 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOME-KGQA: A Benchmark Dataset for Multimodal Knowledge Graph Question Answering on Household Daily Activities
May 10, 2026Large Language Models (LLMs) provide flexible natural language processing capabilities, while knowledge graphs (KGs) offer explicit and structured knowledge. Integrating these two in a complementary manner enables the development of reliable and verifiable AI systems. In particular, knowledge graph question answering (KGQA) has attracted attention as a means to reduce LLM hallucinations and to leverage knowledge beyond the training data. However, existing KGQA benchmark datasets are biased toward encyclopedic knowledge, limited to a single modality, and lack fine-grained spatiotemporal data, which limits their applicability to real-world scenarios targeted by Embodied AI. We introduce HOME-KGQA, a novel KGQA benchmark dataset built on a multimodal KG of daily household activities. HOME-KGQA consists of complex, multi-hop natural language questions paired with graph database query languages. Compared to existing benchmarks, it includes more challenging questions that involve multi-level spatiotemporal reasoning, multimodal grounding, and aggregate functions. Experimental results show that the LLM-based KGQA methods fail to achieve performance comparable to that on existing datasets when evaluated on HOME-KGQA. This highlights significant challenges that should be addressed for the real-world deployment of KGQA systems. Our dataset is available at https://github.com/aistairc/home-kgqa
On the Role of Unobserved Sequences on Sample-based Uncertainty Quantification for LLMs
Oct 06, 2025Quantifying uncertainty in large language models (LLMs) is important for safety-critical applications because it helps spot incorrect answers, known as hallucinations. One major trend of uncertainty quantification methods is based on estimating the entropy of the distribution of the LLM's potential output sequences. This estimation is based on a set of output sequences and associated probabilities obtained by querying the LLM several times. In this paper, we advocate and experimentally show that the probability of unobserved sequences plays a crucial role, and we recommend future research to integrate it to enhance such LLM uncertainty quantification methods.
A Video-grounded Dialogue Dataset and Metric for Event-driven Activities
Jan 30, 2025



This paper presents VDAct, a dataset for a Video-grounded Dialogue on Event-driven Activities, alongside VDEval, a session-based context evaluation metric specially designed for the task. Unlike existing datasets, VDAct includes longer and more complex video sequences that depict a variety of event-driven activities that require advanced contextual understanding for accurate response generation. The dataset comprises 3,000 dialogues with over 30,000 question-and-answer pairs, derived from 1,000 videos with diverse activity scenarios. VDAct displays a notably challenging characteristic due to its broad spectrum of activity scenarios and wide range of question types. Empirical studies on state-of-the-art vision foundation models highlight their limitations in addressing certain question types on our dataset. Furthermore, VDEval, which integrates dialogue session history and video content summaries extracted from our supplementary Knowledge Graphs to evaluate individual responses, demonstrates a significantly higher correlation with human assessments on the VDAct dataset than existing evaluation metrics that rely solely on the context of single dialogue turns.
ProMQA: Question Answering Dataset for Multimodal Procedural Activity Understanding
Oct 29, 2024Multimodal systems have great potential to assist humans in procedural activities, where people follow instructions to achieve their goals. Despite diverse application scenarios, systems are typically evaluated on traditional classification tasks, e.g., action recognition or temporal action segmentation. In this paper, we present a novel evaluation dataset, ProMQA, to measure system advancements in application-oriented scenarios. ProMQA consists of 401 multimodal procedural QA pairs on user recording of procedural activities coupled with their corresponding instruction. For QA annotation, we take a cost-effective human-LLM collaborative approach, where the existing annotation is augmented with LLM-generated QA pairs that are later verified by humans. We then provide the benchmark results to set the baseline performance on ProMQA. Our experiment reveals a significant gap between human performance and that of current systems, including competitive proprietary multimodal models. We hope our dataset sheds light on new aspects of models' multimodal understanding capabilities.
VHAKG: A Multi-modal Knowledge Graph Based on Synchronized Multi-view Videos of Daily Activities
Aug 27, 2024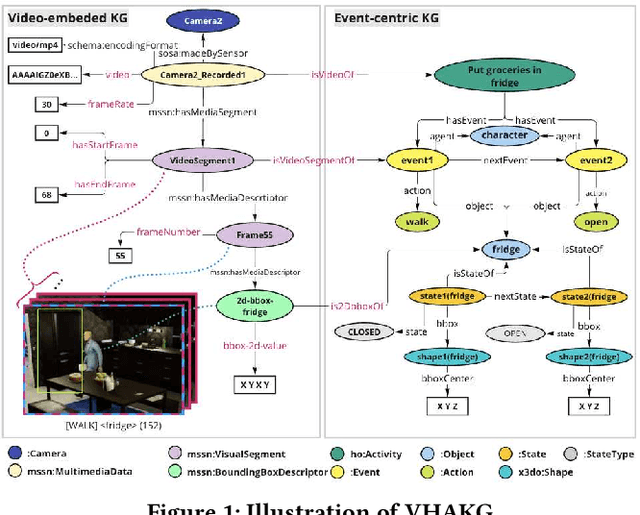
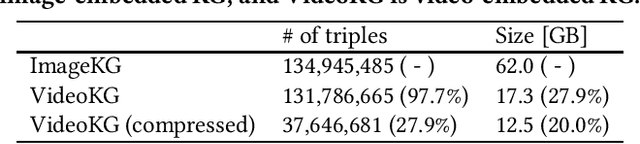
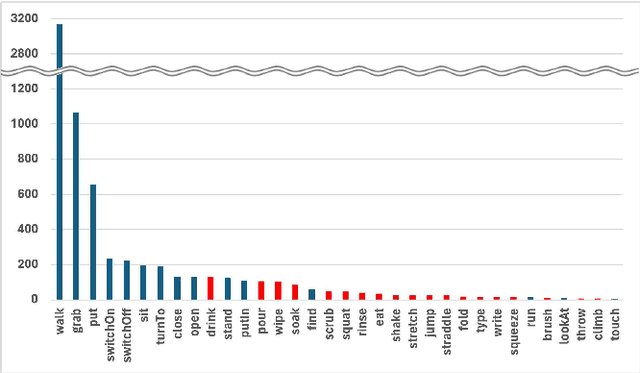
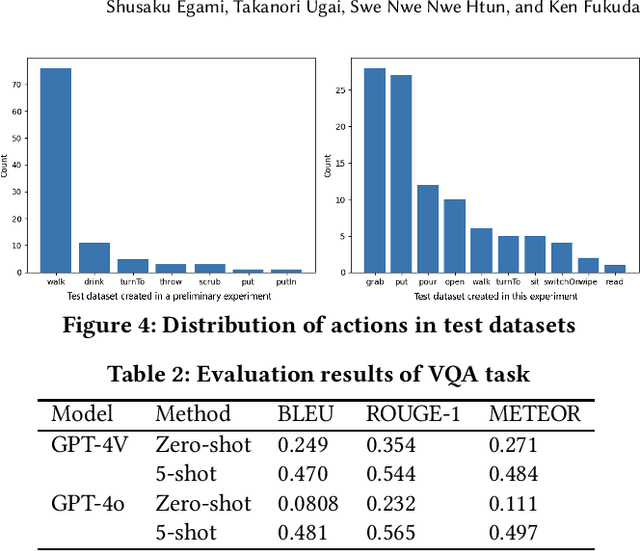
Multi-modal knowledge graphs (MMKGs), which ground various non-symbolic data (e.g., images and videos) into symbols, have attracted attention as resources enabling knowledge processing and machine learning across modalities. However, the construction of MMKGs for videos consisting of multiple events, such as daily activities, is still in the early stages. In this paper, we construct an MMKG based on synchronized multi-view simulated videos of daily activities. Besides representing the content of daily life videos as event-centric knowledge, our MMKG also includes frame-by-frame fine-grained changes, such as bounding boxes within video frames. In addition, we provide support tools for querying our MMKG. As an application example, we demonstrate that our MMKG facilitates benchmarking vision-language models by providing the necessary vision-language datasets for a tailored task.
Multimodal Datasets and Benchmarks for Reasoning about Dynamic Spatio-Temporality in Everyday Environments
Aug 21, 2024
We used a 3D simulator to create artificial video data with standardized annotations, aiming to aid in the development of Embodied AI. Our question answering (QA) dataset measures the extent to which a robot can understand human behavior and the environment in a home setting. Preliminary experiments suggest our dataset is useful in measuring AI's comprehension of daily life. \end{abstract}
Synthetic Multimodal Dataset for Empowering Safety and Well-being in Home Environments
Jan 26, 2024This paper presents a synthetic multimodal dataset of daily activities that fuses video data from a 3D virtual space simulator with knowledge graphs depicting the spatiotemporal context of the activities. The dataset is developed for the Knowledge Graph Reasoning Challenge for Social Issues (KGRC4SI), which focuses on identifying and addressing hazardous situations in the home environment. The dataset is available to the public as a valuable resource for researchers and practitioners developing innovative solutions recognizing human behaviors to enhance safety and well-being in
RDF-star2Vec: RDF-star Graph Embeddings for Data Mining
Dec 25, 2023



Knowledge Graphs (KGs) such as Resource Description Framework (RDF) data represent relationships between various entities through the structure of triples (<subject, predicate, object>). Knowledge graph embedding (KGE) is crucial in machine learning applications, specifically in node classification and link prediction tasks. KGE remains a vital research topic within the semantic web community. RDF-star introduces the concept of a quoted triple (QT), a specific form of triple employed either as the subject or object within another triple. Moreover, RDF-star permits a QT to act as compositional entities within another QT, thereby enabling the representation of recursive, hyper-relational KGs with nested structures. However, existing KGE models fail to adequately learn the semantics of QTs and entities, primarily because they do not account for RDF-star graphs containing multi-leveled nested QTs and QT-QT relationships. This study introduces RDF-star2Vec, a novel KGE model specifically designed for RDF-star graphs. RDF-star2Vec introduces graph walk techniques that enable probabilistic transitions between a QT and its compositional entities. Feature vectors for QTs, entities, and relations are derived from generated sequences through the structured skip-gram model. Additionally, we provide a dataset and a benchmarking framework for data mining tasks focused on complex RDF-star graphs. Evaluative experiments demonstrated that RDF-star2Vec yielded superior performance compared to recent extensions of RDF2Vec in various tasks including classification, clustering, entity relatedness, and QT similarity.
* 13 pages, 6 figures, and this paper has been accepted by IEEE Access
Synthesizing Event-centric Knowledge Graphs of Daily Activities Using Virtual Space
Jul 30, 2023



Artificial intelligence (AI) is expected to be embodied in software agents, robots, and cyber-physical systems that can understand the various contextual information of daily life in the home environment to support human behavior and decision making in various situations. Scene graph and knowledge graph (KG) construction technologies have attracted much attention for knowledge-based embodied question answering meeting this expectation. However, collecting and managing real data on daily activities under various experimental conditions in a physical space are quite costly, and developing AI that understands the intentions and contexts is difficult. In the future, data from both virtual spaces, where conditions can be easily modified, and physical spaces, where conditions are difficult to change, are expected to be combined to analyze daily living activities. However, studies on the KG construction of daily activities using virtual space and their application have yet to progress. The potential and challenges must still be clarified to facilitate AI development for human daily life. Thus, this study proposes the VirtualHome2KG framework to generate synthetic KGs of daily life activities in virtual space. This framework augments both the synthetic video data of daily activities and the contextual semantic data corresponding to the video contents based on the proposed event-centric schema and virtual space simulation results. Therefore, context-aware data can be analyzed, and various applications that have conventionally been difficult to develop due to the insufficient availability of relevant data and semantic information can be developed. We also demonstrate herein the utility and potential of the proposed VirtualHome2KG framework through several use cases, including the analysis of daily activities by querying, embedding, and clustering, and fall risk detection among ...
* 17 pages, 12 figures, and this paper has been accepted by IEEE Access