 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolDeTox: Evaluating Language Model's Stepwise Fragment Editing for Molecular Detoxification
May 12, 2026Large Language Models (LLMs) and Vision Language Models (VLMs) have recently shown promising capabilities in various scientific domain. In particular, these advances have opened new opportunities in drug discovery, where the ability to understand and modify molecular structures is critical for optimizing drug properties such as efficacy and toxicity. However, existing models and benchmarks often overlook toxicity-related challenges, focusing primarily on general property optimization without adequately addressing safety concerns. In addition, even existing toxicity repair benchmarks suffer from limited data diversity, low structural validity of generated molecules, and heavy reliance on proxy models for toxicity assessment. To address these limitations, we propose MolDeTox, a novel benchmark for molecular detoxification, designed to enable fine-grained and reliable evaluation of toxicity-aware molecular optimization across stepwise tasks. We evaluate a wide range of general-purpose LLMs and VLMs under diverse settings, and demonstrate that understanding and generating molecules at the fragment-level improves structural validity and enhances the quality of generated molecules. Moreover, through detailed task-level performance analysis, MolDeTox provides an interpretable benchmark that enables a deeper understanding of the detoxification process. Our dataset is available at : https://huggingface.co/datasets/MolDeTox/MolDeTox
ToxReason: A Benchmark for Mechanistic Chemical Toxicity Reasoning via Adverse Outcome Pathway
Apr 07, 2026Recent advances in large language models (LLMs) have enabled molecular reasoning for property prediction. However, toxicity arises from complex biological mechanisms beyond chemical structure, necessitating mechanistic reasoning for reliable prediction. Despite its importance, current benchmarks fail to systematically evaluate this capability. LLMs can generate fluent but biologically unfaithful explanations, making it difficult to assess whether predicted toxicities are grounded invalid mechanisms. To bridge this gap, we introduce ToxReason, a benchmark grounded in the Adverse Outcome Pathway (AOP) that evaluates organ-level toxicity reasoning across multiple organs. ToxReason integrates experimental drug-target interaction evidence with toxicity labels, requiring models to infer both toxic outcomes and their underlying mechanisms from Molecular Initiating Event (MIE) to Adverse Outcome (AO). Using ToxReason, we evaluate toxicity prediction performance and reasoning quality across diverse LLMs. We find that strong predictive performance does not necessarily imply reliable reasoning. Furthermore, we show that reasoning-aware training improves mechanistic reasoning and, consequently, toxicity prediction performance. Together, these results underscore the necessity of integrating reasoning into both evaluation and training for trustworthy toxicity modeling.
Does Time Have Its Place? Temporal Heads: Where Language Models Recall Time-specific Information
Feb 20, 2025



While the ability of language models to elicit facts has been widely investigated, how they handle temporally changing facts remains underexplored. We discover Temporal Heads, specific attention heads primarily responsible for processing temporal knowledge through circuit analysis. We confirm that these heads are present across multiple models, though their specific locations may vary, and their responses differ depending on the type of knowledge and its corresponding years. Disabling these heads degrades the model's ability to recall time-specific knowledge while maintaining its general capabilities without compromising time-invariant and question-answering performances. Moreover, the heads are activated not only numeric conditions ("In 2004") but also textual aliases ("In the year ..."), indicating that they encode a temporal dimension beyond simple numerical representation. Furthermore, we expand the potential of our findings by demonstrating how temporal knowledge can be edited by adjusting the values of these heads.
Rationale-Guided Retrieval Augmented Generation for Medical Question Answering
Nov 01, 2024



Large language models (LLM) hold significant potential for applications in biomedicine, but they struggle with hallucinations and outdated knowledge. While retrieval-augmented generation (RAG) is generally employed to address these issues, it also has its own set of challenges: (1) LLMs are vulnerable to irrelevant or incorrect context, (2) medical queries are often not well-targeted for helpful information, and (3) retrievers are prone to bias toward the specific source corpus they were trained on. In this study, we present RAG$^2$ (RAtionale-Guided RAG), a new framework for enhancing the reliability of RAG in biomedical contexts. RAG$^2$ incorporates three key innovations: a small filtering model trained on perplexity-based labels of rationales, which selectively augments informative snippets of documents while filtering out distractors; LLM-generated rationales as queries to improve the utility of retrieved snippets; a structure designed to retrieve snippets evenly from a comprehensive set of four biomedical corpora, effectively mitigating retriever bias. Our experiments demonstrate that RAG$^2$ improves the state-of-the-art LLMs of varying sizes, with improvements of up to 6.1\%, and it outperforms the previous best medical RAG model by up to 5.6\% across three medical question-answering benchmarks. Our code is available at https://github.com/dmis-lab/RAG2.
ChroKnowledge: Unveiling Chronological Knowledge of Language Models in Multiple Domains
Oct 13, 2024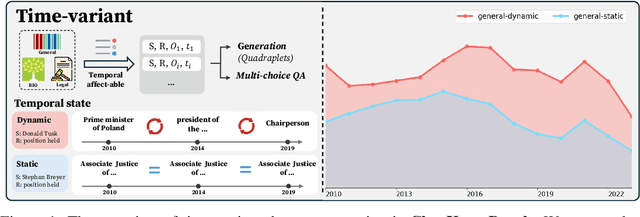


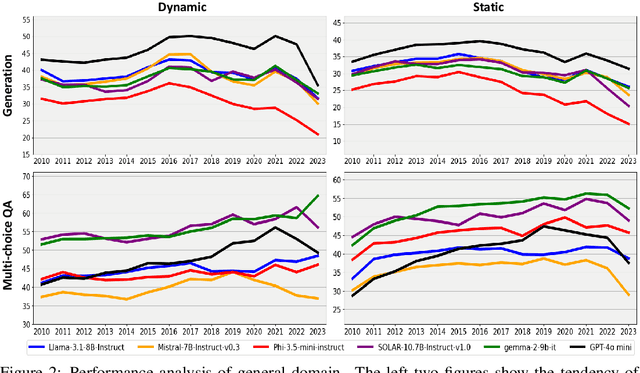
Large language models (LLMs) have significantly impacted many aspects of our lives. However, assessing and ensuring their chronological knowledge remains challenging. Existing approaches fall short in addressing the accumulative nature of knowledge, often relying on a single time stamp. To overcome this, we introduce ChroKnowBench, a benchmark dataset designed to evaluate chronologically accumulated knowledge across three key aspects: multiple domains, time dependency, temporal state. Our benchmark distinguishes between knowledge that evolves (e.g., scientific discoveries, amended laws) and knowledge that remain constant (e.g., mathematical truths, commonsense facts). Building on this benchmark, we present ChroKnowledge (Chronological Categorization of Knowledge), a novel sampling-based framework for evaluating and updating LLMs' non-parametric chronological knowledge. Our evaluation shows: (1) The ability of eliciting temporal knowledge varies depending on the data format that model was trained on. (2) LLMs partially recall knowledge or show a cut-off at temporal boundaries rather than recalling all aspects of knowledge correctly. Thus, we apply our ChroKnowPrompt, an in-depth prompting to elicit chronological knowledge by traversing step-by-step through the surrounding time spans. We observe that our framework successfully updates the overall knowledge across the entire timeline in both the biomedical domain (+11.9%) and the general domain (+2.8%), demonstrating its effectiveness in refining temporal knowledge. This non-parametric approach also enables knowledge updates not only in open-source models but also in proprietary LLMs, ensuring comprehensive applicability across model types. We perform a comprehensive analysis based on temporal characteristics of ChroKnowPrompt and validate the potential of various models to elicit intrinsic temporal knowledge through our method.