 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaw Produce Quality Detection with Shifted Window Self-Attention
Paper and Code
Dec 24, 2021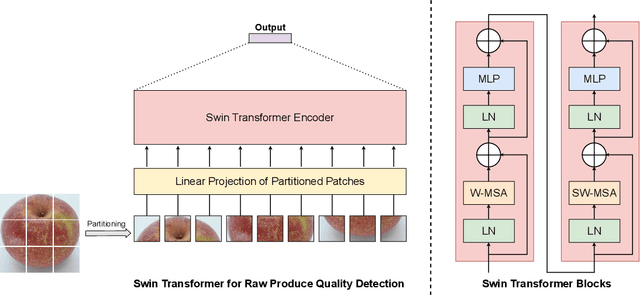
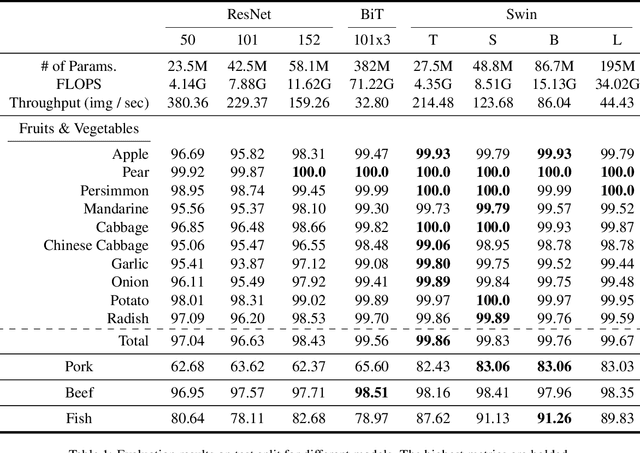
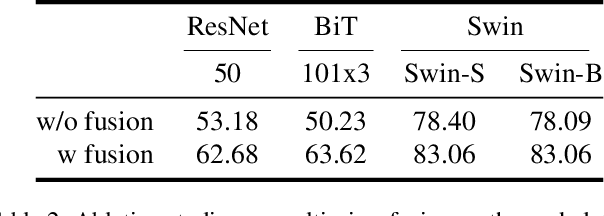
Global food insecurity is expected to worsen in the coming decades with the accelerated rate of climate change and the rapidly increasing population. In this vein, it is important to remove inefficiencies at every level of food production. The recent advances in deep learning can help reduce such inefficiencies, yet their application has not yet become mainstream throughout the industry, inducing economic costs at a massive scale. To this point, modern techniques such as CNNs (Convolutional Neural Networks) have been applied to RPQD (Raw Produce Quality Detection) tasks. On the other hand, Transformer's successful debut in the vision among other modalities led us to expect a better performance with these Transformer-based models in RPQD. In this work, we exclusively investigate the recent state-of-the-art Swin (Shifted Windows) Transformer which computes self-attention in both intra- and inter-window fashion. We compare Swin Transformer against CNN models on four RPQD image datasets, each containing different kinds of raw produce: fruits and vegetables, fish, pork, and beef. We observe that Swin Transformer not only achieves better or competitive performance but also is data- and compute-efficient, making it ideal for actual deployment in real-world setting. To the best of our knowledge, this is the first large-scale empirical study on RPQD task, which we hope will gain more attention in future works.