 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEAT: Fashion Editing and Try-On from Any Design
May 04, 2026Fashion design aims to express a designer's creative intent and to depict how garments interact with the human body. Recent methods condition on multimodal inputs to support garment editing and virtual try-on. However, existing methods still (i) confine design to garment-related images, excluding creative design sources such as artwork, abstract imagery, and natural photographs, and (ii) cannot support complete outfits, including accessories. We present FEAT (Fashion Editing And Try-On from Any Design), a method that enables editing and try-on across garments and accessories using diverse design sources. To achieve this, we introduce Disentangled Dual Injection (DDI). It takes both apparel and non-apparel design sources and selectively injects design cues via content and style disentanglement. Furthermore, we propose Orthogonal-Guided Noise Fusion (OGNF), a training-free mechanism that removes residual garments via orthogonal projection and applies region-specific noise strategies to enable virtual try-on for both garments and accessories. Extensive experiments demonstrate that FEAT achieves state-of-the-art performance in design flexibility, prompt consistency, and visual realism.
LIBERO-Para: A Diagnostic Benchmark and Metrics for Paraphrase Robustness in VLA Models
Mar 30, 2026Vision-Language-Action (VLA) models achieve strong performance in robotic manipulation by leveraging pre-trained vision-language backbones. However, in downstream robotic settings, they are typically fine-tuned with limited data, leading to overfitting to specific instruction formulations and leaving robustness to paraphrased instructions underexplored. To study this gap, we introduce LIBERO-Para, a controlled benchmark that independently varies action expressions and object references for fine-grained analysis of linguistic generalization. Across seven VLA configurations (0.6B-7.5B), we observe consistent performance degradation of 22-52 pp under paraphrasing. This degradation is primarily driven by object-level lexical variation: even simple synonym substitutions cause large drops, indicating reliance on surface-level matching rather than semantic grounding. Moreover, 80-96% of failures arise from planning-level trajectory divergence rather than execution errors, showing that paraphrasing disrupts task identification. Binary success rate treats all paraphrases equally, obscuring whether models perform consistently across difficulty levels or rely on easier cases. To address this, we propose PRIDE, a metric that quantifies paraphrase difficulty using semantic and syntactic factors. Our benchmark and corresponding code are available at: https://github.com/cau-hai-lab/LIBERO-Para
Balancing Saliency and Coverage: Semantic Prominence-Aware Budgeting for Visual Token Compression in VLMs
Mar 16, 2026Large Vision-Language Models (VLMs) achieve strong multimodal understanding capabilities by leveraging high-resolution visual inputs, but the resulting large number of visual tokens creates a major computational bottleneck. Recent work mitigates this issue through visual token compression, typically compressing tokens based on saliency, diversity, or a fixed combination of both. We observe that the distribution of semantic prominence varies substantially across samples, leading to different optimal trade-offs between local saliency preservation and global coverage. This observation suggests that applying a static compression strategy across all samples can be suboptimal. Motivated by this insight, we propose PromPrune, a sample-adaptive visual token selection framework composed of semantic prominence-aware budget allocation and a two-stage selection pipeline. Our method adaptively balances local saliency preservation and global coverage according to the semantic prominence distribution of each sample. By allocating token budgets between locally salient regions and globally diverse regions, our method maintains strong performance even under high compression ratios. On LLaVA-NeXT-7B, our approach reduces FLOPs by 88% and prefill latency by 22% while preserving 97.5% of the original accuracy.
Know "No" Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
Jan 19, 2025While CLIP has significantly advanced multimodal understanding by bridging vision and language, the inability to grasp negation - such as failing to differentiate concepts like "parking" from "no parking" - poses substantial challenges. By analyzing the data used in the public CLIP model's pre-training, we posit this limitation stems from a lack of negation-inclusive data. To address this, we introduce data generation pipelines that employ a large language model (LLM) and a multimodal LLM to produce negation-inclusive captions. Fine-tuning CLIP with data generated from our pipelines, we develop NegationCLIP, which enhances negation awareness while preserving the generality. Moreover, to enable a comprehensive evaluation of negation understanding, we propose NegRefCOCOg-a benchmark tailored to test VLMs' ability to interpret negation across diverse expressions and positions within a sentence. Experiments on various CLIP architectures validate the effectiveness of our data generation pipelines in enhancing CLIP's ability to perceive negation accurately. Additionally, NegationCLIP's enhanced negation awareness has practical applications across various multimodal tasks, demonstrated by performance gains in text-to-image generation and referring image segmentation.
Textual Training for the Hassle-Free Removal of Unwanted Visual Data
Sep 30, 2024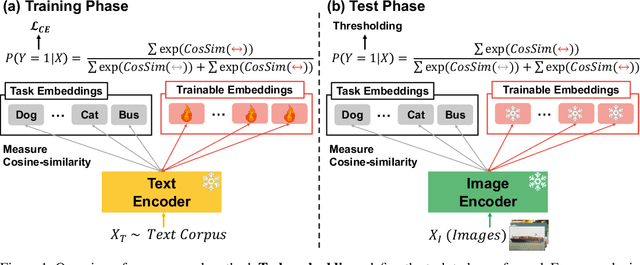
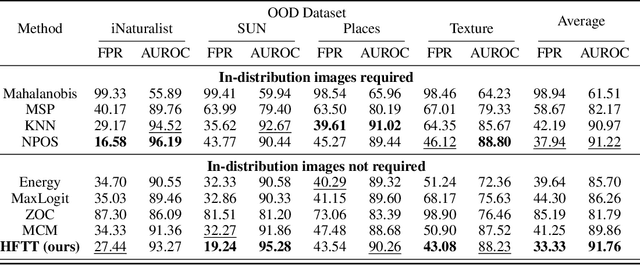
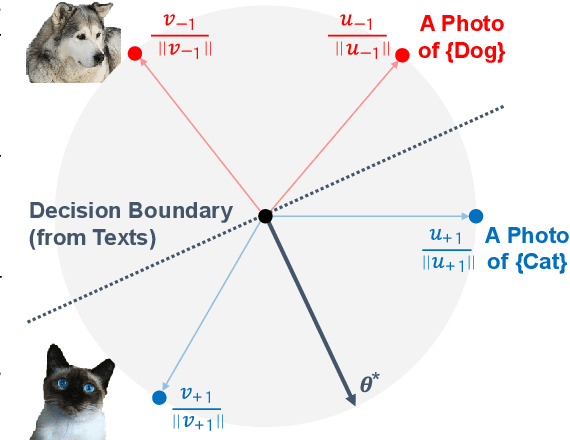
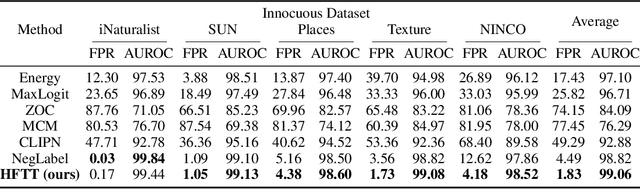
In our study, we explore methods for detecting unwanted content lurking in visual datasets. We provide a theoretical analysis demonstrating that a model capable of successfully partitioning visual data can be obtained using only textual data. Based on the analysis, we propose Hassle-Free Textual Training (HFTT), a streamlined method capable of acquiring detectors for unwanted visual content, using only synthetic textual data in conjunction with pre-trained vision-language models. HFTT features an innovative objective function that significantly reduces the necessity for human involvement in data annotation. Furthermore, HFTT employs a clever textual data synthesis method, effectively emulating the integration of unknown visual data distribution into the training process at no extra cost. The unique characteristics of HFTT extend its utility beyond traditional out-of-distribution detection, making it applicable to tasks that address more abstract concepts. We complement our analyses with experiments in out-of-distribution detection and hateful image detection. Our codes are available at https://github.com/Saehyung-Lee/HFTT
Normality Addition via Normality Detection in Industrial Image Anomaly Detection Models
Jul 29, 2024



The task of image anomaly detection (IAD) aims to identify deviations from normality in image data. These anomalies are patterns that deviate significantly from what the IAD model has learned from the data during training. However, in real-world scenarios, the criteria for what constitutes normality often change, necessitating the reclassification of previously anomalous instances as normal. To address this challenge, we propose a new scenario termed "normality addition," involving the post-training adjustment of decision boundaries to incorporate new normalities. To address this challenge, we propose a method called Normality Addition via Normality Detection (NAND), leveraging a vision-language model. NAND performs normality detection which detect patterns related to the intended normality within images based on textual descriptions. We then modify the results of a pre-trained IAD model to implement this normality addition. Using the benchmark dataset in IAD, MVTec AD, we establish an evaluation protocol for the normality addition task and empirically demonstrate the effectiveness of the NAND method.
Disentangled Motion Modeling for Video Frame Interpolation
Jun 25, 2024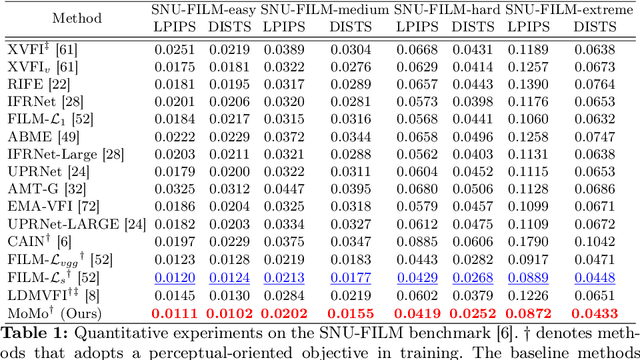
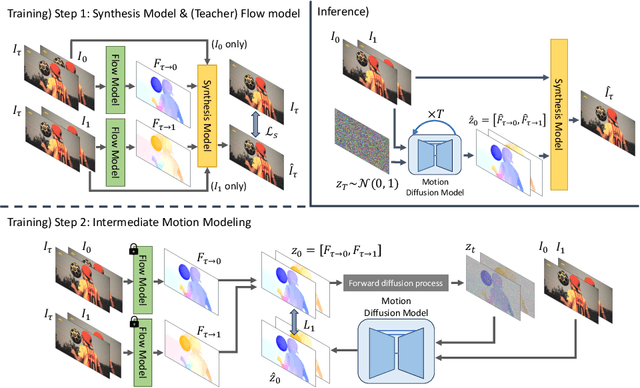

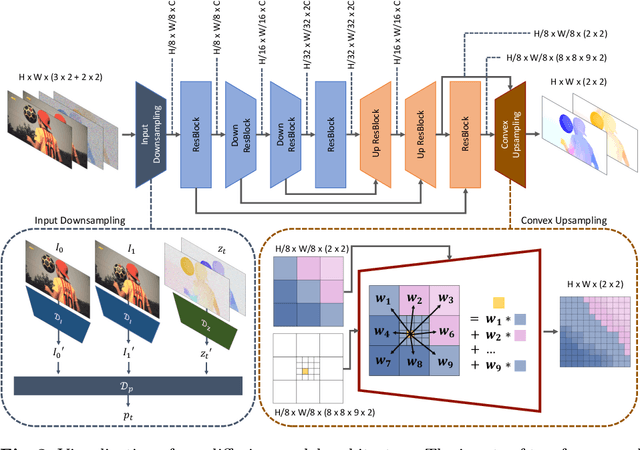
Video frame interpolation (VFI) aims to synthesize intermediate frames in between existing frames to enhance visual smoothness and quality. Beyond the conventional methods based on the reconstruction loss, recent works employ the high quality generative models for perceptual quality. However, they require complex training and large computational cost for modeling on the pixel space. In this paper, we introduce disentangled Motion Modeling (MoMo), a diffusion-based approach for VFI that enhances visual quality by focusing on intermediate motion modeling. We propose disentangled two-stage training process, initially training a frame synthesis model to generate frames from input pairs and their optical flows. Subsequently, we propose a motion diffusion model, equipped with our novel diffusion U-Net architecture designed for optical flow, to produce bi-directional flows between frames. This method, by leveraging the simpler low-frequency representation of motions, achieves superior perceptual quality with reduced computational demands compared to generative modeling methods on the pixel space. Our method surpasses state-of-the-art methods in perceptual metrics across various benchmarks, demonstrating its efficacy and efficiency in VFI. Our code is available at: https://github.com/JHLew/MoMo
Efficient Diffusion-Driven Corruption Editor for Test-Time Adaptation
Mar 19, 2024

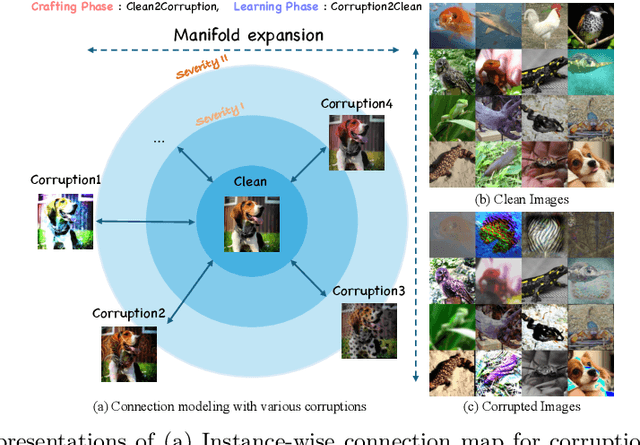

Test-time adaptation (TTA) addresses the unforeseen distribution shifts occurring during test time. In TTA, both performance and, memory and time consumption serve as crucial considerations. A recent diffusion-based TTA approach for restoring corrupted images involves image-level updates. However, using pixel space diffusion significantly increases resource requirements compared to conventional model updating TTA approaches, revealing limitations as a TTA method. To address this, we propose a novel TTA method by leveraging a latent diffusion model (LDM) based image editing model and fine-tuning it with our newly introduced corruption modeling scheme. This scheme enhances the robustness of the diffusion model against distribution shifts by creating (clean, corrupted) image pairs and fine-tuning the model to edit corrupted images into clean ones. Moreover, we introduce a distilled variant to accelerate the model for corruption editing using only 4 network function evaluations (NFEs). We extensively validated our method across various architectures and datasets including image and video domains. Our model achieves the best performance with a 100 times faster runtime than that of a diffusion-based baseline. Furthermore, it outpaces the speed of the model updating TTA method based on data augmentation threefold, rendering an image-level updating approach more practical.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024



Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.
On the Powerfulness of Textual Outlier Exposure for Visual OoD Detection
Oct 25, 2023Successful detection of Out-of-Distribution (OoD) data is becoming increasingly important to ensure safe deployment of neural networks. One of the main challenges in OoD detection is that neural networks output overconfident predictions on OoD data, make it difficult to determine OoD-ness of data solely based on their predictions. Outlier exposure addresses this issue by introducing an additional loss that encourages low-confidence predictions on OoD data during training. While outlier exposure has shown promising potential in improving OoD detection performance, all previous studies on outlier exposure have been limited to utilizing visual outliers. Drawing inspiration from the recent advancements in vision-language pre-training, this paper venture out to the uncharted territory of textual outlier exposure. First, we uncover the benefits of using textual outliers by replacing real or virtual outliers in the image-domain with textual equivalents. Then, we propose various ways of generating preferable textual outliers. Our extensive experiments demonstrate that generated textual outliers achieve competitive performance on large-scale OoD and hard OoD benchmarks. Furthermore, we conduct empirical analyses of textual outliers to provide primary criteria for designing advantageous textual outliers: near-distribution, descriptiveness, and inclusion of visual semantics.