 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree of Preferences for Diversified Recommendation
Dec 24, 2025Diversified recommendation has attracted increasing attention from both researchers and practitioners, which can effectively address the homogeneity of recommended items. Existing approaches predominantly aim to infer the diversity of user preferences from observed user feedback. Nonetheless, due to inherent data biases, the observed data may not fully reflect user interests, where underexplored preferences can be overwhelmed or remain unmanifested. Failing to capture these preferences can lead to suboptimal diversity in recommendations. To fill this gap, this work aims to study diversified recommendation from a data-bias perspective. Inspired by the outstanding performance of large language models (LLMs) in zero-shot inference leveraging world knowledge, we propose a novel approach that utilizes LLMs' expertise to uncover underexplored user preferences from observed behavior, ultimately providing diverse and relevant recommendations. To achieve this, we first introduce Tree of Preferences (ToP), an innovative structure constructed to model user preferences from coarse to fine. ToP enables LLMs to systematically reason over the user's rationale behind their behavior, thereby uncovering their underexplored preferences. To guide diversified recommendations using uncovered preferences, we adopt a data-centric approach, identifying candidate items that match user preferences and generating synthetic interactions that reflect underexplored preferences. These interactions are integrated to train a general recommender for diversification. Moreover, we scale up overall efficiency by dynamically selecting influential users during optimization. Extensive evaluations of both diversity and relevance show that our approach outperforms existing methods in most cases and achieves near-optimal performance in others, with reasonable inference latency.
SEDM: Scalable Self-Evolving Distributed Memory for Agents
Sep 11, 2025Long-term multi-agent systems inevitably generate vast amounts of trajectories and historical interactions, which makes efficient memory management essential for both performance and scalability. Existing methods typically depend on vector retrieval and hierarchical storage, yet they are prone to noise accumulation, uncontrolled memory expansion, and limited generalization across domains. To address these challenges, we present SEDM, Self-Evolving Distributed Memory, a verifiable and adaptive framework that transforms memory from a passive repository into an active, self-optimizing component. SEDM integrates verifiable write admission based on reproducible replay, a self-scheduling memory controller that dynamically ranks and consolidates entries according to empirical utility, and cross-domain knowledge diffusion that abstracts reusable insights to support transfer across heterogeneous tasks. Evaluations on benchmark datasets demonstrate that SEDM improves reasoning accuracy while reducing token overhead compared with strong memory baselines, and further enables knowledge distilled from fact verification to enhance multi-hop reasoning. The results highlight SEDM as a scalable and sustainable memory mechanism for open-ended multi-agent collaboration. The code will be released in the later stage of this project.
SHAPE : Self-Improved Visual Preference Alignment by Iteratively Generating Holistic Winner
Mar 06, 2025



Large Visual Language Models (LVLMs) increasingly rely on preference alignment to ensure reliability, which steers the model behavior via preference fine-tuning on preference data structured as ``image - winner text - loser text'' triplets. However, existing approaches often suffer from limited diversity and high costs associated with human-annotated preference data, hindering LVLMs from fully achieving their intended alignment capabilities. We present \projectname, a self-supervised framework capable of transforming the already abundant supervised text-image pairs into holistic preference triplets for more effective and cheaper LVLM alignment, eliminating the need for human preference annotations. Our approach facilitates LVLMs in progressively enhancing alignment capabilities through iterative self-improvement. The key design rationale is to devise preference triplets where the winner text consistently improves in holisticness and outperforms the loser response in quality, thereby pushing the model to ``strive to the utmost'' of alignment performance through preference fine-tuning. For each given text-image pair, SHAPE introduces multiple visual augmentations and pairs them with a summarized text to serve as the winner response, while designating the original text as the loser response. Experiments across \textbf{12} benchmarks on various model architectures and sizes, including LLaVA and DeepSeek-VL, show that SHAPE achieves significant gains, for example, achieving +11.3\% on MMVet (comprehensive evaluation), +1.4\% on MMBench (general VQA), and +8.0\% on POPE (hallucination robustness) over baselines in 7B models. Notably, qualitative analyses confirm enhanced attention to visual details and better alignment with human preferences for holistic descriptions.
Efficient and Comprehensive Feature Extraction in Large Vision-Language Model for Clinical Pathology Analysis
Dec 12, 2024Pathological diagnosis is vital for determining disease characteristics, guiding treatment, and assessing prognosis, relying heavily on detailed, multi-scale analysis of high-resolution whole slide images (WSI). However, traditional pure vision models face challenges of redundant feature extraction, whereas existing large vision-language models (LVLMs) are limited by input resolution constraints, hindering their efficiency and accuracy. To overcome these issues, we propose two innovative strategies: the mixed task-guided feature enhancement, which directs feature extraction toward lesion-related details across scales, and the prompt-guided detail feature completion, which integrates coarse- and fine-grained features from WSI based on specific prompts without compromising inference speed. Leveraging a comprehensive dataset of 490,000 samples from diverse pathology tasks-including cancer detection, grading, vascular and neural invasion identification, and so on-we trained the pathology-specialized LVLM, OmniPath. Extensive experiments demonstrate that this model significantly outperforms existing methods in diagnostic accuracy and efficiency, offering an interactive, clinically aligned approach for auxiliary diagnosis in a wide range of pathology applications.
Improving Adversarial Robustness via Feature Pattern Consistency Constraint
Jun 13, 2024



Convolutional Neural Networks (CNNs) are well-known for their vulnerability to adversarial attacks, posing significant security concerns. In response to these threats, various defense methods have emerged to bolster the model's robustness. However, most existing methods either focus on learning from adversarial perturbations, leading to overfitting to the adversarial examples, or aim to eliminate such perturbations during inference, inevitably increasing computational burdens. Conversely, clean training, which strengthens the model's robustness by relying solely on clean examples, can address the aforementioned issues. In this paper, we align with this methodological stream and enhance its generalizability to unknown adversarial examples. This enhancement is achieved by scrutinizing the behavior of latent features within the network. Recognizing that a correct prediction relies on the correctness of the latent feature's pattern, we introduce a novel and effective Feature Pattern Consistency Constraint (FPCC) method to reinforce the latent feature's capacity to maintain the correct feature pattern. Specifically, we propose Spatial-wise Feature Modification and Channel-wise Feature Selection to enhance latent features. Subsequently, we employ the Pattern Consistency Loss to constrain the similarity between the feature pattern of the latent features and the correct feature pattern. Our experiments demonstrate that the FPCC method empowers latent features to uphold correct feature patterns even in the face of adversarial examples, resulting in inherent adversarial robustness surpassing state-of-the-art models.
CNN LEGO: Disassembling and Assembling Convolutional Neural Network
Mar 25, 2022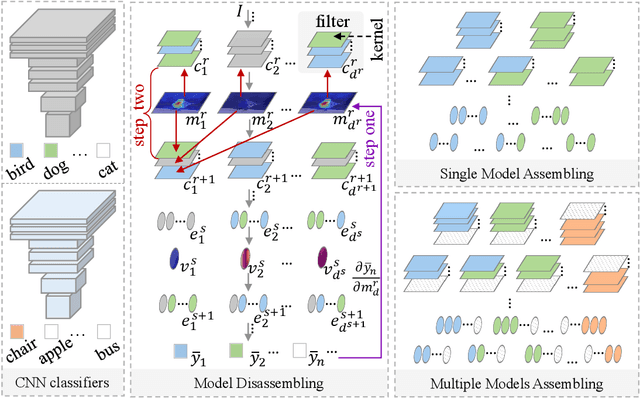
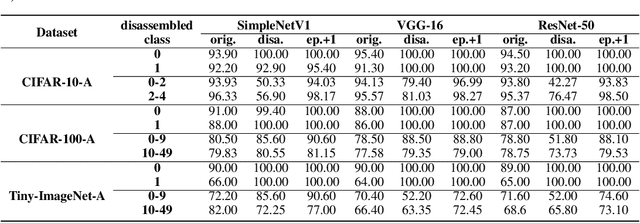
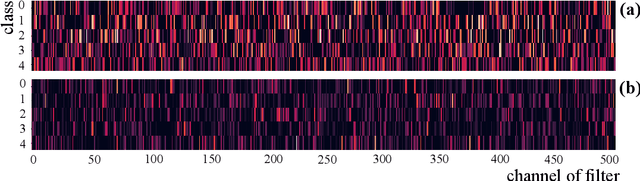
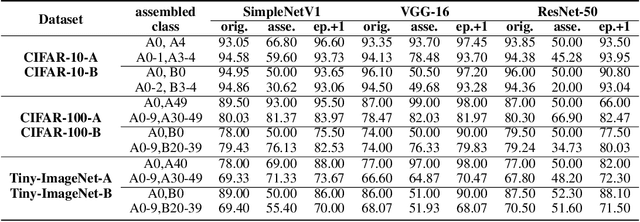
Convolutional Neural Network (CNN), which mimics human visual perception mechanism, has been successfully used in many computer vision areas. Some psychophysical studies show that the visual perception mechanism synchronously processes the form, color, movement, depth, etc., in the initial stage [7,20] and then integrates all information for final recognition [38]. What's more, the human visual system [20] contains different subdivisions or different tasks. Inspired by the above visual perception mechanism, we investigate a new task, termed as Model Disassembling and Assembling (MDA-Task), which can disassemble the deep models into independent parts and assemble those parts into a new deep model without performance cost like playing LEGO toys. To this end, we propose a feature route attribution technique (FRAT) for disassembling CNN classifiers in this paper. In FRAT, the positive derivatives of predicted class probability w.r.t. the feature maps are adopted to locate the critical features in each layer. Then, relevance analysis between the critical features and preceding/subsequent parameter layers is adopted to bridge the route between two adjacent parameter layers. In the assembling phase, class-wise components of each layer are assembled into a new deep model for a specific task. Extensive experiments demonstrate that the assembled CNN classifier can achieve close accuracy with the original classifier without any fine-tune, and excess original performance with one-epoch fine-tune. What's more, we also conduct massive experiments to verify the broad application of MDA-Task on model decision route visualization, model compression, knowledge distillation, transfer learning, incremental learning, and so on.
Model Doctor: A Simple Gradient Aggregation Strategy for Diagnosing and Treating CNN Classifiers
Dec 09, 2021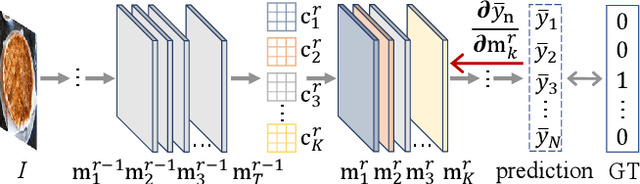
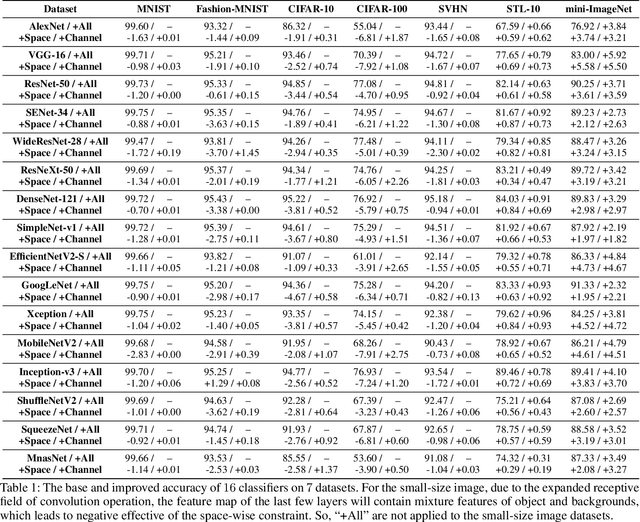
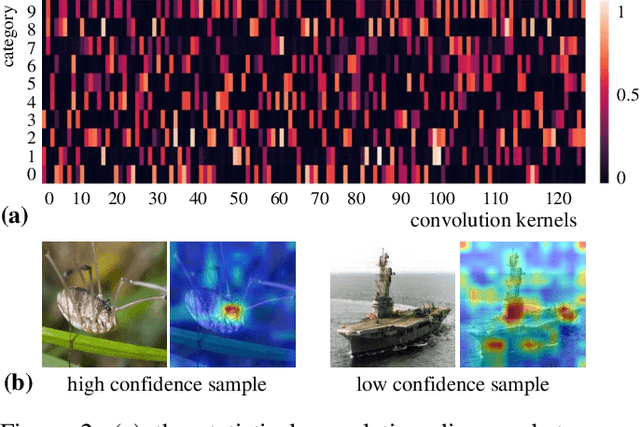

Recently, Convolutional Neural Network (CNN) has achieved excellent performance in the classification task. It is widely known that CNN is deemed as a 'black-box', which is hard for understanding the prediction mechanism and debugging the wrong prediction. Some model debugging and explanation works are developed for solving the above drawbacks. However, those methods focus on explanation and diagnosing possible causes for model prediction, based on which the researchers handle the following optimization of models manually. In this paper, we propose the first completely automatic model diagnosing and treating tool, termed as Model Doctor. Based on two discoveries that 1) each category is only correlated with sparse and specific convolution kernels, and 2) adversarial samples are isolated while normal samples are successive in the feature space, a simple aggregate gradient constraint is devised for effectively diagnosing and optimizing CNN classifiers. The aggregate gradient strategy is a versatile module for mainstream CNN classifiers. Extensive experiments demonstrate that the proposed Model Doctor applies to all existing CNN classifiers, and improves the accuracy of $16$ mainstream CNN classifiers by 1%-5%.