 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALL-E: A Foley Sound Synthesis Model and Strategies
Jun 16, 2023This paper introduces FALL-E, a foley synthesis system and its training/inference strategies. The FALL-E model employs a cascaded approach comprising low-resolution spectrogram generation, spectrogram super-resolution, and a vocoder. We trained every sound-related model from scratch using our extensive datasets, and utilized a pre-trained language model. We conditioned the model with dataset-specific texts, enabling it to learn sound quality and recording environment based on text input. Moreover, we leveraged external language models to improve text descriptions of our datasets and performed prompt engineering for quality, coherence, and diversity. FALL-E was evaluated by an objective measure as well as listening tests in the DCASE 2023 challenge Task 7. The submission achieved the second place on average, while achieving the best score for diversity, second place for audio quality, and third place for class fitness.
Room Impulse Response Estimation in a Multiple Source Environment
May 25, 2023



In real-world acoustic scenarios, there often are multiple sound sources present in a room. These sources are situated in various locations and produce sounds that reach the listener from multiple directions. The presence of multiple sources in a room creates new challenges in estimating the room impulse response (RIR) as each source has a unique RIR, dependent on its location and orientation. Therefore, issues of determining which RIR should be predicted and how to predict it arise, when the input signal is a mixture of multiple reverberated sources. To address these, we propose a new task of predicting a "representative" RIR for a room in a multiple source environment and present a training method to achieve this goal. In contrast to the model trained in a single source environment, our method shows robust performance, regardless of the number of sources in the environment.
PocketVAE: A Two-step Model for Groove Generation and Control
Jul 11, 2021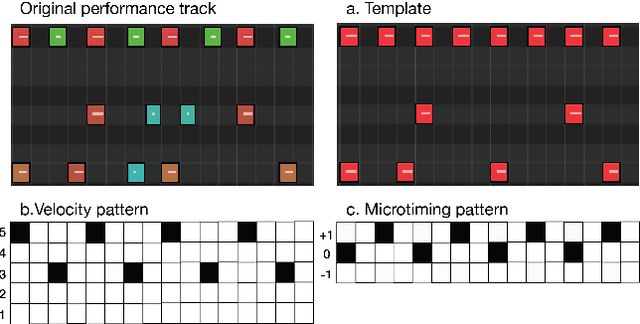

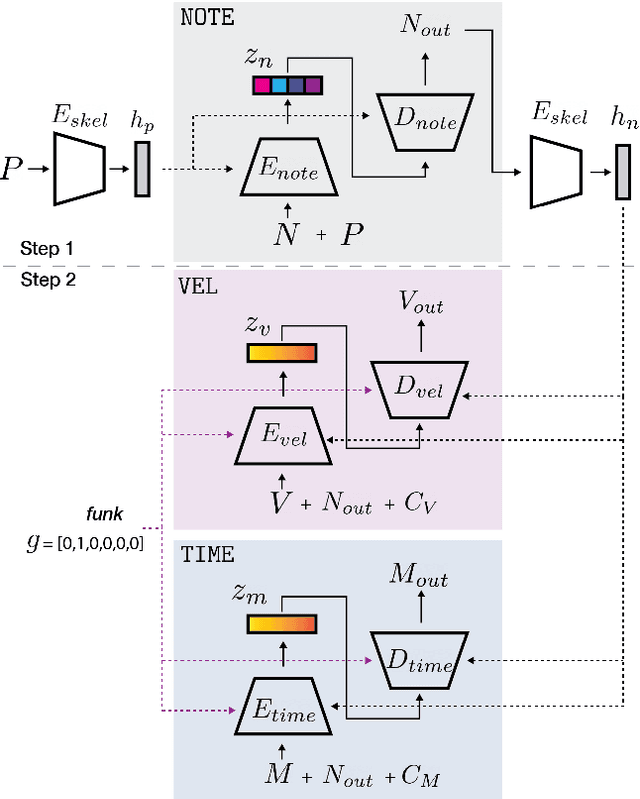
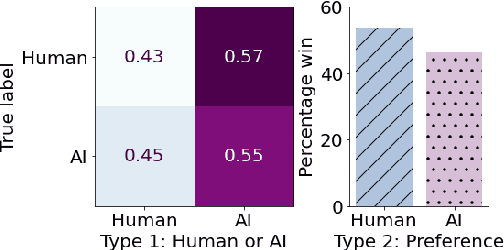
Creating a good drum track to imitate a skilled performer in digital audio workstations (DAWs) can be a time-consuming process, especially for those unfamiliar with drums. In this work, we introduce PocketVAE, a groove generation system that applies grooves to users' rudimentary MIDI tracks, i.e, templates. Grooves can be either transferred from a reference track, generated randomly or with conditions, such as genres. Our system, consisting of different modules for each groove component, takes a two-step approach that is analogous to a music creation process. First, the note module updates the user template through addition and deletion of notes; Second, the velocity and microtiming modules add details to this generated note score. In order to model the drum notes, we apply a discrete latent representation method via Vector Quantized Variational Autoencoder (VQ-VAE), as drum notes have a discrete property, unlike velocity and microtiming values. We show that our two-step approach and the usage of a discrete encoding space improves the learning of the original data distribution. Additionally, we discuss the benefit of incorporating control elements - genre, velocity and microtiming patterns - into the model.
Deep Content-User Embedding Model for Music Recommendation
Jul 18, 2018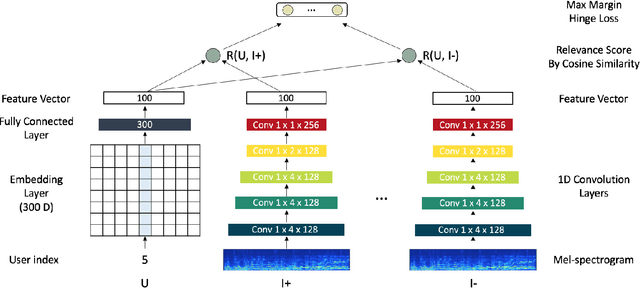


Recently deep learning based recommendation systems have been actively explored to solve the cold-start problem using a hybrid approach. However, the majority of previous studies proposed a hybrid model where collaborative filtering and content-based filtering modules are independently trained. The end-to-end approach that takes different modality data as input and jointly trains the model can provide better optimization but it has not been fully explored yet. In this work, we propose deep content-user embedding model, a simple and intuitive architecture that combines the user-item interaction and music audio content. We evaluate the model on music recommendation and music auto-tagging tasks. The results show that the proposed model significantly outperforms the previous work. We also discuss various directions to improve the proposed model further.