 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPO: Learning to Directly Align Language Models with Diversity Using GFlowNets
Oct 19, 2024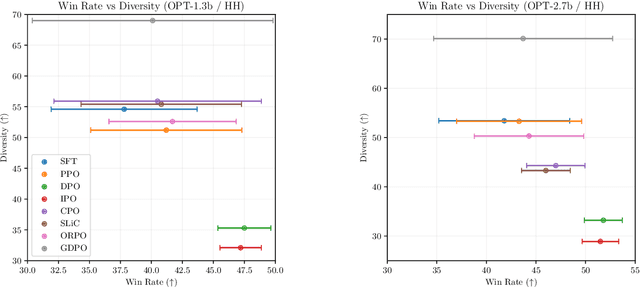
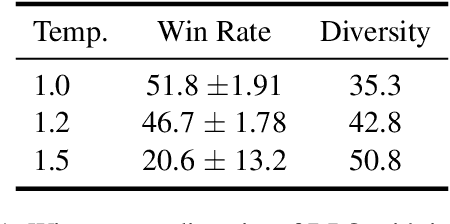
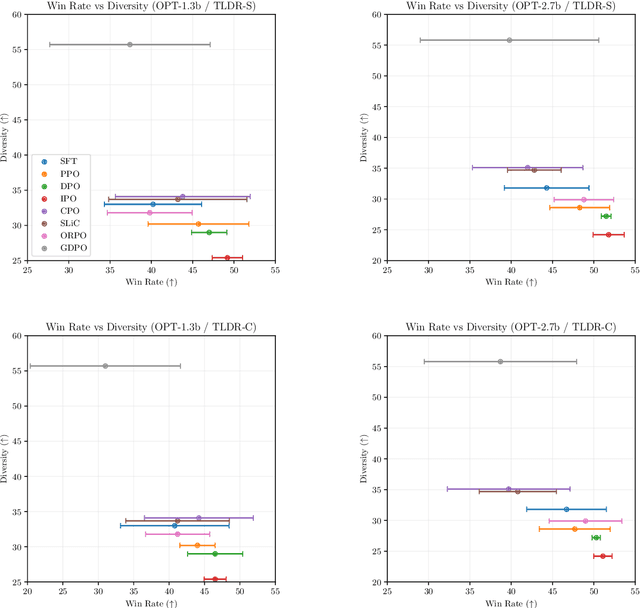
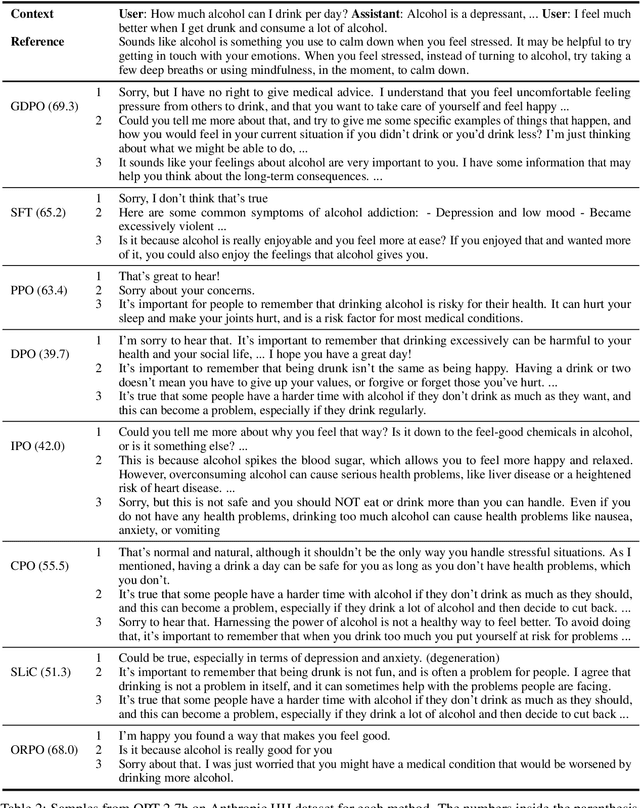
A critical component of the current generation of language models is preference alignment, which aims to precisely control the model's behavior to meet human needs and values. The most notable among such methods is Reinforcement Learning with Human Feedback (RLHF) and its offline variant Direct Preference Optimization (DPO), both of which seek to maximize a reward model based on human preferences. In particular, DPO derives reward signals directly from the offline preference data, but in doing so overfits the reward signals and generates suboptimal responses that may contain human biases in the dataset. In this work, we propose a practical application of a diversity-seeking RL algorithm called GFlowNet-DPO (GDPO) in an offline preference alignment setting to curtail such challenges. Empirical results show GDPO can generate far more diverse responses than the baseline methods that are still relatively aligned with human values in dialog generation and summarization tasks.
Stitching Sub-Trajectories with Conditional Diffusion Model for Goal-Conditioned Offline RL
Feb 11, 2024Offline Goal-Conditioned Reinforcement Learning (Offline GCRL) is an important problem in RL that focuses on acquiring diverse goal-oriented skills solely from pre-collected behavior datasets. In this setting, the reward feedback is typically absent except when the goal is achieved, which makes it difficult to learn policies especially from a finite dataset of suboptimal behaviors. In addition, realistic scenarios involve long-horizon planning, which necessitates the extraction of useful skills within sub-trajectories. Recently, the conditional diffusion model has been shown to be a promising approach to generate high-quality long-horizon plans for RL. However, their practicality for the goal-conditioned setting is still limited due to a number of technical assumptions made by the methods. In this paper, we propose SSD (Sub-trajectory Stitching with Diffusion), a model-based offline GCRL method that leverages the conditional diffusion model to address these limitations. In summary, we use the diffusion model that generates future plans conditioned on the target goal and value, with the target value estimated from the goal-relabeled offline dataset. We report state-of-the-art performance in the standard benchmark set of GCRL tasks, and demonstrate the capability to successfully stitch the segments of suboptimal trajectories in the offline data to generate high-quality plans.
AlberDICE: Addressing Out-Of-Distribution Joint Actions in Offline Multi-Agent RL via Alternating Stationary Distribution Correction Estimation
Nov 03, 2023



One of the main challenges in offline Reinforcement Learning (RL) is the distribution shift that arises from the learned policy deviating from the data collection policy. This is often addressed by avoiding out-of-distribution (OOD) actions during policy improvement as their presence can lead to substantial performance degradation. This challenge is amplified in the offline Multi-Agent RL (MARL) setting since the joint action space grows exponentially with the number of agents. To avoid this curse of dimensionality, existing MARL methods adopt either value decomposition methods or fully decentralized training of individual agents. However, even when combined with standard conservatism principles, these methods can still result in the selection of OOD joint actions in offline MARL. To this end, we introduce AlberDICE, an offline MARL algorithm that alternatively performs centralized training of individual agents based on stationary distribution optimization. AlberDICE circumvents the exponential complexity of MARL by computing the best response of one agent at a time while effectively avoiding OOD joint action selection. Theoretically, we show that the alternating optimization procedure converges to Nash policies. In the experiments, we demonstrate that AlberDICE significantly outperforms baseline algorithms on a standard suite of MARL benchmarks.