 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Label Transfer from Frame-Level to Note-Level in a Teacher-Student Framework for Singing Transcription from Polyphonic Music
Mar 30, 2022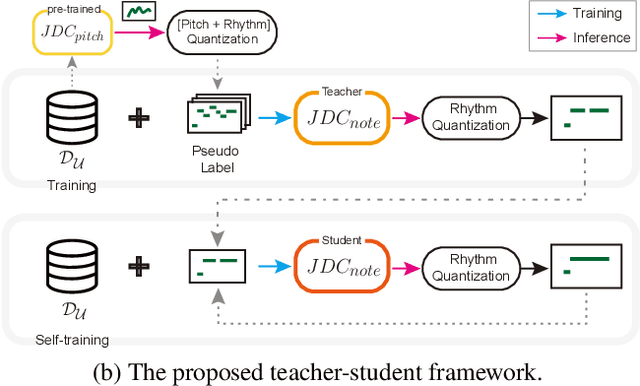
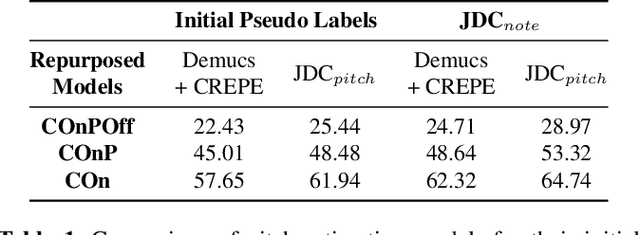
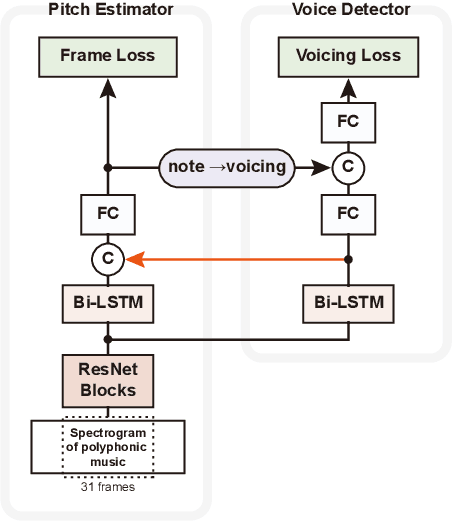
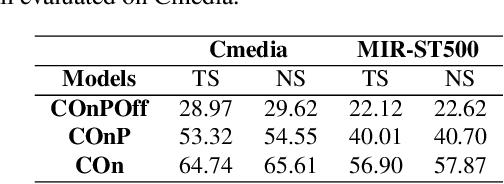
Lack of large-scale note-level labeled data is the major obstacle to singing transcription from polyphonic music. We address the issue by using pseudo labels from vocal pitch estimation models given unlabeled data. The proposed method first converts the frame-level pseudo labels to note-level through pitch and rhythm quantization steps. Then, it further improves the label quality through self-training in a teacher-student framework. To validate the method, we conduct various experiment settings by investigating two vocal pitch estimation models as pseudo-label generators, two setups of teacher-student frameworks, and the number of iterations in self-training. The results show that the proposed method can effectively leverage large-scale unlabeled audio data and self-training with the noisy student model helps to improve performance. Finally, we show that the model trained with only unlabeled data has comparable performance to previous works and the model trained with additional labeled data achieves higher accuracy than the model trained with only labeled data.
Sample-level Deep Convolutional Neural Networks for Music Auto-tagging Using Raw Waveforms
May 22, 2017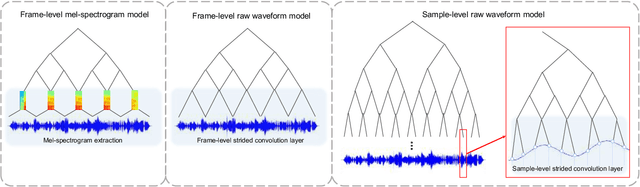
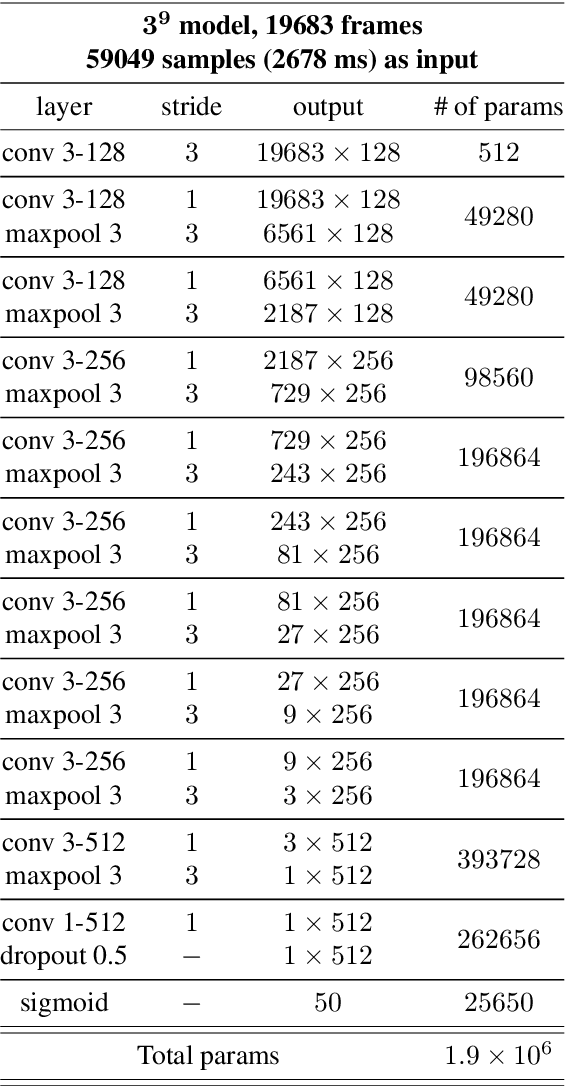

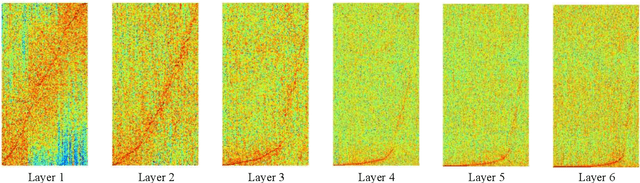
Recently, the end-to-end approach that learns hierarchical representations from raw data using deep convolutional neural networks has been successfully explored in the image, text and speech domains. This approach was applied to musical signals as well but has been not fully explored yet. To this end, we propose sample-level deep convolutional neural networks which learn representations from very small grains of waveforms (e.g. 2 or 3 samples) beyond typical frame-level input representations. Our experiments show how deep architectures with sample-level filters improve the accuracy in music auto-tagging and they provide results comparable to previous state-of-the-art performances for the Magnatagatune dataset and Million Song Dataset. In addition, we visualize filters learned in a sample-level DCNN in each layer to identify hierarchically learned features and show that they are sensitive to log-scaled frequency along layer, such as mel-frequency spectrogram that is widely used in music classification systems.