 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-Safe Pre-Training for Robust 4-Bit Quantization of Large Language Models
Jun 24, 2025Extreme activation outliers in Large Language Models (LLMs) critically degrade quantization performance, hindering efficient on-device deployment. While channel-wise operations and adaptive gradient scaling are recognized causes, practical mitigation remains challenging. We introduce Outlier-Safe Pre-Training (OSP), a practical guideline that proactively prevents outlier formation rather than relying on post-hoc mitigation. OSP combines three key innovations: (1) the Muon optimizer, eliminating privileged bases while maintaining training efficiency; (2) Single-Scale RMSNorm, preventing channel-wise amplification; and (3) a learnable embedding projection, redistributing activation magnitudes originating from embedding matrices. We validate OSP by training a 1.4B-parameter model on 1 trillion tokens, which is the first production-scale LLM trained without such outliers. Under aggressive 4-bit quantization, our OSP model achieves a 35.7 average score across 10 benchmarks (compared to 26.5 for an Adam-trained model), with only a 2% training overhead. Remarkably, OSP models exhibit near-zero excess kurtosis (0.04) compared to extreme values (1818.56) in standard models, fundamentally altering LLM quantization behavior. Our work demonstrates that outliers are not inherent to LLMs but are consequences of training strategies, paving the way for more efficient LLM deployment. The source code and pretrained checkpoints are available at https://github.com/dmis-lab/Outlier-Safe-Pre-Training.
ETHIC: Evaluating Large Language Models on Long-Context Tasks with High Information Coverage
Oct 22, 2024



Recent advancements in large language models (LLM) capable of processing extremely long texts highlight the need for a dedicated evaluation benchmark to assess their long-context capabilities. However, existing methods, like the needle-in-a-haystack test, do not effectively assess whether these models fully utilize contextual information, raising concerns about the reliability of current evaluation techniques. To thoroughly examine the effectiveness of existing benchmarks, we introduce a new metric called information coverage (IC), which quantifies the proportion of the input context necessary for answering queries. Our findings indicate that current benchmarks exhibit low IC; although the input context may be extensive, the actual usable context is often limited. To address this, we present ETHIC, a novel benchmark designed to assess LLMs' ability to leverage the entire context. Our benchmark comprises 2,648 test instances spanning four long-context tasks with high IC scores in the domains of books, debates, medicine, and law. Our evaluations reveal significant performance drops in contemporary LLMs, highlighting a critical challenge in managing long contexts. Our benchmark is available at https://github.com/dmis-lab/ETHIC.
CompAct: Compressing Retrieved Documents Actively for Question Answering
Jul 12, 2024Retrieval-augmented generation supports language models to strengthen their factual groundings by providing external contexts. However, language models often face challenges when given extensive information, diminishing their effectiveness in solving questions. Context compression tackles this issue by filtering out irrelevant information, but current methods still struggle in realistic scenarios where crucial information cannot be captured with a single-step approach. To overcome this limitation, we introduce CompAct, a novel framework that employs an active strategy to condense extensive documents without losing key information. Our experiments demonstrate that CompAct brings significant improvements in both performance and compression rate on multi-hop question-answering (QA) benchmarks. CompAct flexibly operates as a cost-efficient plug-in module with various off-the-shelf retrievers or readers, achieving exceptionally high compression rates (47x).
OLAPH: Improving Factuality in Biomedical Long-form Question Answering
May 21, 2024

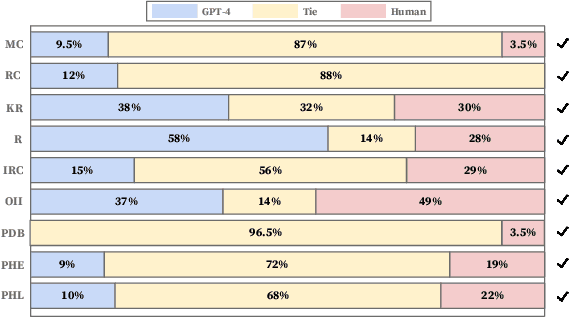

In the medical domain, numerous scenarios necessitate the long-form generation ability of large language models (LLMs). Specifically, when addressing patients' questions, it is essential that the model's response conveys factual claims, highlighting the need for an automated method to evaluate those claims. Thus, we introduce MedLFQA, a benchmark dataset reconstructed using long-form question-answering datasets related to the biomedical domain. We use MedLFQA to facilitate the automatic evaluations of factuality. We also propose OLAPH, a simple and novel framework that enables the improvement of factuality through automatic evaluations. The OLAPH framework iteratively trains LLMs to mitigate hallucinations using sampling predictions and preference optimization. In other words, we iteratively set the highest-scoring response as a preferred response derived from sampling predictions and train LLMs to align with the preferred response that improves factuality. We highlight that, even on evaluation metrics not used during training, LLMs trained with our OLAPH framework demonstrate significant performance improvement in factuality. Our findings reveal that a 7B LLM trained with our OLAPH framework can provide long answers comparable to the medical experts' answers in terms of factuality. We believe that our work could shed light on gauging the long-text generation ability of LLMs in the medical domain. Our code and datasets are available at https://github.com/dmis-lab/OLAPH}{https://github.com/dmis-lab/OLAPH.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.