 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Video-grounded Dialogue Dataset and Metric for Event-driven Activities
Jan 30, 2025



This paper presents VDAct, a dataset for a Video-grounded Dialogue on Event-driven Activities, alongside VDEval, a session-based context evaluation metric specially designed for the task. Unlike existing datasets, VDAct includes longer and more complex video sequences that depict a variety of event-driven activities that require advanced contextual understanding for accurate response generation. The dataset comprises 3,000 dialogues with over 30,000 question-and-answer pairs, derived from 1,000 videos with diverse activity scenarios. VDAct displays a notably challenging characteristic due to its broad spectrum of activity scenarios and wide range of question types. Empirical studies on state-of-the-art vision foundation models highlight their limitations in addressing certain question types on our dataset. Furthermore, VDEval, which integrates dialogue session history and video content summaries extracted from our supplementary Knowledge Graphs to evaluate individual responses, demonstrates a significantly higher correlation with human assessments on the VDAct dataset than existing evaluation metrics that rely solely on the context of single dialogue turns.
Multilingual Open QA on the MIA Shared Task
Jan 07, 2025Cross-lingual information retrieval (CLIR) ~\cite{shi2021cross, asai2021one, jiang2020cross} for example, can find relevant text in any language such as English(high resource) or Telugu (low resource) even when the query is posed in a different, possibly low-resource, language. In this work, we aim to develop useful CLIR models for this constrained, yet important, setting where we do not require any kind of additional supervision or labelled data for retrieval task and hence can work effectively for low-resource languages. \par We propose a simple and effective re-ranking method for improving passage retrieval in open question answering. The re-ranker re-scores retrieved passages with a zero-shot multilingual question generation model, which is a pre-trained language model, to compute the probability of the input question in the target language conditioned on a retrieved passage, which can be possibly in a different language. We evaluate our method in a completely zero shot setting and doesn't require any training. Thus the main advantage of our method is that our approach can be used to re-rank results obtained by any sparse retrieval methods like BM-25. This eliminates the need for obtaining expensive labelled corpus required for the retrieval tasks and hence can be used for low resource languages.
ProMQA: Question Answering Dataset for Multimodal Procedural Activity Understanding
Oct 29, 2024Multimodal systems have great potential to assist humans in procedural activities, where people follow instructions to achieve their goals. Despite diverse application scenarios, systems are typically evaluated on traditional classification tasks, e.g., action recognition or temporal action segmentation. In this paper, we present a novel evaluation dataset, ProMQA, to measure system advancements in application-oriented scenarios. ProMQA consists of 401 multimodal procedural QA pairs on user recording of procedural activities coupled with their corresponding instruction. For QA annotation, we take a cost-effective human-LLM collaborative approach, where the existing annotation is augmented with LLM-generated QA pairs that are later verified by humans. We then provide the benchmark results to set the baseline performance on ProMQA. Our experiment reveals a significant gap between human performance and that of current systems, including competitive proprietary multimodal models. We hope our dataset sheds light on new aspects of models' multimodal understanding capabilities.
Formulation Comparison for Timeline Construction using LLMs
Mar 01, 2024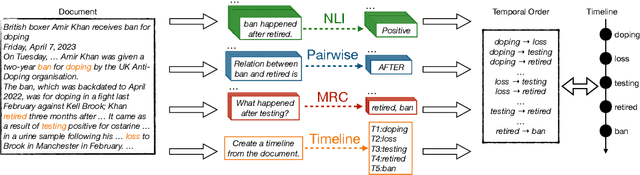
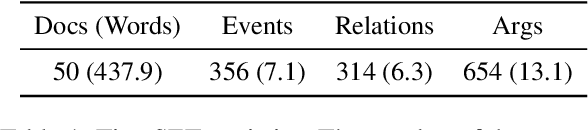

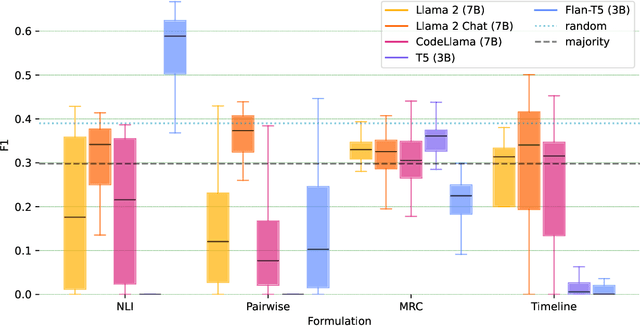
Constructing a timeline requires identifying the chronological order of events in an article. In prior timeline construction datasets, temporal orders are typically annotated by either event-to-time anchoring or event-to-event pairwise ordering, both of which suffer from missing temporal information. To mitigate the issue, we develop a new evaluation dataset, TimeSET, consisting of single-document timelines with document-level order annotation. TimeSET features saliency-based event selection and partial ordering, which enable a practical annotation workload. Aiming to build better automatic timeline construction systems, we propose a novel evaluation framework to compare multiple task formulations with TimeSET by prompting open LLMs, i.e., Llama 2 and Flan-T5. Considering that identifying temporal orders of events is a core subtask in timeline construction, we further benchmark open LLMs on existing event temporal ordering datasets to gain a robust understanding of their capabilities. Our experiments show that (1) NLI formulation with Flan-T5 demonstrates a strong performance among others, while (2) timeline construction and event temporal ordering are still challenging tasks for few-shot LLMs. Our code and data are available at https://github.com/kimihiroh/timeset.
Cross-document Event Identity via Dense Annotation
Sep 14, 2021
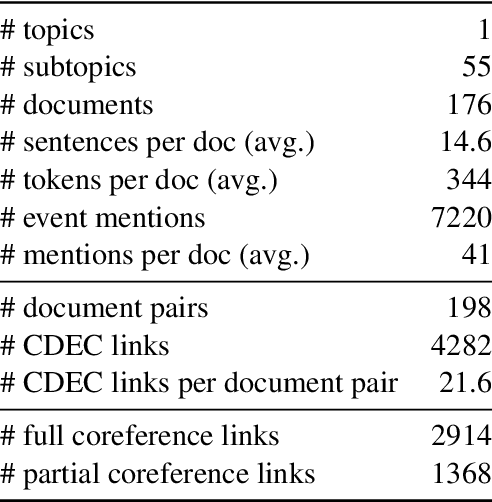


In this paper, we study the identity of textual events from different documents. While the complex nature of event identity is previously studied (Hovy et al., 2013), the case of events across documents is unclear. Prior work on cross-document event coreference has two main drawbacks. First, they restrict the annotations to a limited set of event types. Second, they insufficiently tackle the concept of event identity. Such annotation setup reduces the pool of event mentions and prevents one from considering the possibility of quasi-identity relations. We propose a dense annotation approach for cross-document event coreference, comprising a rich source of event mentions and a dense annotation effort between related document pairs. To this end, we design a new annotation workflow with careful quality control and an easy-to-use annotation interface. In addition to the links, we further collect overlapping event contexts, including time, location, and participants, to shed some light on the relation between identity decisions and context. We present an open-access dataset for cross-document event coreference, CDEC-WN, collected from English Wikinews and open-source our annotation toolkit to encourage further research on cross-document tasks.