 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval
Mar 10, 2026Recent advances in Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) have enabled diverse retrieval methods. However, existing retrieval methods often fail to accurately retrieve results for negation and exclusion queries. To address this limitation, prior approaches rely on embedding adaptation or fine-tuning, which introduce additional computational cost and deployment complexity. We propose Direct Embedding Optimization (DEO), a training-free method for negation-aware text and multimodal retrieval. DEO decomposes queries into positive and negative components and optimizes the query embedding with a contrastive objective. Without additional training data or model updates, DEO outperforms baselines on NegConstraint, with gains of +0.0738 nDCG@10 and +0.1028 MAP@100, while improving Recall@5 by +6\% over OpenAI CLIP in multimodal retrieval. These results demonstrate the practicality of DEO for negation- and exclusion-aware retrieval in real-world settings.
Kiss up, Kick down: Exploring Behavioral Changes in Multi-modal Large Language Models with Assigned Visual Personas
Oct 04, 2024



This study is the first to explore whether multi-modal large language models (LLMs) can align their behaviors with visual personas, addressing a significant gap in the literature that predominantly focuses on text-based personas. We developed a novel dataset of 5K fictional avatar images for assignment as visual personas to LLMs, and analyzed their negotiation behaviors based on the visual traits depicted in these images, with a particular focus on aggressiveness. The results indicate that LLMs assess the aggressiveness of images in a manner similar to humans and output more aggressive negotiation behaviors when prompted with an aggressive visual persona. Interestingly, the LLM exhibited more aggressive negotiation behaviors when the opponent's image appeared less aggressive than their own, and less aggressive behaviors when the opponents image appeared more aggressive.
Adapting Text-based Dialogue State Tracker for Spoken Dialogues
Aug 30, 2023



Although there have been remarkable advances in dialogue systems through the dialogue systems technology competition (DSTC), it remains one of the key challenges to building a robust task-oriented dialogue system with a speech interface. Most of the progress has been made for text-based dialogue systems since there are abundant datasets with written corpora while those with spoken dialogues are very scarce. However, as can be seen from voice assistant systems such as Siri and Alexa, it is of practical importance to transfer the success to spoken dialogues. In this paper, we describe our engineering effort in building a highly successful model that participated in the speech-aware dialogue systems technology challenge track in DSTC11. Our model consists of three major modules: (1) automatic speech recognition error correction to bridge the gap between the spoken and the text utterances, (2) text-based dialogue system (D3ST) for estimating the slots and values using slot descriptions, and (3) post-processing for recovering the error of the estimated slot value. Our experiments show that it is important to use an explicit automatic speech recognition error correction module, post-processing, and data augmentation to adapt a text-based dialogue state tracker for spoken dialogue corpora.
Refine Myself by Teaching Myself: Feature Refinement via Self-Knowledge Distillation
Mar 15, 2021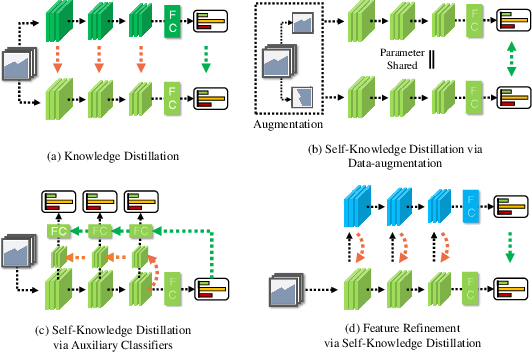
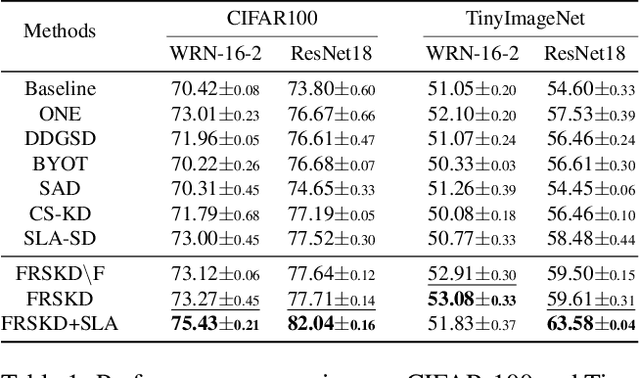
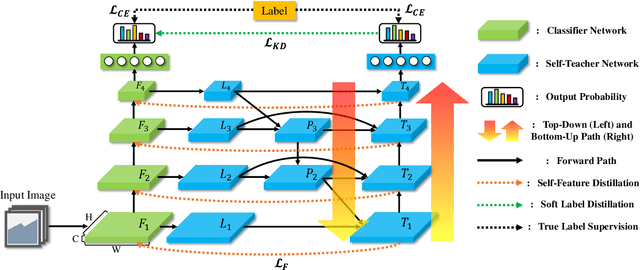
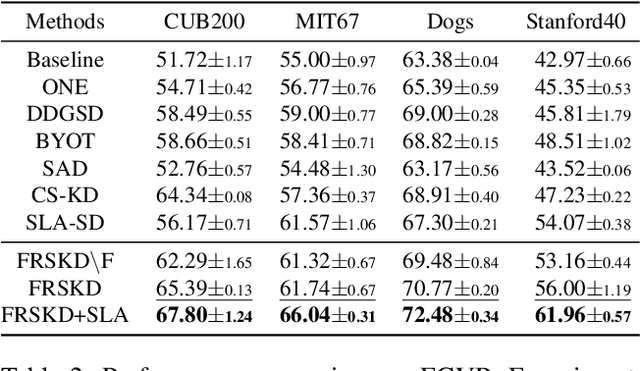
Knowledge distillation is a method of transferring the knowledge from a pretrained complex teacher model to a student model, so a smaller network can replace a large teacher network at the deployment stage. To reduce the necessity of training a large teacher model, the recent literatures introduced a self-knowledge distillation, which trains a student network progressively to distill its own knowledge without a pretrained teacher network. While Self-knowledge distillation is largely divided into a data augmentation based approach and an auxiliary network based approach, the data augmentation approach looses its local information in the augmentation process, which hinders its applicability to diverse vision tasks, such as semantic segmentation. Moreover, these knowledge distillation approaches do not receive the refined feature maps, which are prevalent in the object detection and semantic segmentation community. This paper proposes a novel self-knowledge distillation method, Feature Refinement via Self-Knowledge Distillation (FRSKD), which utilizes an auxiliary self-teacher network to transfer a refined knowledge for the classifier network. Our proposed method, FRSKD, can utilize both soft label and feature-map distillations for the self-knowledge distillation. Therefore, FRSKD can be applied to classification, and semantic segmentation, which emphasize preserving the local information. We demonstrate the effectiveness of FRSKD by enumerating its performance improvements in diverse tasks and benchmark datasets. The implemented code is available at https://github.com/MingiJi/FRSKD.