 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocAgent: A Multi-Agent System for Automated Code Documentation Generation
Apr 11, 2025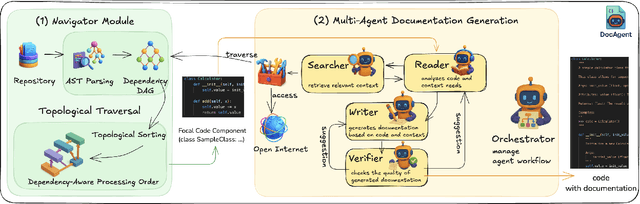
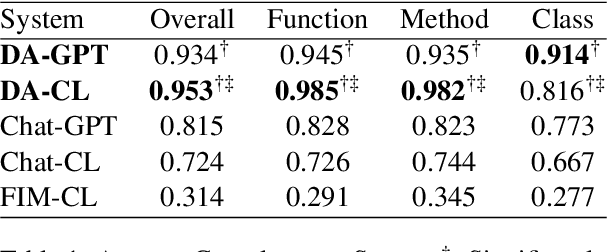
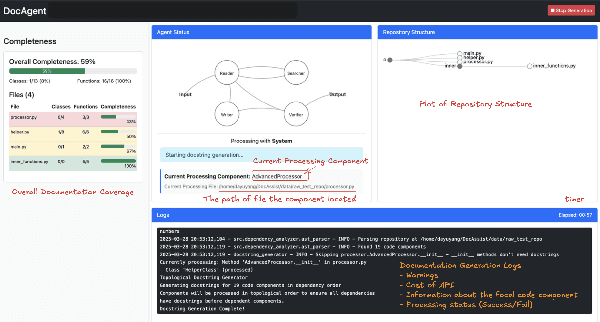

High-quality code documentation is crucial for software development especially in the era of AI. However, generating it automatically using Large Language Models (LLMs) remains challenging, as existing approaches often produce incomplete, unhelpful, or factually incorrect outputs. We introduce DocAgent, a novel multi-agent collaborative system using topological code processing for incremental context building. Specialized agents (Reader, Searcher, Writer, Verifier, Orchestrator) then collaboratively generate documentation. We also propose a multi-faceted evaluation framework assessing Completeness, Helpfulness, and Truthfulness. Comprehensive experiments show DocAgent significantly outperforms baselines consistently. Our ablation study confirms the vital role of the topological processing order. DocAgent offers a robust approach for reliable code documentation generation in complex and proprietary repositories.
Code to Think, Think to Code: A Survey on Code-Enhanced Reasoning and Reasoning-Driven Code Intelligence in LLMs
Feb 26, 2025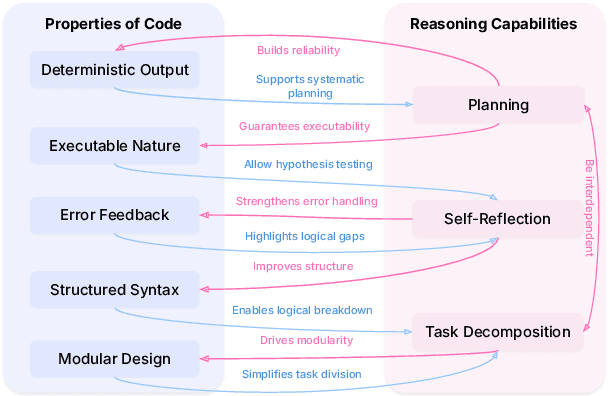
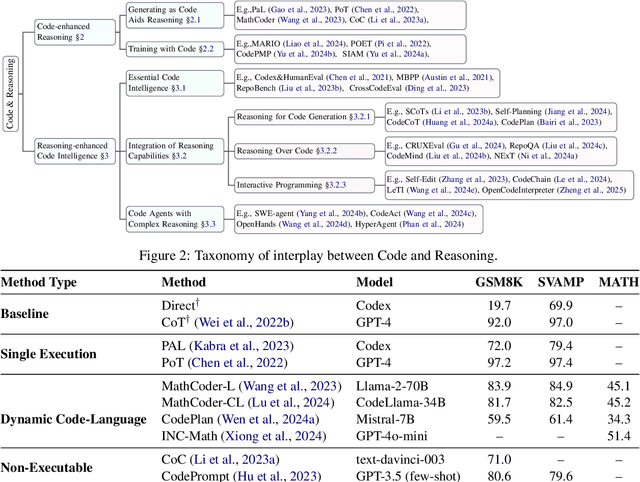


In large language models (LLMs), code and reasoning reinforce each other: code offers an abstract, modular, and logic-driven structure that supports reasoning, while reasoning translates high-level goals into smaller, executable steps that drive more advanced code intelligence. In this study, we examine how code serves as a structured medium for enhancing reasoning: it provides verifiable execution paths, enforces logical decomposition, and enables runtime validation. We also explore how improvements in reasoning have transformed code intelligence from basic completion to advanced capabilities, enabling models to address complex software engineering tasks through planning and debugging. Finally, we identify key challenges and propose future research directions to strengthen this synergy, ultimately improving LLM's performance in both areas.
Memory-Efficient Fine-Tuning of Transformers via Token Selection
Jan 31, 2025



Fine-tuning provides an effective means to specialize pre-trained models for various downstream tasks. However, fine-tuning often incurs high memory overhead, especially for large transformer-based models, such as LLMs. While existing methods may reduce certain parts of the memory required for fine-tuning, they still require caching all intermediate activations computed in the forward pass to update weights during the backward pass. In this work, we develop TokenTune, a method to reduce memory usage, specifically the memory to store intermediate activations, in the fine-tuning of transformer-based models. During the backward pass, TokenTune approximates the gradient computation by backpropagating through just a subset of input tokens. Thus, with TokenTune, only a subset of intermediate activations are cached during the forward pass. Also, TokenTune can be easily combined with existing methods like LoRA, further reducing the memory cost. We evaluate our approach on pre-trained transformer models with up to billions of parameters, considering the performance on multiple downstream tasks such as text classification and question answering in a few-shot learning setup. Overall, TokenTune achieves performance on par with full fine-tuning or representative memory-efficient fine-tuning methods, while greatly reducing the memory footprint, especially when combined with other methods with complementary memory reduction mechanisms. We hope that our approach will facilitate the fine-tuning of large transformers, in specializing them for specific domains or co-training them with other neural components from a larger system. Our code is available at https://github.com/facebookresearch/tokentune.
Forward Learning of Graph Neural Networks
Mar 16, 2024Graph neural networks (GNNs) have achieved remarkable success across a wide range of applications, such as recommendation, drug discovery, and question answering. Behind the success of GNNs lies the backpropagation (BP) algorithm, which is the de facto standard for training deep neural networks (NNs). However, despite its effectiveness, BP imposes several constraints, which are not only biologically implausible, but also limit the scalability, parallelism, and flexibility in learning NNs. Examples of such constraints include storage of neural activities computed in the forward pass for use in the subsequent backward pass, and the dependence of parameter updates on non-local signals. To address these limitations, the forward-forward algorithm (FF) was recently proposed as an alternative to BP in the image classification domain, which trains NNs by performing two forward passes over positive and negative data. Inspired by this advance, we propose ForwardGNN in this work, a new forward learning procedure for GNNs, which avoids the constraints imposed by BP via an effective layer-wise local forward training. ForwardGNN extends the original FF to deal with graph data and GNNs, and makes it possible to operate without generating negative inputs (hence no longer forward-forward). Further, ForwardGNN enables each layer to learn from both the bottom-up and top-down signals without relying on the backpropagation of errors. Extensive experiments on real-world datasets show the effectiveness and generality of the proposed forward graph learning framework. We release our code at https://github.com/facebookresearch/forwardgnn.