 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Temporal Consistency through Semantic Similarity Propagation in Semi-Supervised Video Semantic Segmentation for Autonomous Flight
Mar 19, 2025



Semantic segmentation from RGB cameras is essential to the perception of autonomous flying vehicles. The stability of predictions through the captured videos is paramount to their reliability and, by extension, to the trustworthiness of the agents. In this paper, we propose a lightweight video semantic segmentation approach-suited to onboard real-time inference-achieving high temporal consistency on aerial data through Semantic Similarity Propagation across frames. SSP temporally propagates the predictions of an efficient image segmentation model with global registration alignment to compensate for camera movements. It combines the current estimation and the prior prediction with linear interpolation using weights computed from the features similarities of the two frames. Because data availability is a challenge in this domain, we propose a consistency-aware Knowledge Distillation training procedure for sparsely labeled datasets with few annotations. Using a large image segmentation model as a teacher to train the efficient SSP, we leverage the strong correlations between labeled and unlabeled frames in the same training videos to obtain high-quality supervision on all frames. KD-SSP obtains a significant temporal consistency increase over the base image segmentation model of 12.5% and 6.7% TC on UAVid and RuralScapes respectively, with higher accuracy and comparable inference speed. On these aerial datasets, KD-SSP provides a superior segmentation quality and inference speed trade-off than other video methods proposed for general applications and shows considerably higher consistency. The code will be made publicly available upon acceptance.
Pseudo-Label Transfer from Frame-Level to Note-Level in a Teacher-Student Framework for Singing Transcription from Polyphonic Music
Mar 30, 2022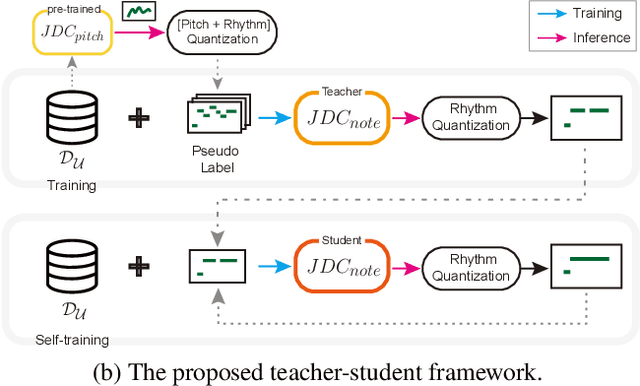
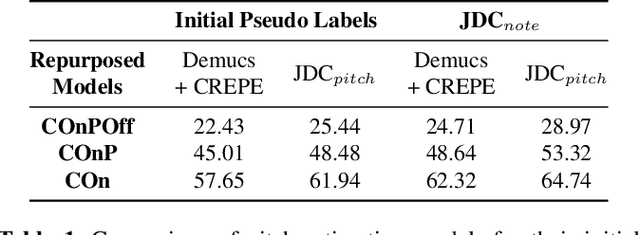
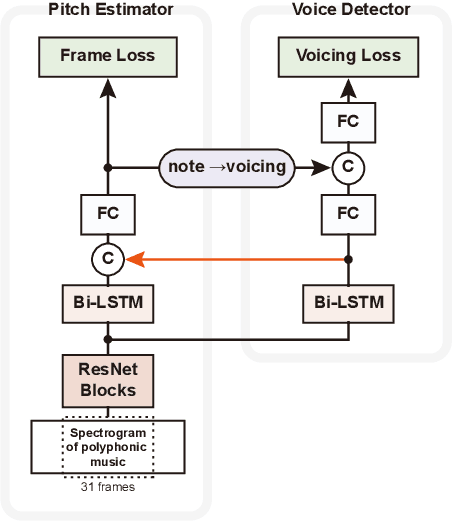
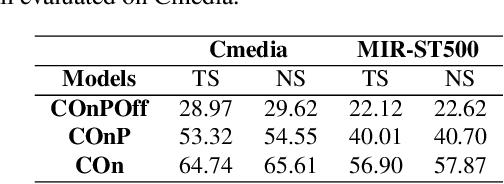
Lack of large-scale note-level labeled data is the major obstacle to singing transcription from polyphonic music. We address the issue by using pseudo labels from vocal pitch estimation models given unlabeled data. The proposed method first converts the frame-level pseudo labels to note-level through pitch and rhythm quantization steps. Then, it further improves the label quality through self-training in a teacher-student framework. To validate the method, we conduct various experiment settings by investigating two vocal pitch estimation models as pseudo-label generators, two setups of teacher-student frameworks, and the number of iterations in self-training. The results show that the proposed method can effectively leverage large-scale unlabeled audio data and self-training with the noisy student model helps to improve performance. Finally, we show that the model trained with only unlabeled data has comparable performance to previous works and the model trained with additional labeled data achieves higher accuracy than the model trained with only labeled data.