 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Generalizing to Unseen Concepts: An Evaluation Framework and An LLM-Based Auto-Labeled Pipeline for Biomedical Concept Recognition
Jan 23, 2026Generalization to unseen concepts is a central challenge due to the scarcity of human annotations in Mention-agnostic Biomedical Concept Recognition (MA-BCR). This work makes two key contributions to systematically address this issue. First, we propose an evaluation framework built on hierarchical concept indices and novel metrics to measure generalization. Second, we explore LLM-based Auto-Labeled Data (ALD) as a scalable resource, creating a task-specific pipeline for its generation. Our research unequivocally shows that while LLM-generated ALD cannot fully substitute for manual annotations, it is a valuable resource for improving generalization, successfully providing models with the broader coverage and structural knowledge needed to approach recognizing unseen concepts. Code and datasets are available at https://github.com/bio-ie-tool/hi-ald.
MA-COIR: Leveraging Semantic Search Index and Generative Models for Ontology-Driven Biomedical Concept Recognition
May 19, 2025Recognizing biomedical concepts in the text is vital for ontology refinement, knowledge graph construction, and concept relationship discovery. However, traditional concept recognition methods, relying on explicit mention identification, often fail to capture complex concepts not explicitly stated in the text. To overcome this limitation, we introduce MA-COIR, a framework that reformulates concept recognition as an indexing-recognition task. By assigning semantic search indexes (ssIDs) to concepts, MA-COIR resolves ambiguities in ontology entries and enhances recognition efficiency. Using a pretrained BART-based model fine-tuned on small datasets, our approach reduces computational requirements to facilitate adoption by domain experts. Furthermore, we incorporate large language models (LLMs)-generated queries and synthetic data to improve recognition in low-resource settings. Experimental results on three scenarios (CDR, HPO, and HOIP) highlight the effectiveness of MA-COIR in recognizing both explicit and implicit concepts without the need for mention-level annotations during inference, advancing ontology-driven concept recognition in biomedical domain applications. Our code and constructed data are available at https://github.com/sl-633/macoir-master.
Synthetic Multimodal Dataset for Empowering Safety and Well-being in Home Environments
Jan 26, 2024This paper presents a synthetic multimodal dataset of daily activities that fuses video data from a 3D virtual space simulator with knowledge graphs depicting the spatiotemporal context of the activities. The dataset is developed for the Knowledge Graph Reasoning Challenge for Social Issues (KGRC4SI), which focuses on identifying and addressing hazardous situations in the home environment. The dataset is available to the public as a valuable resource for researchers and practitioners developing innovative solutions recognizing human behaviors to enhance safety and well-being in
RDF-star2Vec: RDF-star Graph Embeddings for Data Mining
Dec 25, 2023



Knowledge Graphs (KGs) such as Resource Description Framework (RDF) data represent relationships between various entities through the structure of triples (<subject, predicate, object>). Knowledge graph embedding (KGE) is crucial in machine learning applications, specifically in node classification and link prediction tasks. KGE remains a vital research topic within the semantic web community. RDF-star introduces the concept of a quoted triple (QT), a specific form of triple employed either as the subject or object within another triple. Moreover, RDF-star permits a QT to act as compositional entities within another QT, thereby enabling the representation of recursive, hyper-relational KGs with nested structures. However, existing KGE models fail to adequately learn the semantics of QTs and entities, primarily because they do not account for RDF-star graphs containing multi-leveled nested QTs and QT-QT relationships. This study introduces RDF-star2Vec, a novel KGE model specifically designed for RDF-star graphs. RDF-star2Vec introduces graph walk techniques that enable probabilistic transitions between a QT and its compositional entities. Feature vectors for QTs, entities, and relations are derived from generated sequences through the structured skip-gram model. Additionally, we provide a dataset and a benchmarking framework for data mining tasks focused on complex RDF-star graphs. Evaluative experiments demonstrated that RDF-star2Vec yielded superior performance compared to recent extensions of RDF2Vec in various tasks including classification, clustering, entity relatedness, and QT similarity.
* 13 pages, 6 figures, and this paper has been accepted by IEEE Access
Extracting Domain-specific Concepts from Large-scale Linked Open Data
Nov 22, 2021
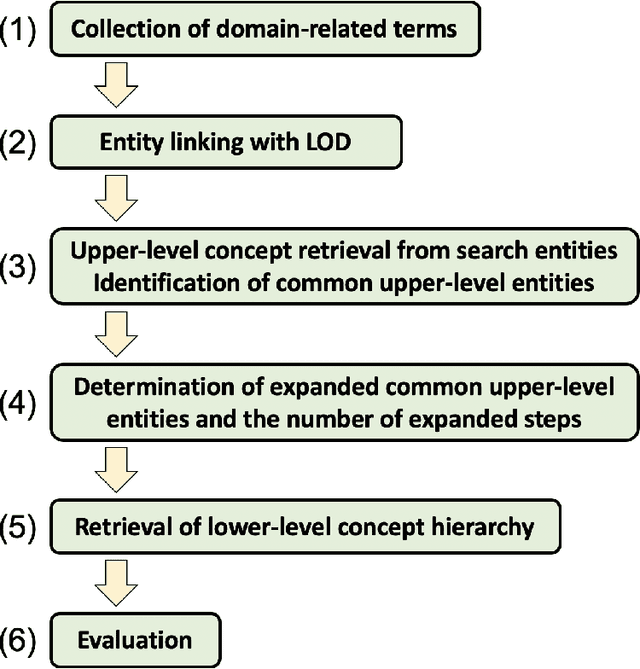
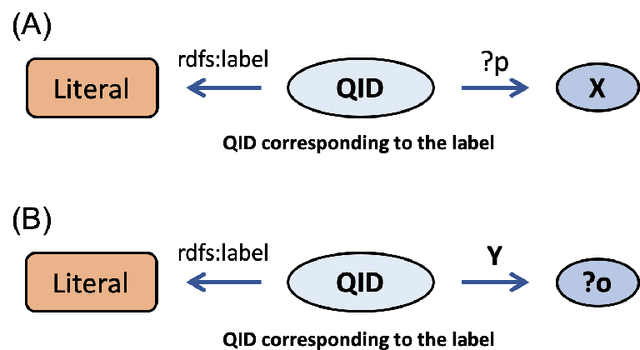
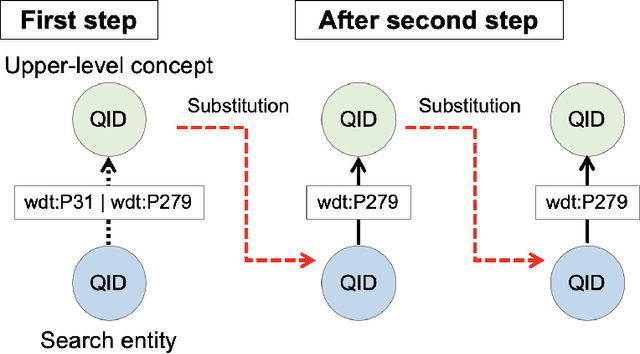
We propose a methodology for extracting concepts for a target domain from large-scale linked open data (LOD) to support the construction of domain ontologies providing field-specific knowledge and definitions. The proposed method defines search entities by linking the LOD vocabulary with technical terms related to the target domain. The search entities are then used as a starting point for obtaining upper-level concepts in the LOD, and the occurrences of common upper-level entities and the chain-of-path relationships are examined to determine the range of conceptual connections in the target domain. A technical dictionary index and natural language processing are used to evaluate whether the extracted concepts cover the domain. As an example of extracting a class hierarchy from LOD, we used Wikidata to construct a domain ontology for polymer materials and physical properties. The proposed method can be applied to general datasets with class hierarchies, and it allows ontology developers to create an initial model of the domain ontology for their own purposes.
Report on the First Knowledge Graph Reasoning Challenge 2018 -- Toward the eXplainable AI System
Aug 22, 2019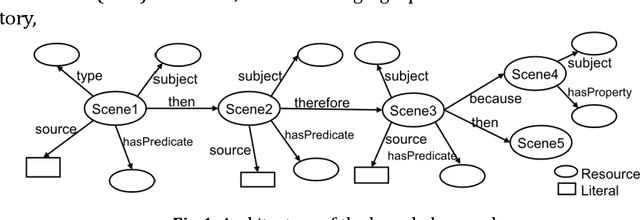
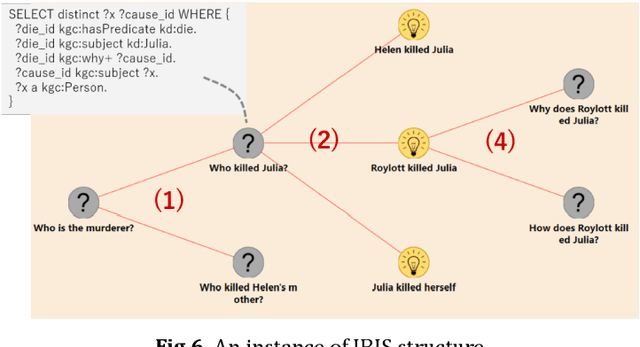
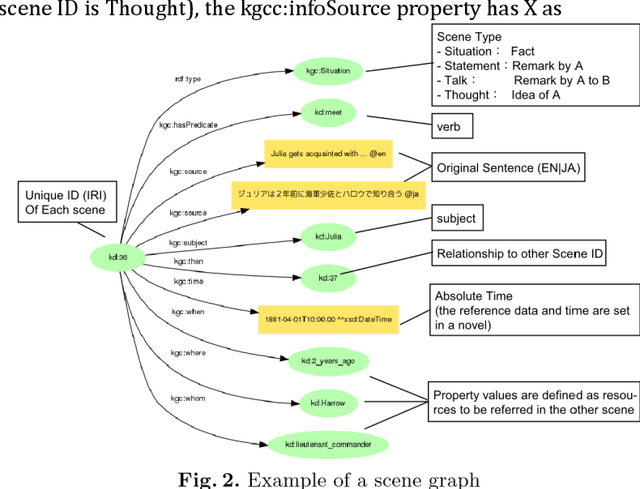
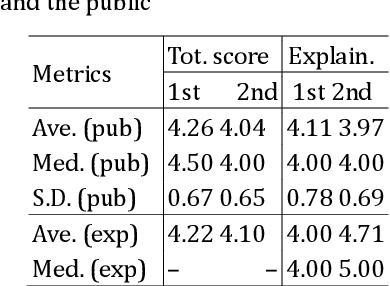
A new challenge for knowledge graph reasoning started in 2018. Deep learning has promoted the application of artificial intelligence (AI) techniques to a wide variety of social problems. Accordingly, being able to explain the reason for an AI decision is becoming important to ensure the secure and safe use of AI techniques. Thus, we, the Special Interest Group on Semantic Web and Ontology of the Japanese Society for AI, organized a challenge calling for techniques that reason and/or estimate which characters are criminals while providing a reasonable explanation based on an open knowledge graph of a well-known Sherlock Holmes mystery story. This paper presents a summary report of the first challenge held in 2018, including the knowledge graph construction, the techniques proposed for reasoning and/or estimation, the evaluation metrics, and the results. The first prize went to an approach that formalized the problem as a constraint satisfaction problem and solved it using a lightweight formal method; the second prize went to an approach that used SPARQL and rules; the best resource prize went to a submission that constructed word embedding of characters from all sentences of Sherlock Holmes novels; and the best idea prize went to a discussion multi-agents model. We conclude this paper with the plans and issues for the next challenge in 2019.