 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Pattern Detection via Template Matching and Regression
Aug 25, 2025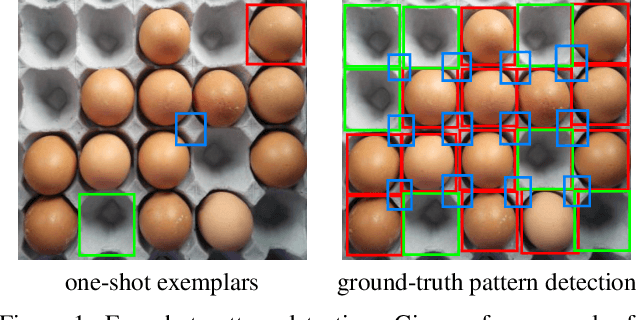


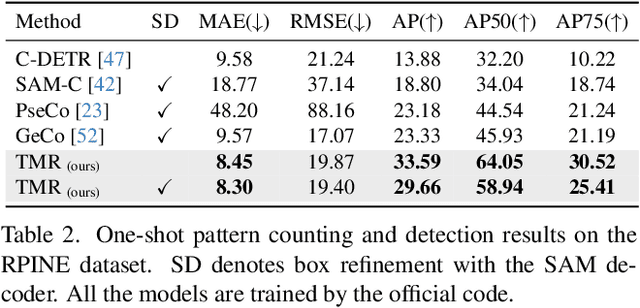
We address the problem of few-shot pattern detection, which aims to detect all instances of a given pattern, typically represented by a few exemplars, from an input image. Although similar problems have been studied in few-shot object counting and detection (FSCD), previous methods and their benchmarks have narrowed patterns of interest to object categories and often fail to localize non-object patterns. In this work, we propose a simple yet effective detector based on template matching and regression, dubbed TMR. While previous FSCD methods typically represent target exemplars as spatially collapsed prototypes and lose structural information, we revisit classic template matching and regression. It effectively preserves and leverages the spatial layout of exemplars through a minimalistic structure with a small number of learnable convolutional or projection layers on top of a frozen backbone We also introduce a new dataset, dubbed RPINE, which covers a wider range of patterns than existing object-centric datasets. Our method outperforms the state-of-the-art methods on the three benchmarks, RPINE, FSCD-147, and FSCD-LVIS, and demonstrates strong generalization in cross-dataset evaluation.
Hard Prompts Made Interpretable: Sparse Entropy Regularization for Prompt Tuning with RL
Jul 20, 2024With the advent of foundation models, prompt tuning has positioned itself as an important technique for directing model behaviors and eliciting desired responses. Prompt tuning regards selecting appropriate keywords included into the input, thereby adapting to the downstream task without adjusting or fine-tuning the model parameters. There is a wide range of work in prompt tuning, from approaches that directly harness the backpropagated gradient signals from the model, to those employing black-box optimization such as reinforcement learning (RL) methods. Our primary focus is on RLPrompt, which aims to find optimal prompt tokens leveraging soft Q-learning. While the results show promise, we have observed that the prompts frequently appear unnatural, which impedes their interpretability. We address this limitation by using sparse Tsallis entropy regularization, a principled approach to filtering out unlikely tokens from consideration. We extensively evaluate our approach across various tasks, including few-shot text classification, unsupervised text style transfer, and textual inversion from images. The results indicate a notable improvement over baselines, highlighting the efficacy of our approach in addressing the challenges of prompt tuning. Moreover, we show that the prompts discovered using our method are more natural and interpretable compared to those from other baselines.
Stitching Sub-Trajectories with Conditional Diffusion Model for Goal-Conditioned Offline RL
Feb 11, 2024Offline Goal-Conditioned Reinforcement Learning (Offline GCRL) is an important problem in RL that focuses on acquiring diverse goal-oriented skills solely from pre-collected behavior datasets. In this setting, the reward feedback is typically absent except when the goal is achieved, which makes it difficult to learn policies especially from a finite dataset of suboptimal behaviors. In addition, realistic scenarios involve long-horizon planning, which necessitates the extraction of useful skills within sub-trajectories. Recently, the conditional diffusion model has been shown to be a promising approach to generate high-quality long-horizon plans for RL. However, their practicality for the goal-conditioned setting is still limited due to a number of technical assumptions made by the methods. In this paper, we propose SSD (Sub-trajectory Stitching with Diffusion), a model-based offline GCRL method that leverages the conditional diffusion model to address these limitations. In summary, we use the diffusion model that generates future plans conditioned on the target goal and value, with the target value estimated from the goal-relabeled offline dataset. We report state-of-the-art performance in the standard benchmark set of GCRL tasks, and demonstrate the capability to successfully stitch the segments of suboptimal trajectories in the offline data to generate high-quality plans.
Local Metric Learning for Off-Policy Evaluation in Contextual Bandits with Continuous Actions
Oct 25, 2022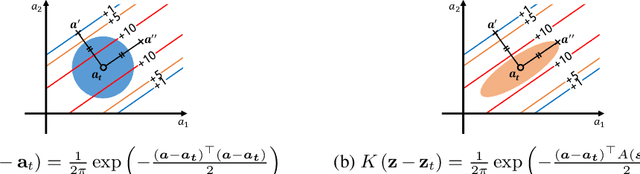
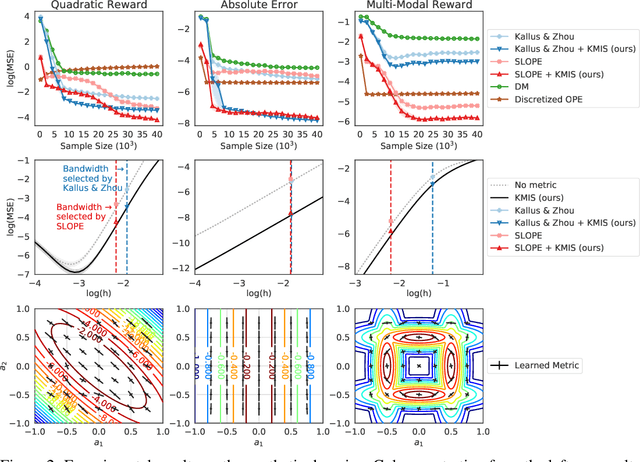
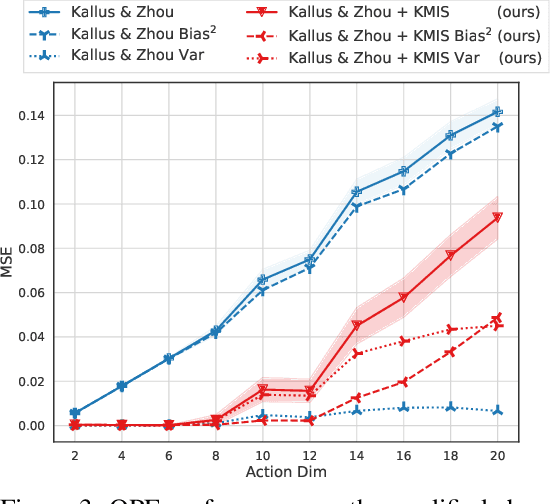
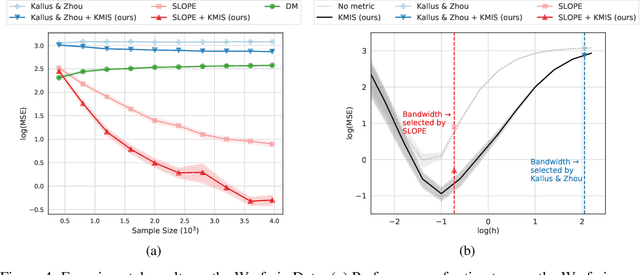
We consider local kernel metric learning for off-policy evaluation (OPE) of deterministic policies in contextual bandits with continuous action spaces. Our work is motivated by practical scenarios where the target policy needs to be deterministic due to domain requirements, such as prescription of treatment dosage and duration in medicine. Although importance sampling (IS) provides a basic principle for OPE, it is ill-posed for the deterministic target policy with continuous actions. Our main idea is to relax the target policy and pose the problem as kernel-based estimation, where we learn the kernel metric in order to minimize the overall mean squared error (MSE). We present an analytic solution for the optimal metric, based on the analysis of bias and variance. Whereas prior work has been limited to scalar action spaces or kernel bandwidth selection, our work takes a step further being capable of vector action spaces and metric optimization. We show that our estimator is consistent, and significantly reduces the MSE compared to baseline OPE methods through experiments on various domains.