 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-EXAONE Technical Report
Jan 05, 2026This technical report presents K-EXAONE, a large-scale multilingual language model developed by LG AI Research. K-EXAONE is built on a Mixture-of-Experts architecture with 236B total parameters, activating 23B parameters during inference. It supports a 256K-token context window and covers six languages: Korean, English, Spanish, German, Japanese, and Vietnamese. We evaluate K-EXAONE on a comprehensive benchmark suite spanning reasoning, agentic, general, Korean, and multilingual abilities. Across these evaluations, K-EXAONE demonstrates performance comparable to open-weight models of similar size. K-EXAONE, designed to advance AI for a better life, is positioned as a powerful proprietary AI foundation model for a wide range of industrial and research applications.
Guiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment
Dec 11, 2025Despite substantial progress in text-to-image generation, achieving precise text-image alignment remains challenging, particularly for prompts with rich compositional structure or imaginative elements. To address this, we introduce Negative Prompting for Image Correction (NPC), an automated pipeline that improves alignment by identifying and applying negative prompts that suppress unintended content. We begin by analyzing cross-attention patterns to explain why both targeted negatives-those directly tied to the prompt's alignment error-and untargeted negatives-tokens unrelated to the prompt but present in the generated image-can enhance alignment. To discover useful negatives, NPC generates candidate prompts using a verifier-captioner-proposer framework and ranks them with a salient text-space score, enabling effective selection without requiring additional image synthesis. On GenEval++ and Imagine-Bench, NPC outperforms strong baselines, achieving 0.571 vs. 0.371 on GenEval++ and the best overall performance on Imagine-Bench. By guiding what not to generate, NPC provides a principled, fully automated route to stronger text-image alignment in diffusion models. Code is released at https://github.com/wiarae/NPC.
SAVE: Sparse Autoencoder-Driven Visual Information Enhancement for Mitigating Object Hallucination
Dec 11, 2025Although Multimodal Large Language Models (MLLMs) have advanced substantially, they remain vulnerable to object hallucination caused by language priors and visual information loss. To address this, we propose SAVE (Sparse Autoencoder-Driven Visual Information Enhancement), a framework that mitigates hallucination by steering the model along Sparse Autoencoder (SAE) latent features. A binary object-presence question-answering probe identifies the SAE features most indicative of the model's visual information processing, referred to as visual understanding features. Steering the model along these identified features reinforces grounded visual understanding and effectively reduces hallucination. With its simple design, SAVE outperforms state-of-the-art training-free methods on standard benchmarks, achieving a 10\%p improvement in CHAIR\_S and consistent gains on POPE and MMHal-Bench. Extensive evaluations across multiple models and layers confirm the robustness and generalizability of our approach. Further analysis reveals that steering along visual understanding features suppresses the generation of uncertain object tokens and increases attention to image tokens, mitigating hallucination. Code is released at https://github.com/wiarae/SAVE.
EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes
Jul 15, 2025This technical report introduces EXAONE 4.0, which integrates a Non-reasoning mode and a Reasoning mode to achieve both the excellent usability of EXAONE 3.5 and the advanced reasoning abilities of EXAONE Deep. To pave the way for the agentic AI era, EXAONE 4.0 incorporates essential features such as agentic tool use, and its multilingual capabilities are extended to support Spanish in addition to English and Korean. The EXAONE 4.0 model series consists of two sizes: a mid-size 32B model optimized for high performance, and a small-size 1.2B model designed for on-device applications. The EXAONE 4.0 demonstrates superior performance compared to open-weight models in its class and remains competitive even against frontier-class models. The models are publicly available for research purposes and can be easily downloaded via https://huggingface.co/LGAI-EXAONE.
EXAONE Deep: Reasoning Enhanced Language Models
Mar 16, 2025We present EXAONE Deep series, which exhibits superior capabilities in various reasoning tasks, including math and coding benchmarks. We train our models mainly on the reasoning-specialized dataset that incorporates long streams of thought processes. Evaluation results show that our smaller models, EXAONE Deep 2.4B and 7.8B, outperform other models of comparable size, while the largest model, EXAONE Deep 32B, demonstrates competitive performance against leading open-weight models. All EXAONE Deep models are openly available for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE
EXAONE 3.5: Series of Large Language Models for Real-world Use Cases
Dec 09, 2024



This technical report introduces the EXAONE 3.5 instruction-tuned language models, developed and released by LG AI Research. The EXAONE 3.5 language models are offered in three configurations: 32B, 7.8B, and 2.4B. These models feature several standout capabilities: 1) exceptional instruction following capabilities in real-world scenarios, achieving the highest scores across seven benchmarks, 2) outstanding long-context comprehension, attaining the top performance in four benchmarks, and 3) competitive results compared to state-of-the-art open models of similar sizes across nine general benchmarks. The EXAONE 3.5 language models are open to anyone for research purposes and can be downloaded from https://huggingface.co/LGAI-EXAONE. For commercial use, please reach out to the official contact point of LG AI Research: contact_us@lgresearch.ai.
Textual Training for the Hassle-Free Removal of Unwanted Visual Data
Sep 30, 2024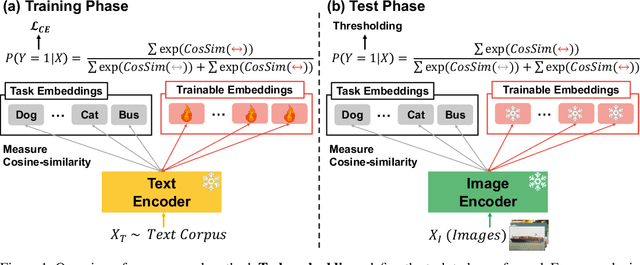
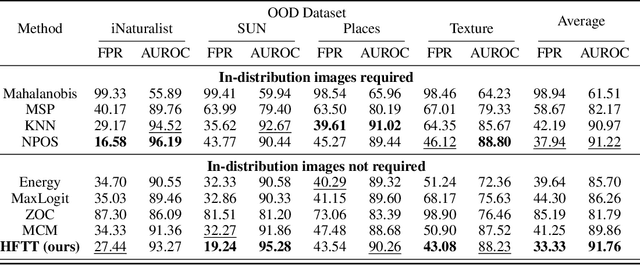
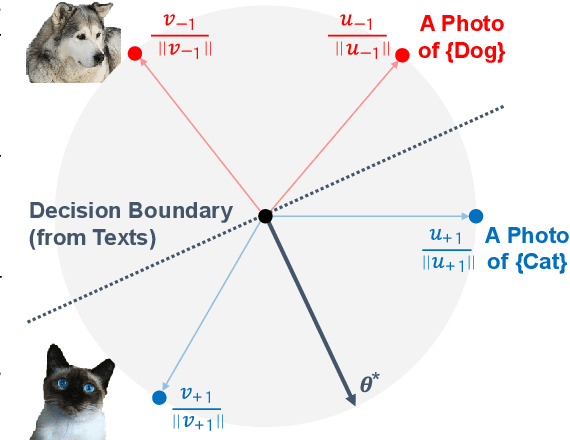
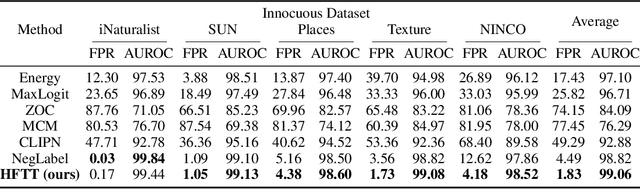
In our study, we explore methods for detecting unwanted content lurking in visual datasets. We provide a theoretical analysis demonstrating that a model capable of successfully partitioning visual data can be obtained using only textual data. Based on the analysis, we propose Hassle-Free Textual Training (HFTT), a streamlined method capable of acquiring detectors for unwanted visual content, using only synthetic textual data in conjunction with pre-trained vision-language models. HFTT features an innovative objective function that significantly reduces the necessity for human involvement in data annotation. Furthermore, HFTT employs a clever textual data synthesis method, effectively emulating the integration of unknown visual data distribution into the training process at no extra cost. The unique characteristics of HFTT extend its utility beyond traditional out-of-distribution detection, making it applicable to tasks that address more abstract concepts. We complement our analyses with experiments in out-of-distribution detection and hateful image detection. Our codes are available at https://github.com/Saehyung-Lee/HFTT
EXAONE 3.0 7.8B Instruction Tuned Language Model
Aug 07, 2024



We introduce EXAONE 3.0 instruction-tuned language model, the first open model in the family of Large Language Models (LLMs) developed by LG AI Research. Among different model sizes, we publicly release the 7.8B instruction-tuned model to promote open research and innovations. Through extensive evaluations across a wide range of public and in-house benchmarks, EXAONE 3.0 demonstrates highly competitive real-world performance with instruction-following capability against other state-of-the-art open models of similar size. Our comparative analysis shows that EXAONE 3.0 excels particularly in Korean, while achieving compelling performance across general tasks and complex reasoning. With its strong real-world effectiveness and bilingual proficiency, we hope that EXAONE keeps contributing to advancements in Expert AI. Our EXAONE 3.0 instruction-tuned model is available at https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
SyncVSR: Data-Efficient Visual Speech Recognition with End-to-End Crossmodal Audio Token Synchronization
Jun 18, 2024Visual Speech Recognition (VSR) stands at the intersection of computer vision and speech recognition, aiming to interpret spoken content from visual cues. A prominent challenge in VSR is the presence of homophenes-visually similar lip gestures that represent different phonemes. Prior approaches have sought to distinguish fine-grained visemes by aligning visual and auditory semantics, but often fell short of full synchronization. To address this, we present SyncVSR, an end-to-end learning framework that leverages quantized audio for frame-level crossmodal supervision. By integrating a projection layer that synchronizes visual representation with acoustic data, our encoder learns to generate discrete audio tokens from a video sequence in a non-autoregressive manner. SyncVSR shows versatility across tasks, languages, and modalities at the cost of a forward pass. Our empirical evaluations show that it not only achieves state-of-the-art results but also reduces data usage by up to ninefold.
On the Powerfulness of Textual Outlier Exposure for Visual OoD Detection
Oct 25, 2023Successful detection of Out-of-Distribution (OoD) data is becoming increasingly important to ensure safe deployment of neural networks. One of the main challenges in OoD detection is that neural networks output overconfident predictions on OoD data, make it difficult to determine OoD-ness of data solely based on their predictions. Outlier exposure addresses this issue by introducing an additional loss that encourages low-confidence predictions on OoD data during training. While outlier exposure has shown promising potential in improving OoD detection performance, all previous studies on outlier exposure have been limited to utilizing visual outliers. Drawing inspiration from the recent advancements in vision-language pre-training, this paper venture out to the uncharted territory of textual outlier exposure. First, we uncover the benefits of using textual outliers by replacing real or virtual outliers in the image-domain with textual equivalents. Then, we propose various ways of generating preferable textual outliers. Our extensive experiments demonstrate that generated textual outliers achieve competitive performance on large-scale OoD and hard OoD benchmarks. Furthermore, we conduct empirical analyses of textual outliers to provide primary criteria for designing advantageous textual outliers: near-distribution, descriptiveness, and inclusion of visual semantics.