 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoveltyBench: Evaluating Language Models for Humanlike Diversity
Apr 08, 2025Language models have demonstrated remarkable capabilities on standard benchmarks, yet they struggle increasingly from mode collapse, the inability to generate diverse and novel outputs. Our work introduces NoveltyBench, a benchmark specifically designed to evaluate the ability of language models to produce multiple distinct and high-quality outputs. NoveltyBench utilizes prompts curated to elicit diverse answers and filtered real-world user queries. Evaluating 20 leading language models, we find that current state-of-the-art systems generate significantly less diversity than human writers. Notably, larger models within a family often exhibit less diversity than their smaller counterparts, challenging the notion that capability on standard benchmarks translates directly to generative utility. While prompting strategies like in-context regeneration can elicit diversity, our findings highlight a fundamental lack of distributional diversity in current models, reducing their utility for users seeking varied responses and suggesting the need for new training and evaluation paradigms that prioritize diversity alongside quality.
ProMQA: Question Answering Dataset for Multimodal Procedural Activity Understanding
Oct 29, 2024Multimodal systems have great potential to assist humans in procedural activities, where people follow instructions to achieve their goals. Despite diverse application scenarios, systems are typically evaluated on traditional classification tasks, e.g., action recognition or temporal action segmentation. In this paper, we present a novel evaluation dataset, ProMQA, to measure system advancements in application-oriented scenarios. ProMQA consists of 401 multimodal procedural QA pairs on user recording of procedural activities coupled with their corresponding instruction. For QA annotation, we take a cost-effective human-LLM collaborative approach, where the existing annotation is augmented with LLM-generated QA pairs that are later verified by humans. We then provide the benchmark results to set the baseline performance on ProMQA. Our experiment reveals a significant gap between human performance and that of current systems, including competitive proprietary multimodal models. We hope our dataset sheds light on new aspects of models' multimodal understanding capabilities.
Formulation Comparison for Timeline Construction using LLMs
Mar 01, 2024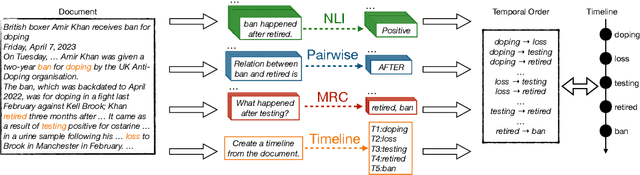
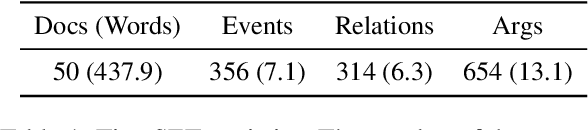

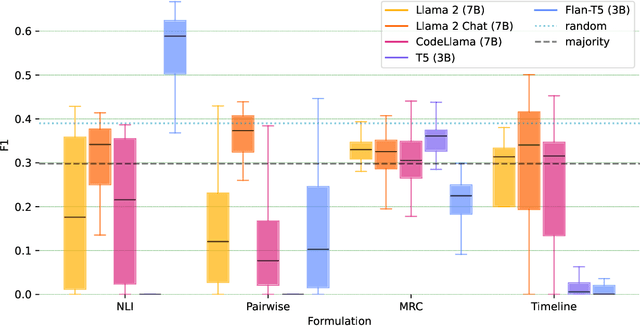
Constructing a timeline requires identifying the chronological order of events in an article. In prior timeline construction datasets, temporal orders are typically annotated by either event-to-time anchoring or event-to-event pairwise ordering, both of which suffer from missing temporal information. To mitigate the issue, we develop a new evaluation dataset, TimeSET, consisting of single-document timelines with document-level order annotation. TimeSET features saliency-based event selection and partial ordering, which enable a practical annotation workload. Aiming to build better automatic timeline construction systems, we propose a novel evaluation framework to compare multiple task formulations with TimeSET by prompting open LLMs, i.e., Llama 2 and Flan-T5. Considering that identifying temporal orders of events is a core subtask in timeline construction, we further benchmark open LLMs on existing event temporal ordering datasets to gain a robust understanding of their capabilities. Our experiments show that (1) NLI formulation with Flan-T5 demonstrates a strong performance among others, while (2) timeline construction and event temporal ordering are still challenging tasks for few-shot LLMs. Our code and data are available at https://github.com/kimihiroh/timeset.