 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods
Paper and Code
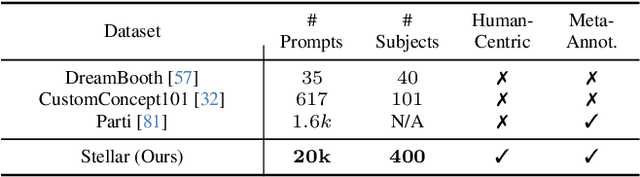



In this work, we systematically study the problem of personalized text-to-image generation, where the output image is expected to portray information about specific human subjects. E.g., generating images of oneself appearing at imaginative places, interacting with various items, or engaging in fictional activities. To this end, we focus on text-to-image systems that input a single image of an individual to ground the generation process along with text describing the desired visual context. Our first contribution is to fill the literature gap by curating high-quality, appropriate data for this task. Namely, we introduce a standardized dataset (Stellar) that contains personalized prompts coupled with images of individuals that is an order of magnitude larger than existing relevant datasets and where rich semantic ground-truth annotations are readily available. Having established Stellar to promote cross-systems fine-grained comparisons further, we introduce a rigorous ensemble of specialized metrics that highlight and disentangle fundamental properties such systems should obey. Besides being intuitive, our new metrics correlate significantly more strongly with human judgment than currently used metrics on this task. Last but not least, drawing inspiration from the recent works of ELITE and SDXL, we derive a simple yet efficient, personalized text-to-image baseline that does not require test-time fine-tuning for each subject and which sets quantitatively and in human trials a new SoTA. For more information, please visit our project's website: https://stellar-gen-ai.github.io/.