 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Label Transfer from Frame-Level to Note-Level in a Teacher-Student Framework for Singing Transcription from Polyphonic Music
Mar 30, 2022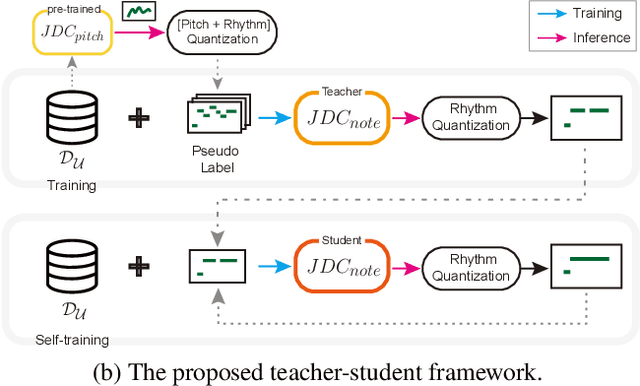
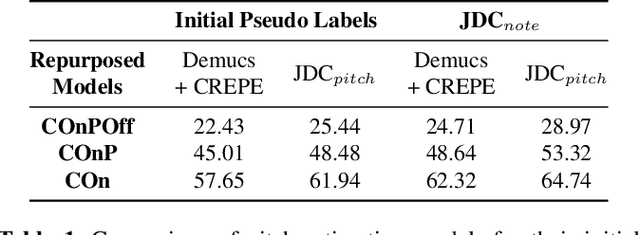
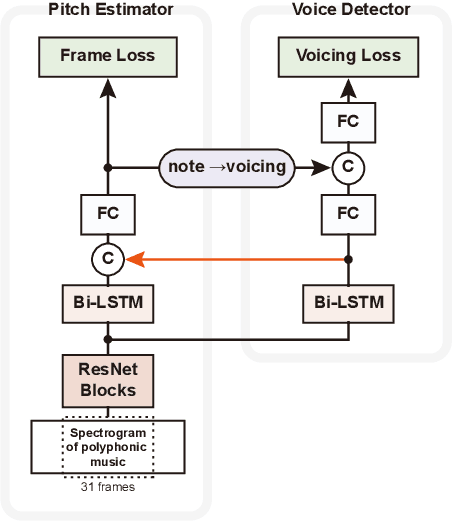
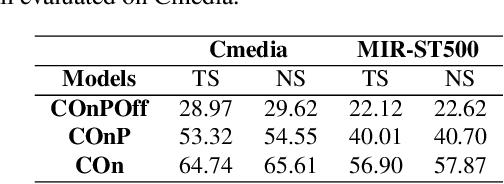
Lack of large-scale note-level labeled data is the major obstacle to singing transcription from polyphonic music. We address the issue by using pseudo labels from vocal pitch estimation models given unlabeled data. The proposed method first converts the frame-level pseudo labels to note-level through pitch and rhythm quantization steps. Then, it further improves the label quality through self-training in a teacher-student framework. To validate the method, we conduct various experiment settings by investigating two vocal pitch estimation models as pseudo-label generators, two setups of teacher-student frameworks, and the number of iterations in self-training. The results show that the proposed method can effectively leverage large-scale unlabeled audio data and self-training with the noisy student model helps to improve performance. Finally, we show that the model trained with only unlabeled data has comparable performance to previous works and the model trained with additional labeled data achieves higher accuracy than the model trained with only labeled data.