 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-Safe Pre-Training for Robust 4-Bit Quantization of Large Language Models
Jun 24, 2025Extreme activation outliers in Large Language Models (LLMs) critically degrade quantization performance, hindering efficient on-device deployment. While channel-wise operations and adaptive gradient scaling are recognized causes, practical mitigation remains challenging. We introduce Outlier-Safe Pre-Training (OSP), a practical guideline that proactively prevents outlier formation rather than relying on post-hoc mitigation. OSP combines three key innovations: (1) the Muon optimizer, eliminating privileged bases while maintaining training efficiency; (2) Single-Scale RMSNorm, preventing channel-wise amplification; and (3) a learnable embedding projection, redistributing activation magnitudes originating from embedding matrices. We validate OSP by training a 1.4B-parameter model on 1 trillion tokens, which is the first production-scale LLM trained without such outliers. Under aggressive 4-bit quantization, our OSP model achieves a 35.7 average score across 10 benchmarks (compared to 26.5 for an Adam-trained model), with only a 2% training overhead. Remarkably, OSP models exhibit near-zero excess kurtosis (0.04) compared to extreme values (1818.56) in standard models, fundamentally altering LLM quantization behavior. Our work demonstrates that outliers are not inherent to LLMs but are consequences of training strategies, paving the way for more efficient LLM deployment. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Outlier-Safe-Pre-Training.
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards
Jun 13, 2025Large language models have shown promise in clinical decision making, but current approaches struggle to localize and correct errors at specific steps of the reasoning process. This limitation is critical in medicine, where identifying and addressing reasoning errors is essential for accurate diagnosis and effective patient care. We introduce Med-PRM, a process reward modeling framework that leverages retrieval-augmented generation to verify each reasoning step against established medical knowledge bases. By verifying intermediate reasoning steps with evidence retrieved from clinical guidelines and literature, our model can precisely assess the reasoning quality in a fine-grained manner. Evaluations on five medical QA benchmarks and two open-ended diagnostic tasks demonstrate that Med-PRM achieves state-of-the-art performance, with improving the performance of base models by up to 13.50% using Med-PRM. Moreover, we demonstrate the generality of Med-PRM by integrating it in a plug-and-play fashion with strong policy models such as Meerkat, achieving over 80\% accuracy on MedQA for the first time using small-scale models of 8 billion parameters. Our code and data are available at: https://med-prm.github.io/
Does Time Have Its Place? Temporal Heads: Where Language Models Recall Time-specific Information
Feb 20, 2025



While the ability of language models to elicit facts has been widely investigated, how they handle temporally changing facts remains underexplored. We discover Temporal Heads, specific attention heads primarily responsible for processing temporal knowledge through circuit analysis. We confirm that these heads are present across multiple models, though their specific locations may vary, and their responses differ depending on the type of knowledge and its corresponding years. Disabling these heads degrades the model's ability to recall time-specific knowledge while maintaining its general capabilities without compromising time-invariant and question-answering performances. Moreover, the heads are activated not only numeric conditions ("In 2004") but also textual aliases ("In the year ..."), indicating that they encode a temporal dimension beyond simple numerical representation. Furthermore, we expand the potential of our findings by demonstrating how temporal knowledge can be edited by adjusting the values of these heads.
Monet: Mixture of Monosemantic Experts for Transformers
Dec 05, 2024



Understanding the internal computations of large language models (LLMs) is crucial for aligning them with human values and preventing undesirable behaviors like toxic content generation. However, mechanistic interpretability is hindered by polysemanticity -- where individual neurons respond to multiple, unrelated concepts. While Sparse Autoencoders (SAEs) have attempted to disentangle these features through sparse dictionary learning, they have compromised LLM performance due to reliance on post-hoc reconstruction loss. To address this issue, we introduce Mixture of Monosemantic Experts for Transformers (Monet) architecture, which incorporates sparse dictionary learning directly into end-to-end Mixture-of-Experts pretraining. Our novel expert decomposition method enables scaling the expert count to 262,144 per layer while total parameters scale proportionally to the square root of the number of experts. Our analyses demonstrate mutual exclusivity of knowledge across experts and showcase the parametric knowledge encapsulated within individual experts. Moreover, Monet allows knowledge manipulation over domains, languages, and toxicity mitigation without degrading general performance. Our pursuit of transparent LLMs highlights the potential of scaling expert counts to enhance} mechanistic interpretability and directly resect the internal knowledge to fundamentally adjust} model behavior. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Monet.
ChroKnowledge: Unveiling Chronological Knowledge of Language Models in Multiple Domains
Oct 13, 2024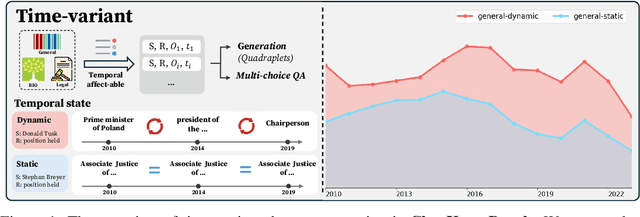


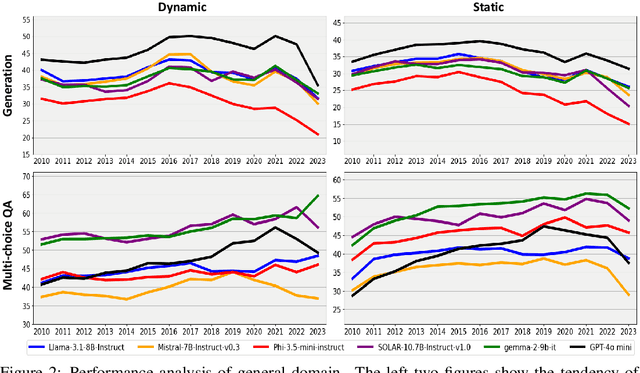
Large language models (LLMs) have significantly impacted many aspects of our lives. However, assessing and ensuring their chronological knowledge remains challenging. Existing approaches fall short in addressing the accumulative nature of knowledge, often relying on a single time stamp. To overcome this, we introduce ChroKnowBench, a benchmark dataset designed to evaluate chronologically accumulated knowledge across three key aspects: multiple domains, time dependency, temporal state. Our benchmark distinguishes between knowledge that evolves (e.g., scientific discoveries, amended laws) and knowledge that remain constant (e.g., mathematical truths, commonsense facts). Building on this benchmark, we present ChroKnowledge (Chronological Categorization of Knowledge), a novel sampling-based framework for evaluating and updating LLMs' non-parametric chronological knowledge. Our evaluation shows: (1) The ability of eliciting temporal knowledge varies depending on the data format that model was trained on. (2) LLMs partially recall knowledge or show a cut-off at temporal boundaries rather than recalling all aspects of knowledge correctly. Thus, we apply our ChroKnowPrompt, an in-depth prompting to elicit chronological knowledge by traversing step-by-step through the surrounding time spans. We observe that our framework successfully updates the overall knowledge across the entire timeline in both the biomedical domain (+11.9%) and the general domain (+2.8%), demonstrating its effectiveness in refining temporal knowledge. This non-parametric approach also enables knowledge updates not only in open-source models but also in proprietary LLMs, ensuring comprehensive applicability across model types. We perform a comprehensive analysis based on temporal characteristics of ChroKnowPrompt and validate the potential of various models to elicit intrinsic temporal knowledge through our method.
SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization
Jun 18, 2024Visual Speech Recognition (VSR) stands at the intersection of computer vision and speech recognition, aiming to interpret spoken content from visual cues. A prominent challenge in VSR is the presence of homophenes-visually similar lip gestures that represent different phonemes. Prior approaches have sought to distinguish fine-grained visemes by aligning visual and auditory semantics, but often fell short of full synchronization. To address this, we present SyncVSR, an end-to-end learning framework that leverages quantized audio for frame-level crossmodal supervision. By integrating a projection layer that synchronizes visual representation with acoustic data, our encoder learns to generate discrete audio tokens from a video sequence in a non-autoregressive manner. SyncVSR shows versatility across tasks, languages, and modalities at the cost of a forward pass. Our empirical evaluations show that it not only achieves state-of-the-art results but also reduces data usage by up to ninefold.