 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthwise Discrete Representation Learning
Paper and Code
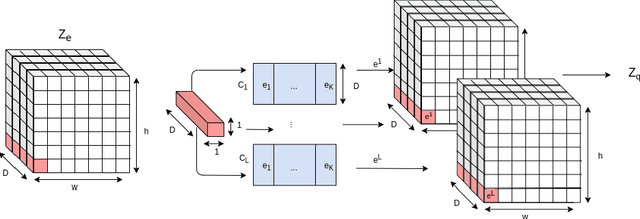
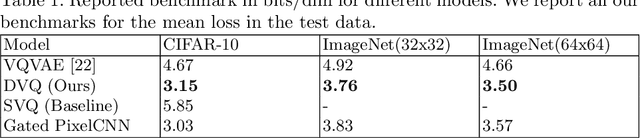
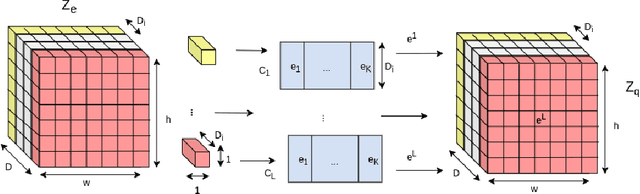
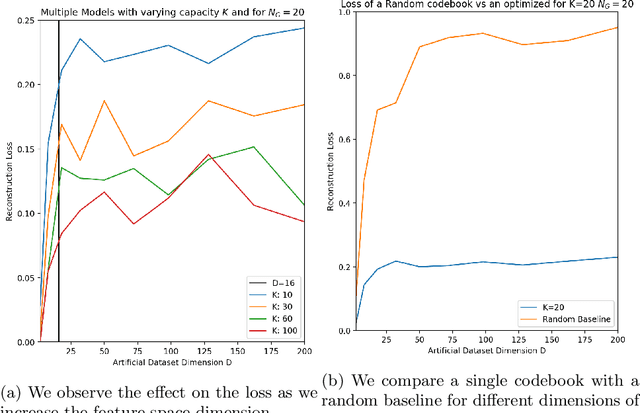
Recent advancements in learning Discrete Representations as opposed to continuous ones have led to state of art results in tasks that involve Language, Audio and Vision. Some latent factors such as words, phonemes and shapes are better represented by discrete latent variables as opposed to continuous. Vector Quantized Variational Autoencoders (VQVAE) have produced remarkable results in multiple domains. VQVAE learns a prior distribution $z_e$ along with its mapping to a discrete number of $K$ vectors (Vector Quantization). We propose applying VQ along the feature axis. We hypothesize that by doing so, we are learning a mapping between the codebook vectors and the marginal distribution of the prior feature space. Our approach leads to 33\% improvement as compared to prevous discrete models and has similar performance to state of the art auto-regressive models (e.g. PixelSNAIL). We evaluate our approach on a static prior using an artificial toy dataset (blobs). We further evaluate our approach on benchmarks for CIFAR-10 and ImageNet.