 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulinary Class Wars: Evaluating LLMs using ASH in Cuisine Transfer Task
Nov 04, 2024
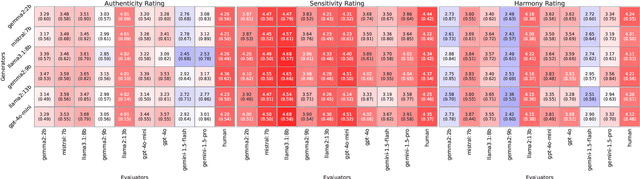
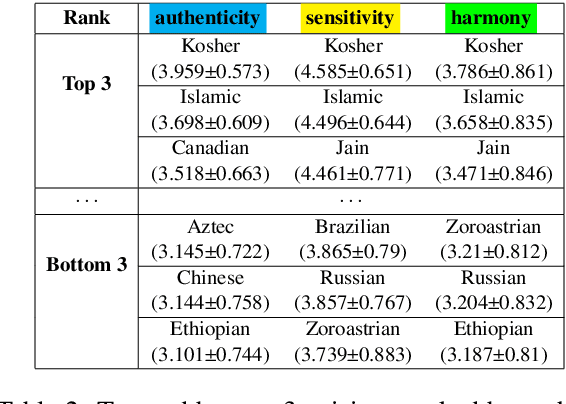
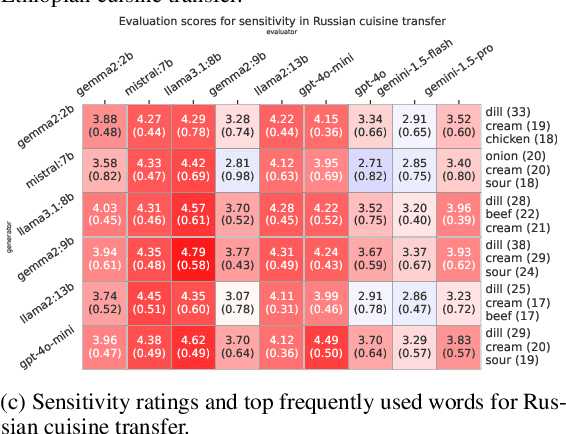
The advent of Large Language Models (LLMs) have shown promise in various creative domains, including culinary arts. However, many LLMs still struggle to deliver the desired level of culinary creativity, especially when tasked with adapting recipes to meet specific cultural requirements. This study focuses on cuisine transfer-applying elements of one cuisine to another-to assess LLMs' culinary creativity. We employ a diverse set of LLMs to generate and evaluate culturally adapted recipes, comparing their evaluations against LLM and human judgments. We introduce the ASH (authenticity, sensitivity, harmony) benchmark to evaluate LLMs' recipe generation abilities in the cuisine transfer task, assessing their cultural accuracy and creativity in the culinary domain. Our findings reveal crucial insights into both generative and evaluative capabilities of LLMs in the culinary domain, highlighting strengths and limitations in understanding and applying cultural nuances in recipe creation. The code and dataset used in this project will be openly available in \url{http://github.com/dmis-lab/CulinaryASH}.
LAPIS: Language Model-Augmented Police Investigation System
Jul 31, 2024Crime situations are race against time. An AI-assisted criminal investigation system, providing prompt but precise legal counsel is in need for police officers. We introduce LAPIS (Language Model Augmented Police Investigation System), an automated system that assists police officers to perform rational and legal investigative actions. We constructed a finetuning dataset and retrieval knowledgebase specialized in crime investigation legal reasoning task. We extended the dataset's quality by incorporating manual curation efforts done by a group of domain experts. We then finetuned the pretrained weights of a smaller Korean language model to the newly constructed dataset and integrated it with the crime investigation knowledgebase retrieval approach. Experimental results show LAPIS' potential in providing reliable legal guidance for police officers, even better than the proprietary GPT-4 model. Qualitative analysis on the rationales generated by LAPIS demonstrate the model's reasoning ability to leverage the premises and derive legally correct conclusions.
DeepClair: Utilizing Market Forecasts for Effective Portfolio Selection
Jul 18, 2024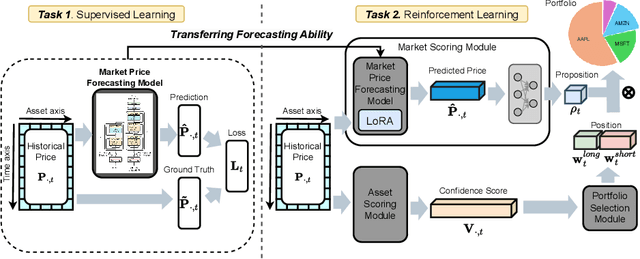

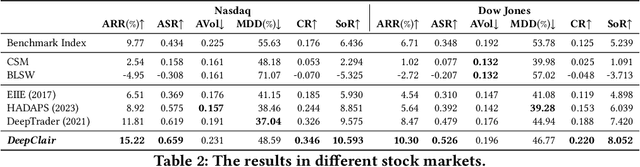
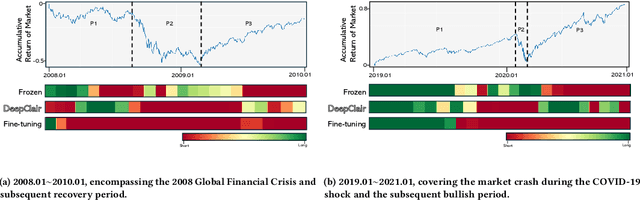
Utilizing market forecasts is pivotal in optimizing portfolio selection strategies. We introduce DeepClair, a novel framework for portfolio selection. DeepClair leverages a transformer-based time-series forecasting model to predict market trends, facilitating more informed and adaptable portfolio decisions. To integrate the forecasting model into a deep reinforcement learning-driven portfolio selection framework, we introduced a two-step strategy: first, pre-training the time-series model on market data, followed by fine-tuning the portfolio selection architecture using this model. Additionally, we investigated the optimization technique, Low-Rank Adaptation (LoRA), to enhance the pre-trained forecasting model for fine-tuning in investment scenarios. This work bridges market forecasting and portfolio selection, facilitating the advancement of investment strategies.
CookingSense: A Culinary Knowledgebase with Multidisciplinary Assertions
May 01, 2024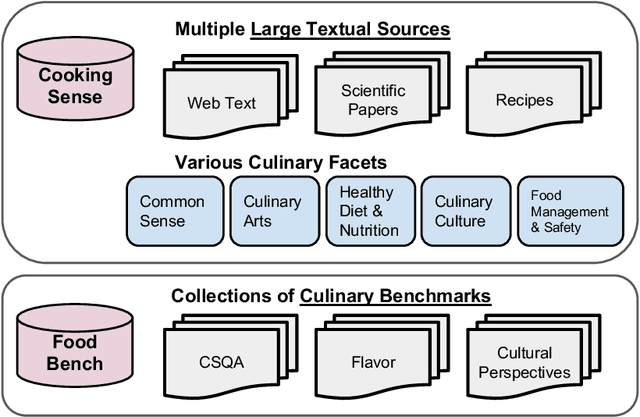

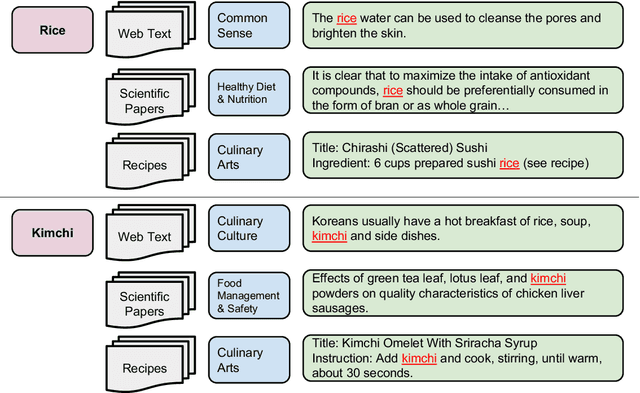
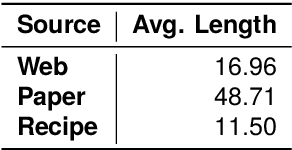
This paper introduces CookingSense, a descriptive collection of knowledge assertions in the culinary domain extracted from various sources, including web data, scientific papers, and recipes, from which knowledge covering a broad range of aspects is acquired. CookingSense is constructed through a series of dictionary-based filtering and language model-based semantic filtering techniques, which results in a rich knowledgebase of multidisciplinary food-related assertions. Additionally, we present FoodBench, a novel benchmark to evaluate culinary decision support systems. From evaluations with FoodBench, we empirically prove that CookingSense improves the performance of retrieval augmented language models. We also validate the quality and variety of assertions in CookingSense through qualitative analysis.
Small Language Models Learn Enhanced Reasoning Skills from Medical Textbooks
Mar 30, 2024While recent advancements in commercial large language models (LM) have shown promising results in medical tasks, their closed-source nature poses significant privacy and security concerns, hindering their widespread use in the medical field. Despite efforts to create open-source models, their limited parameters often result in insufficient multi-step reasoning capabilities required for solving complex medical problems. To address this, we introduce Meerkat-7B, a novel medical AI system with 7 billion parameters. Meerkat-7B was trained using our new synthetic dataset consisting of high-quality chain-of-thought reasoning paths sourced from 18 medical textbooks, along with diverse instruction-following datasets. Our system achieved remarkable accuracy across seven medical benchmarks, surpassing GPT-3.5 by 13.1%, as well as outperforming the previous best 7B models such as MediTron-7B and BioMistral-7B by 13.4% and 9.8%, respectively. Notably, it surpassed the passing threshold of the United States Medical Licensing Examination (USMLE) for the first time for a 7B-parameter model. Additionally, our system offered more detailed free-form responses to clinical queries compared to existing 7B and 13B models, approaching the performance level of GPT-3.5. This significantly narrows the performance gap with large LMs, showcasing its effectiveness in addressing complex medical challenges.
KitchenScale: Learning to predict ingredient quantities from recipe contexts
Apr 21, 2023Determining proper quantities for ingredients is an essential part of cooking practice from the perspective of enriching tastiness and promoting healthiness. We introduce KitchenScale, a fine-tuned Pre-trained Language Model (PLM) that predicts a target ingredient's quantity and measurement unit given its recipe context. To effectively train our KitchenScale model, we formulate an ingredient quantity prediction task that consists of three sub-tasks which are ingredient measurement type classification, unit classification, and quantity regression task. Furthermore, we utilized transfer learning of cooking knowledge from recipe texts to PLMs. We adopted the Discrete Latent Exponent (DExp) method to cope with high variance of numerical scales in recipe corpora. Experiments with our newly constructed dataset and recommendation examples demonstrate KitchenScale's understanding of various recipe contexts and generalizability in predicting ingredient quantities. We implemented a web application for KitchenScale to demonstrate its functionality in recommending ingredient quantities expressed in numerals (e.g., 2) with units (e.g., ounce).
* Expert Systems with Applications 2023, Demo: http://kitchenscale.korea.ac.kr/
RecipeMind: Guiding Ingredient Choices from Food Pairing to Recipe Completion using Cascaded Set Transformer
Oct 14, 2022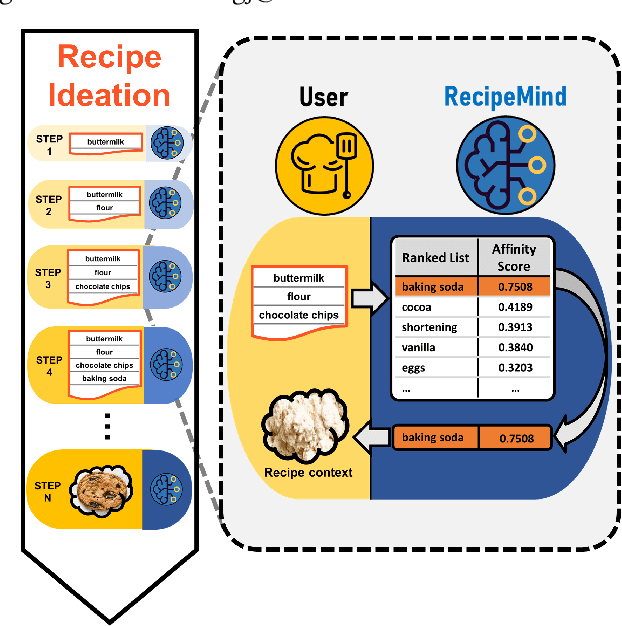
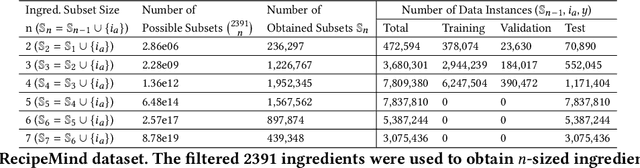
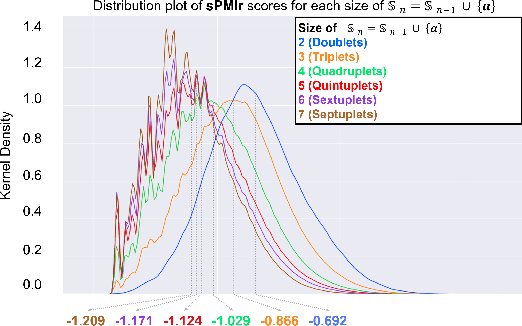
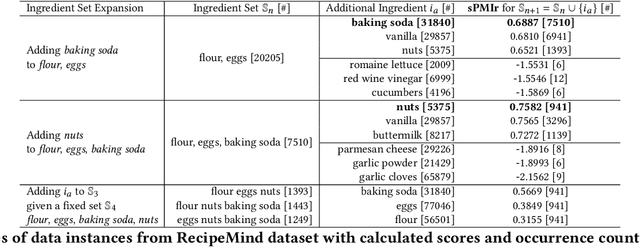
We propose a computational approach for recipe ideation, a downstream task that helps users select and gather ingredients for creating dishes. To perform this task, we developed RecipeMind, a food affinity score prediction model that quantifies the suitability of adding an ingredient to set of other ingredients. We constructed a large-scale dataset containing ingredient co-occurrence based scores to train and evaluate RecipeMind on food affinity score prediction. Deployed in recipe ideation, RecipeMind helps the user expand an initial set of ingredients by suggesting additional ingredients. Experiments and qualitative analysis show RecipeMind's potential in fulfilling its assistive role in cuisine domain.
Learning User Preferences and Understanding Calendar Contexts for Event Scheduling
Oct 17, 2018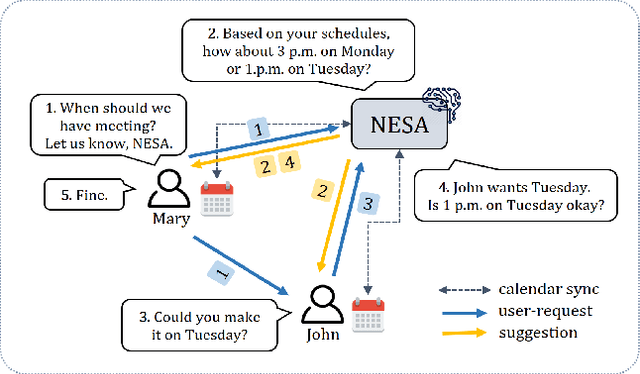
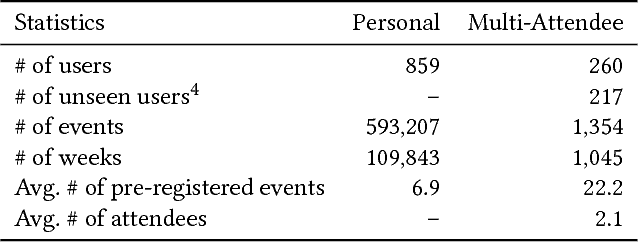
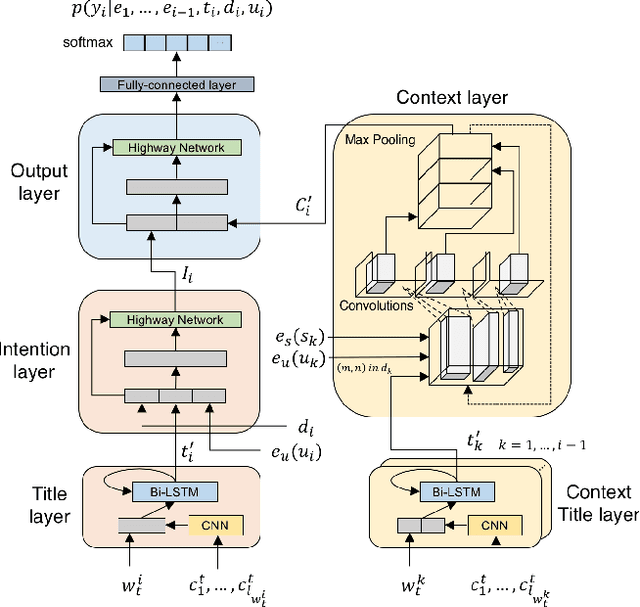

With online calendar services gaining popularity worldwide, calendar data has become one of the richest context sources for understanding human behavior. However, event scheduling is still time-consuming even with the development of online calendars. Although machine learning based event scheduling models have automated scheduling processes to some extent, they often fail to understand subtle user preferences and complex calendar contexts with event titles written in natural language. In this paper, we propose Neural Event Scheduling Assistant (NESA) which learns user preferences and understands calendar contexts, directly from raw online calendars for fully automated and highly effective event scheduling. We leverage over 593K calendar events for NESA to learn scheduling personal events, and we further utilize NESA for multi-attendee event scheduling. NESA successfully incorporates deep neural networks such as Bidirectional Long Short-Term Memory, Convolutional Neural Network, and Highway Network for learning the preferences of each user and understanding calendar context based on natural languages. The experimental results show that NESA significantly outperforms previous baseline models in terms of various evaluation metrics on both personal and multi-attendee event scheduling tasks. Our qualitative analysis demonstrates the effectiveness of each layer in NESA and learned user preferences.