 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Robust Driving QA through Metadata-Grounded Context and Task-Specific Prompts
Oct 21, 2025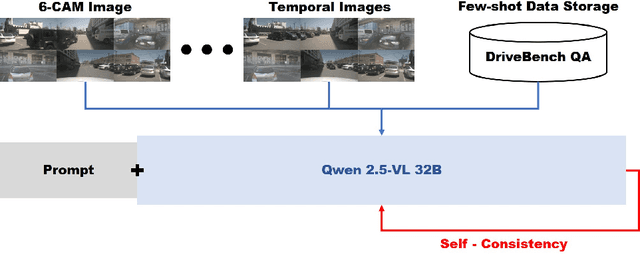
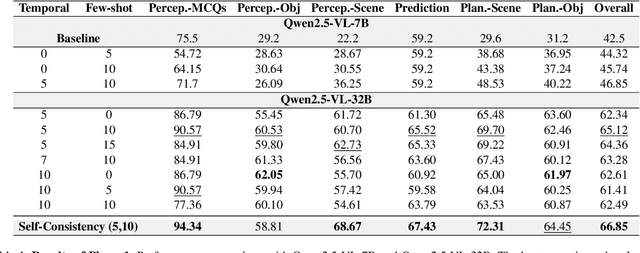
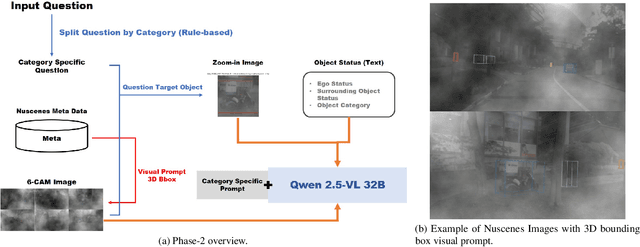

We present a two-phase vision-language QA system for autonomous driving that answers high-level perception, prediction, and planning questions. In Phase-1, a large multimodal LLM (Qwen2.5-VL-32B) is conditioned on six-camera inputs, a short temporal window of history, and a chain-of-thought prompt with few-shot exemplars. A self-consistency ensemble (multiple sampled reasoning chains) further improves answer reliability. In Phase-2, we augment the prompt with nuScenes scene metadata (object annotations, ego-vehicle state, etc.) and category-specific question instructions (separate prompts for perception, prediction, planning tasks). In experiments on a driving QA benchmark, our approach significantly outperforms the baseline Qwen2.5 models. For example, using 5 history frames and 10-shot prompting in Phase-1 yields 65.1% overall accuracy (vs.62.61% with zero-shot); applying self-consistency raises this to 66.85%. Phase-2 achieves 67.37% overall. Notably, the system maintains 96% accuracy under severe visual corruption. These results demonstrate that carefully engineered prompts and contextual grounding can greatly enhance high-level driving QA with pretrained vision-language models.
3D-Aware Vision-Language Models Fine-Tuning with Geometric Distillation
Jun 11, 2025Vision-Language Models (VLMs) have shown remarkable performance on diverse visual and linguistic tasks, yet they remain fundamentally limited in their understanding of 3D spatial structures. We propose Geometric Distillation, a lightweight, annotation-free fine-tuning framework that injects human-inspired geometric cues into pretrained VLMs without modifying their architecture. By distilling (1) sparse correspondences, (2) relative depth relations, and (3) dense cost volumes from off-the-shelf 3D foundation models (e.g., MASt3R, VGGT), our method shapes representations to be geometry-aware while remaining compatible with natural image-text inputs. Through extensive evaluations on 3D vision-language reasoning and 3D perception benchmarks, our method consistently outperforms prior approaches, achieving improved 3D spatial reasoning with significantly lower computational cost. Our work demonstrates a scalable and efficient path to bridge 2D-trained VLMs with 3D understanding, opening up wider use in spatially grounded multimodal tasks.
No Thing, Nothing: Highlighting Safety-Critical Classes for Robust LiDAR Semantic Segmentation in Adverse Weather
Mar 20, 2025Existing domain generalization methods for LiDAR semantic segmentation under adverse weather struggle to accurately predict "things" categories compared to "stuff" categories. In typical driving scenes, "things" categories can be dynamic and associated with higher collision risks, making them crucial for safe navigation and planning. Recognizing the importance of "things" categories, we identify their performance drop as a serious bottleneck in existing approaches. We observed that adverse weather induces degradation of semantic-level features and both corruption of local features, leading to a misprediction of "things" as "stuff". To mitigate these corruptions, we suggest our method, NTN - segmeNt Things for No-accident. To address semantic-level feature corruption, we bind each point feature to its superclass, preventing the misprediction of things classes into visually dissimilar categories. Additionally, to enhance robustness against local corruption caused by adverse weather, we define each LiDAR beam as a local region and propose a regularization term that aligns the clean data with its corrupted counterpart in feature space. NTN achieves state-of-the-art performance with a +2.6 mIoU gain on the SemanticKITTI-to-SemanticSTF benchmark and +7.9 mIoU on the SemanticPOSS-to-SemanticSTF benchmark. Notably, NTN achieves a +4.8 and +7.9 mIoU improvement on "things" classes, respectively, highlighting its effectiveness.
Know "No" Better: A Data-Driven Approach for Enhancing Negation Awareness in CLIP
Jan 19, 2025While CLIP has significantly advanced multimodal understanding by bridging vision and language, the inability to grasp negation - such as failing to differentiate concepts like "parking" from "no parking" - poses substantial challenges. By analyzing the data used in the public CLIP model's pre-training, we posit this limitation stems from a lack of negation-inclusive data. To address this, we introduce data generation pipelines that employ a large language model (LLM) and a multimodal LLM to produce negation-inclusive captions. Fine-tuning CLIP with data generated from our pipelines, we develop NegationCLIP, which enhances negation awareness while preserving the generality. Moreover, to enable a comprehensive evaluation of negation understanding, we propose NegRefCOCOg-a benchmark tailored to test VLMs' ability to interpret negation across diverse expressions and positions within a sentence. Experiments on various CLIP architectures validate the effectiveness of our data generation pipelines in enhancing CLIP's ability to perceive negation accurately. Additionally, NegationCLIP's enhanced negation awareness has practical applications across various multimodal tasks, demonstrated by performance gains in text-to-image generation and referring image segmentation.
Unleashing Multi-Hop Reasoning Potential in Large Language Models through Repetition of Misordered Context
Oct 09, 2024



Multi-hop reasoning, which requires multi-step reasoning based on the supporting documents within a given context, remains challenging for large language models (LLMs). LLMs often struggle to filter out irrelevant documents within the context, and their performance is sensitive to the position of supporting documents within that context. In this paper, we identify an additional challenge: LLMs' performance is also sensitive to the order in which the supporting documents are presented. We refer to this as the misordered context problem. To address this issue, we propose a simple yet effective method called context repetition (CoRe), which involves prompting the model by repeatedly presenting the context to ensure the supporting documents are presented in the optimal order for the model. Using CoRe, we improve the F1 score by up to 30%p on multi-hop QA tasks and increase accuracy by up to 70%p on a synthetic task. Additionally, CoRe helps mitigate the well-known "lost-in-the-middle" problem in LLMs and can be effectively combined with retrieval-based approaches utilizing Chain-of-Thought (CoT) reasoning.
Rethinking Data Augmentation for Robust LiDAR Semantic Segmentation in Adverse Weather
Jul 02, 2024Existing LiDAR semantic segmentation methods often struggle with performance declines in adverse weather conditions. Previous research has addressed this issue by simulating adverse weather or employing universal data augmentation during training. However, these methods lack a detailed analysis and understanding of how adverse weather negatively affects LiDAR semantic segmentation performance. Motivated by this issue, we identified key factors of adverse weather and conducted a toy experiment to pinpoint the main causes of performance degradation: (1) Geometric perturbation due to refraction caused by fog or droplets in the air and (2) Point drop due to energy absorption and occlusions. Based on these findings, we propose new strategic data augmentation techniques. First, we introduced a Selective Jittering (SJ) that jitters points in the random range of depth (or angle) to mimic geometric perturbation. Additionally, we developed a Learnable Point Drop (LPD) to learn vulnerable erase patterns with Deep Q-Learning Network to approximate the point drop phenomenon from adverse weather conditions. Without precise weather simulation, these techniques strengthen the LiDAR semantic segmentation model by exposing it to vulnerable conditions identified by our data-centric analysis. Experimental results confirmed the suitability of the proposed data augmentation methods for enhancing robustness against adverse weather conditions. Our method attains a remarkable 39.5 mIoU on the SemanticKITTI-to-SemanticSTF benchmark, surpassing the previous state-of-the-art by over 5.4%p, tripling the improvement over the baseline compared to previous methods achieved.
Precision matters: Precision-aware ensemble for weakly supervised semantic segmentation
Jun 28, 2024

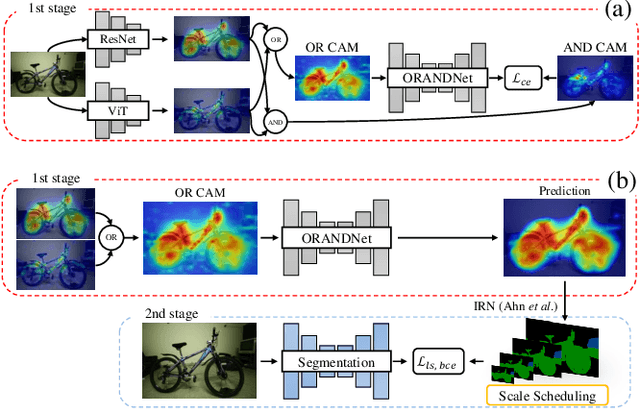

Weakly Supervised Semantic Segmentation (WSSS) employs weak supervision, such as image-level labels, to train the segmentation model. Despite the impressive achievement in recent WSSS methods, we identify that introducing weak labels with high mean Intersection of Union (mIoU) does not guarantee high segmentation performance. Existing studies have emphasized the importance of prioritizing precision and reducing noise to improve overall performance. In the same vein, we propose ORANDNet, an advanced ensemble approach tailored for WSSS. ORANDNet combines Class Activation Maps (CAMs) from two different classifiers to increase the precision of pseudo-masks (PMs). To further mitigate small noise in the PMs, we incorporate curriculum learning. This involves training the segmentation model initially with pairs of smaller-sized images and corresponding PMs, gradually transitioning to the original-sized pairs. By combining the original CAMs of ResNet-50 and ViT, we significantly improve the segmentation performance over the single-best model and the naive ensemble model, respectively. We further extend our ensemble method to CAMs from AMN (ResNet-like) and MCTformer (ViT-like) models, achieving performance benefits in advanced WSSS models. It highlights the potential of our ORANDNet as a final add-on module for WSSS models.
Interactive Text-to-Image Retrieval with Large Language Models: A Plug-and-Play Approach
Jun 05, 2024
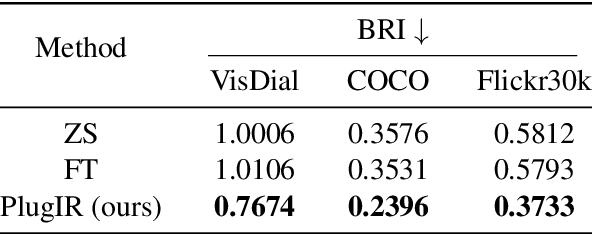
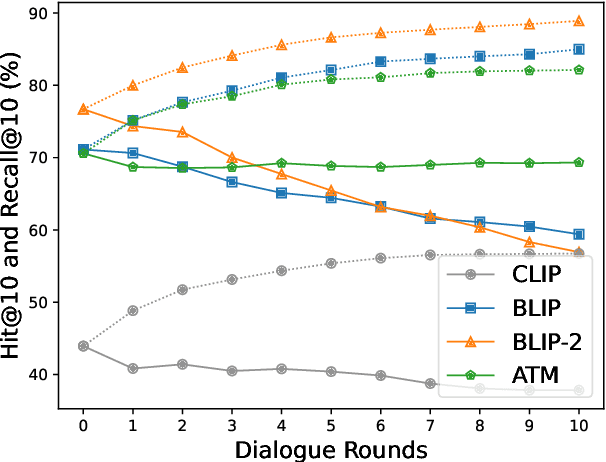

In this paper, we primarily address the issue of dialogue-form context query within the interactive text-to-image retrieval task. Our methodology, PlugIR, actively utilizes the general instruction-following capability of LLMs in two ways. First, by reformulating the dialogue-form context, we eliminate the necessity of fine-tuning a retrieval model on existing visual dialogue data, thereby enabling the use of any arbitrary black-box model. Second, we construct the LLM questioner to generate non-redundant questions about the attributes of the target image, based on the information of retrieval candidate images in the current context. This approach mitigates the issues of noisiness and redundancy in the generated questions. Beyond our methodology, we propose a novel evaluation metric, Best log Rank Integral (BRI), for a comprehensive assessment of the interactive retrieval system. PlugIR demonstrates superior performance compared to both zero-shot and fine-tuned baselines in various benchmarks. Additionally, the two methodologies comprising PlugIR can be flexibly applied together or separately in various situations. Our codes are available at https://github.com/Saehyung-Lee/PlugIR.