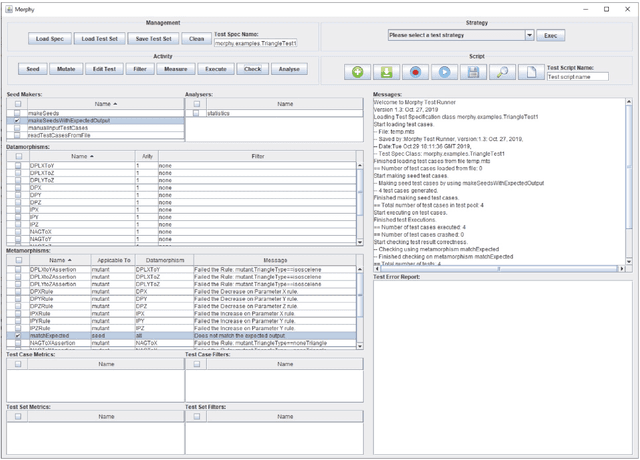
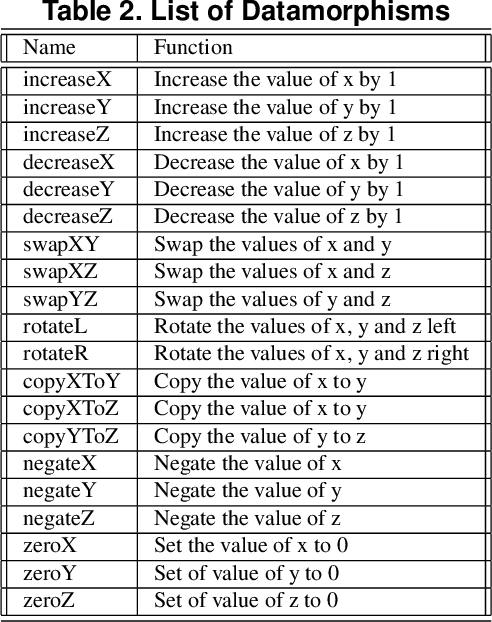
This paper presents an automated tool called Morphy for datamorphic testing. It classifies software test artefacts into test entities and test morphisms, which are mappings on testing entities. In addition to datamorphisms, metamorphisms and seed test case makers, Morphy also employs a set of other test morphisms including test case metrics and filters, test set metrics and filters, test result analysers and test executers to realise test automation. In particular, basic testing activities can be automated by invoking test morphisms. Test strategies can be realised as complex combinations of test morphisms. Test processes can be automated by recording, editing and playing test scripts that invoke test morphisms and strategies. Three types of test strategies have been implemented in Morphy: datamorphism combination strategies, cluster border exploration strategies and strategies for test set optimisation via genetic algorithms. This paper focuses on the datamorphism combination strategies by giving their definitions and implementation algorithms. The paper also illustrates their uses for testing both traditional software and AI applications with three case studies.
Global Continuous Optimization with Error Bound and Fast Convergence
Jul 17, 2016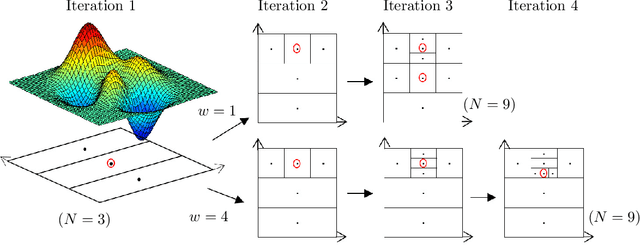
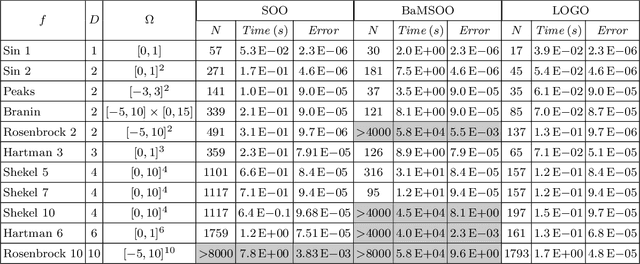
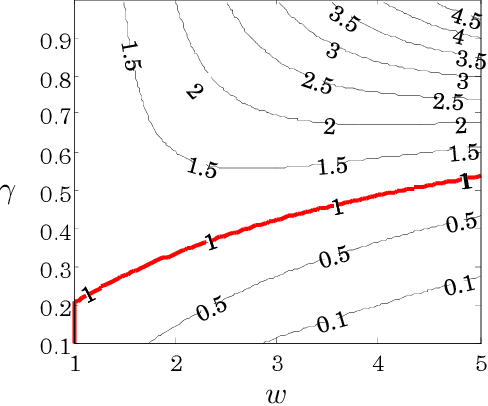
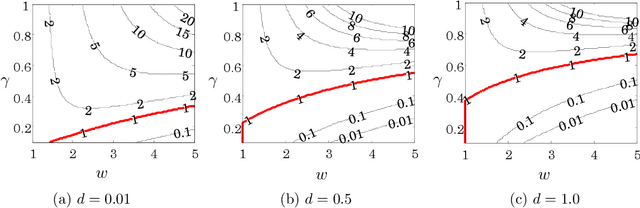
This paper considers global optimization with a black-box unknown objective function that can be non-convex and non-differentiable. Such a difficult optimization problem arises in many real-world applications, such as parameter tuning in machine learning, engineering design problem, and planning with a complex physics simulator. This paper proposes a new global optimization algorithm, called Locally Oriented Global Optimization (LOGO), to aim for both fast convergence in practice and finite-time error bound in theory. The advantage and usage of the new algorithm are illustrated via theoretical analysis and an experiment conducted with 11 benchmark test functions. Further, we modify the LOGO algorithm to specifically solve a planning problem via policy search with continuous state/action space and long time horizon while maintaining its finite-time error bound. We apply the proposed planning method to accident management of a nuclear power plant. The result of the application study demonstrates the practical utility of our method.