 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNN LEGO: Disassembling and Assembling Convolutional Neural Network
Paper and Code
Mar 25, 2022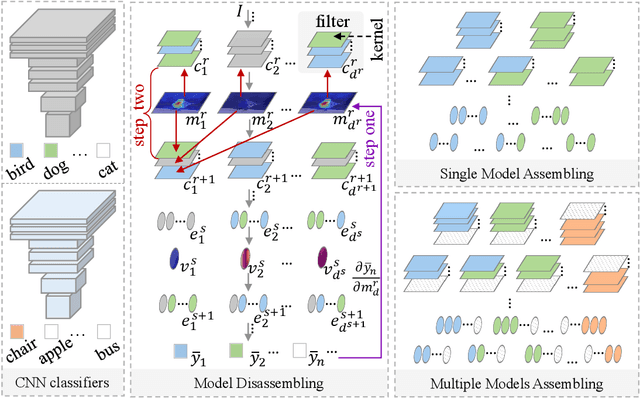
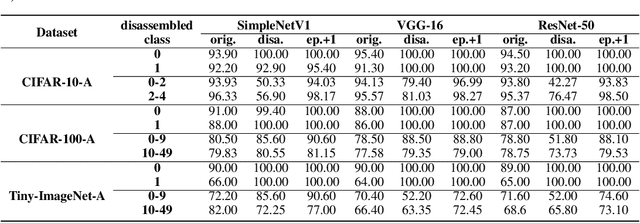
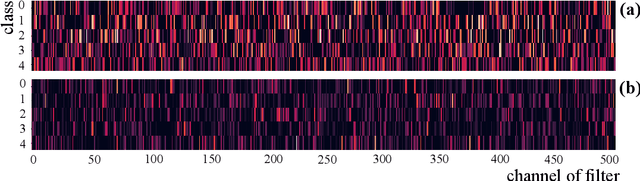
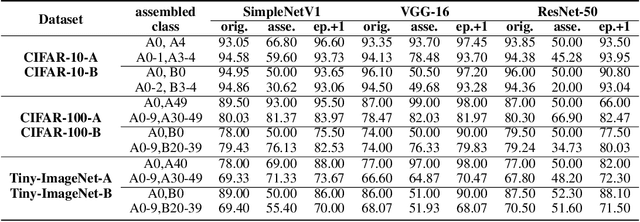
Convolutional Neural Network (CNN), which mimics human visual perception mechanism, has been successfully used in many computer vision areas. Some psychophysical studies show that the visual perception mechanism synchronously processes the form, color, movement, depth, etc., in the initial stage [7,20] and then integrates all information for final recognition [38]. What's more, the human visual system [20] contains different subdivisions or different tasks. Inspired by the above visual perception mechanism, we investigate a new task, termed as Model Disassembling and Assembling (MDA-Task), which can disassemble the deep models into independent parts and assemble those parts into a new deep model without performance cost like playing LEGO toys. To this end, we propose a feature route attribution technique (FRAT) for disassembling CNN classifiers in this paper. In FRAT, the positive derivatives of predicted class probability w.r.t. the feature maps are adopted to locate the critical features in each layer. Then, relevance analysis between the critical features and preceding/subsequent parameter layers is adopted to bridge the route between two adjacent parameter layers. In the assembling phase, class-wise components of each layer are assembled into a new deep model for a specific task. Extensive experiments demonstrate that the assembled CNN classifier can achieve close accuracy with the original classifier without any fine-tune, and excess original performance with one-epoch fine-tune. What's more, we also conduct massive experiments to verify the broad application of MDA-Task on model decision route visualization, model compression, knowledge distillation, transfer learning, incremental learning, and so on.