 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenEval: A Benchmark for Scenario-Based Evaluation of Code Generation
Jun 18, 2024



In the scenario-based evaluation of machine learning models, a key problem is how to construct test datasets that represent various scenarios. The methodology proposed in this paper is to construct a benchmark and attach metadata to each test case. Then a test system can be constructed with test morphisms that filter the test cases based on metadata to form a dataset. The paper demonstrates this methodology with large language models for code generation. A benchmark called ScenEval is constructed from problems in textbooks, an online tutorial website and Stack Overflow. Filtering by scenario is demonstrated and the test sets are used to evaluate ChatGPT for Java code generation. Our experiments found that the performance of ChatGPT decreases with the complexity of the coding task. It is weakest for advanced topics like multi-threading, data structure algorithms and recursive methods. The Java code generated by ChatGPT tends to be much shorter than reference solution in terms of number of lines, while it is more likely to be more complex in both cyclomatic and cognitive complexity metrics, if the generated code is correct. However, the generated code is more likely to be less complex than the reference solution if the code is incorrect.
Benchmarks and Metrics for Evaluations of Code Generation: A Critical Review
Jun 18, 2024With the rapid development of Large Language Models (LLMs), a large number of machine learning models have been developed to assist programming tasks including the generation of program code from natural language input. However, how to evaluate such LLMs for this task is still an open problem despite of the great amount of research efforts that have been made and reported to evaluate and compare them. This paper provides a critical review of the existing work on the testing and evaluation of these tools with a focus on two key aspects: the benchmarks and the metrics used in the evaluations. Based on the review, further research directions are discussed.
Discovering Boundary Values of Feature-based Machine Learning Classifiers through Exploratory Datamorphic Testing
Oct 01, 2021
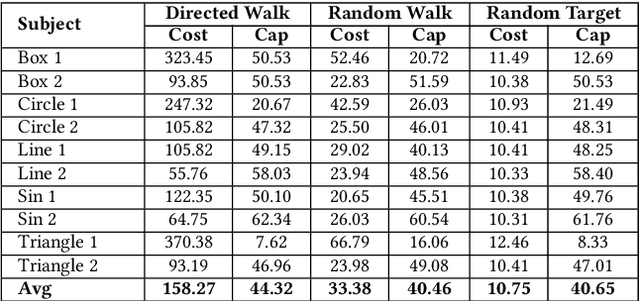


Testing has been widely recognised as difficult for AI applications. This paper proposes a set of testing strategies for testing machine learning applications in the framework of the datamorphism testing methodology. In these strategies, testing aims at exploring the data space of a classification or clustering application to discover the boundaries between classes that the machine learning application defines. This enables the tester to understand precisely the behaviour and function of the software under test. In the paper, three variants of exploratory strategies are presented with the algorithms implemented in the automated datamorphic testing tool Morphy. The correctness of these algorithms are formally proved. Their capability and cost of discovering borders between classes are evaluated via a set of controlled experiments with manually designed subjects and a set of case studies with real machine learning models.
Morphy: A Datamorphic Software Test Automation Tool
Dec 20, 2019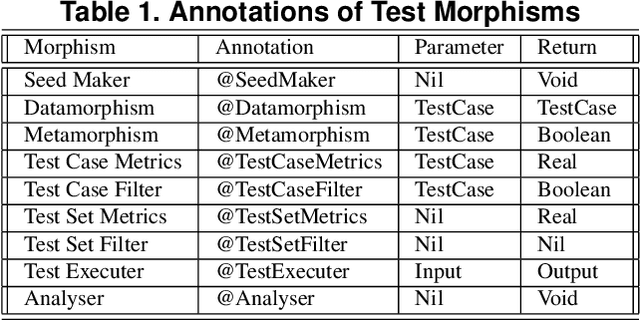
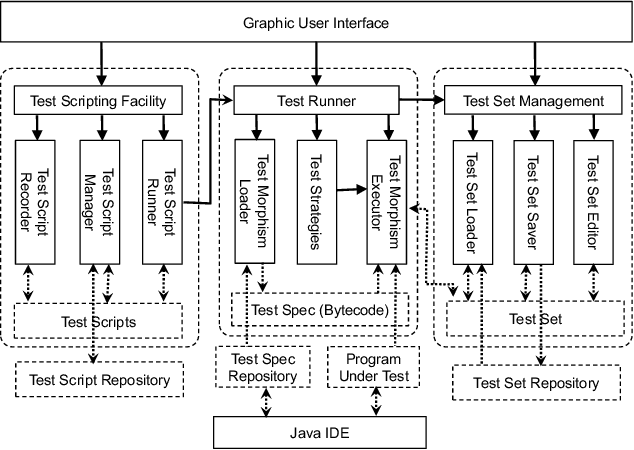
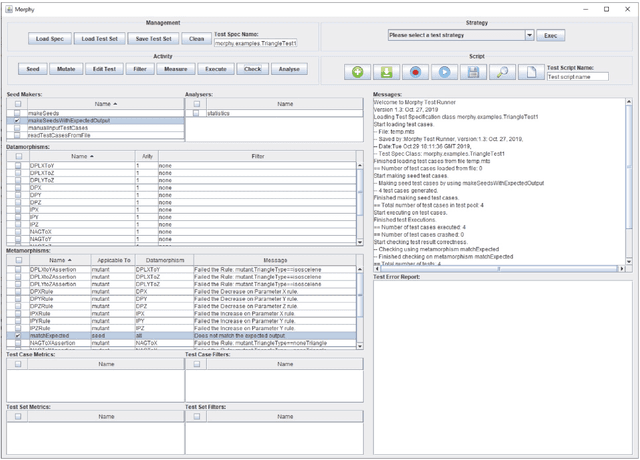
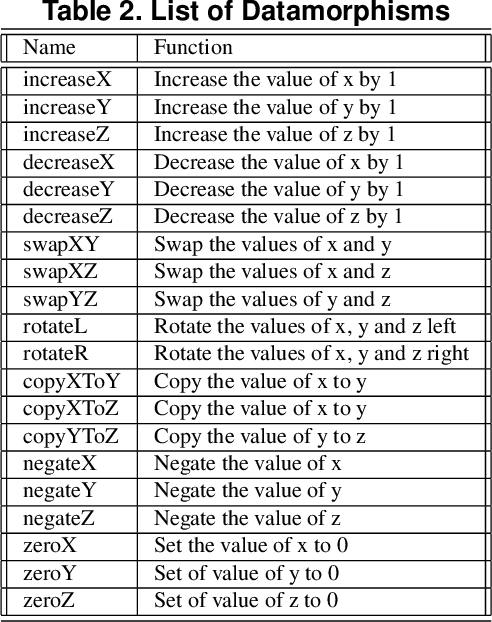
This paper presents an automated tool called Morphy for datamorphic testing. It classifies software test artefacts into test entities and test morphisms, which are mappings on testing entities. In addition to datamorphisms, metamorphisms and seed test case makers, Morphy also employs a set of other test morphisms including test case metrics and filters, test set metrics and filters, test result analysers and test executers to realise test automation. In particular, basic testing activities can be automated by invoking test morphisms. Test strategies can be realised as complex combinations of test morphisms. Test processes can be automated by recording, editing and playing test scripts that invoke test morphisms and strategies. Three types of test strategies have been implemented in Morphy: datamorphism combination strategies, cluster border exploration strategies and strategies for test set optimisation via genetic algorithms. This paper focuses on the datamorphism combination strategies by giving their definitions and implementation algorithms. The paper also illustrates their uses for testing both traditional software and AI applications with three case studies.
Datamorphic Testing: A Methodology for Testing AI Applications
Dec 10, 2019

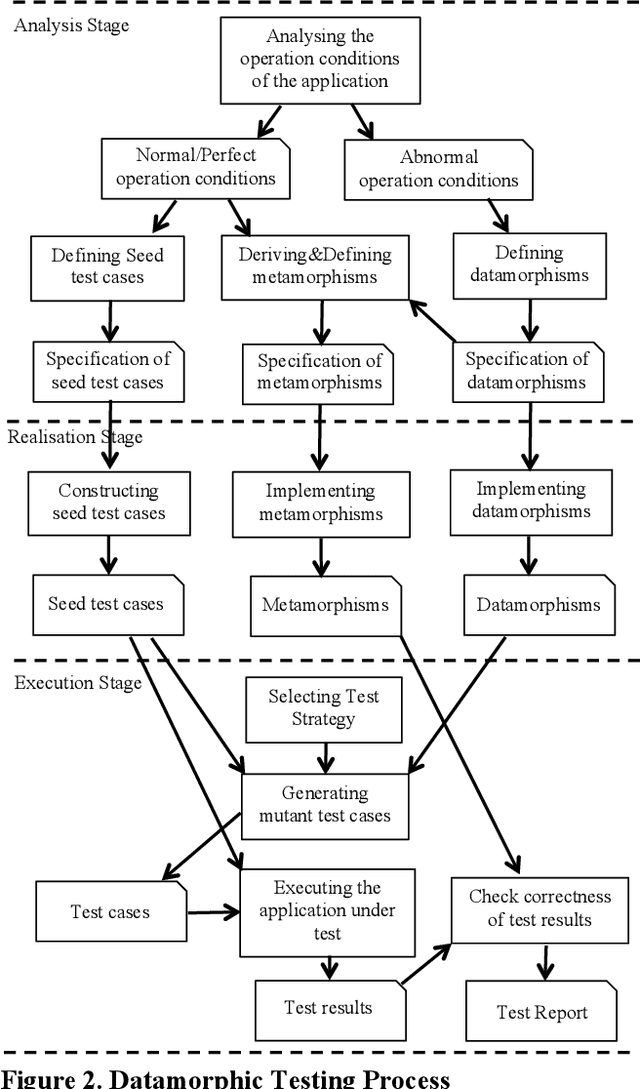
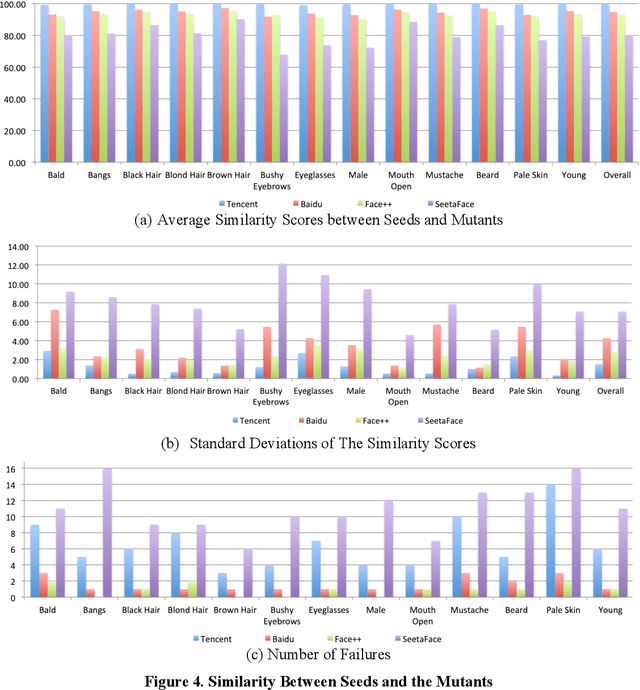
With the rapid growth of the applications of machine learning (ML) and other artificial intelligence (AI) techniques, adequate testing has become a necessity to ensure their quality. This paper identifies the characteristics of AI applications that distinguish them from traditional software, and analyses the main difficulties in applying existing testing methods. Based on this analysis, we propose a new method called datamorphic testing and illustrate the method with an example of testing face recognition applications. We also report an experiment with four real industrial application systems of face recognition to validate the proposed approach.