 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Normalization for Lipschitz-Constrained Policies on Learning Humanoid Locomotion
Apr 11, 2025Reinforcement learning (RL) has shown great potential in training agile and adaptable controllers for legged robots, enabling them to learn complex locomotion behaviors directly from experience. However, policies trained in simulation often fail to transfer to real-world robots due to unrealistic assumptions such as infinite actuator bandwidth and the absence of torque limits. These conditions allow policies to rely on abrupt, high-frequency torque changes, which are infeasible for real actuators with finite bandwidth. Traditional methods address this issue by penalizing aggressive motions through regularization rewards, such as joint velocities, accelerations, and energy consumption, but they require extensive hyperparameter tuning. Alternatively, Lipschitz-Constrained Policies (LCP) enforce finite bandwidth action control by penalizing policy gradients, but their reliance on gradient calculations introduces significant GPU memory overhead. To overcome this limitation, this work proposes Spectral Normalization (SN) as an efficient replacement for enforcing Lipschitz continuity. By constraining the spectral norm of network weights, SN effectively limits high-frequency policy fluctuations while significantly reducing GPU memory usage. Experimental evaluations in both simulation and real-world humanoid robot show that SN achieves performance comparable to gradient penalty methods while enabling more efficient parallel training.
Sim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
Apr 09, 2025
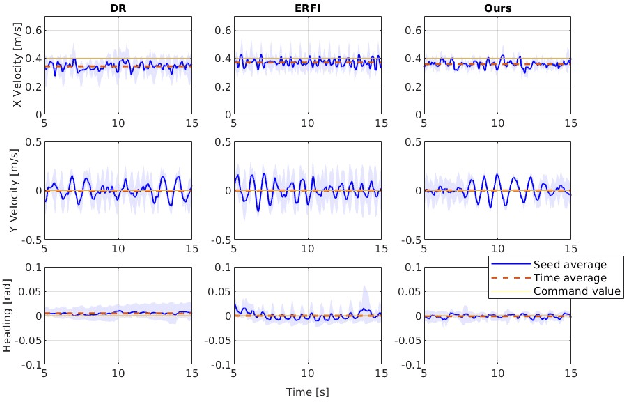
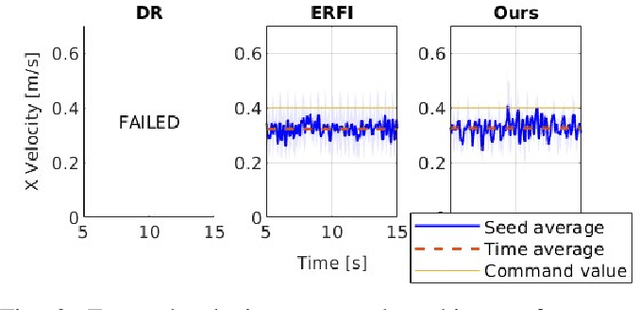
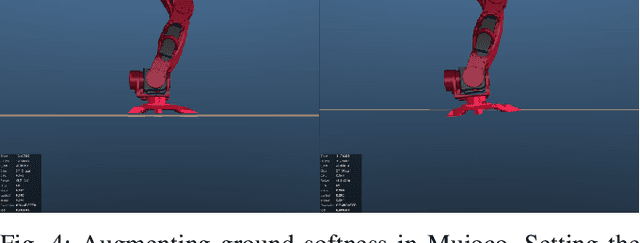
This paper proposes a novel alternative to existing sim-to-real methods for training control policies with simulated experiences. Prior sim-to-real methods for legged robots mostly rely on the domain randomization approach, where a fixed finite set of simulation parameters is randomized during training. Instead, our method adds state-dependent perturbations to the input joint torque used for forward simulation during the training phase. These state-dependent perturbations are designed to simulate a broader range of reality gaps than those captured by randomizing a fixed set of simulation parameters. Experimental results show that our method enables humanoid locomotion policies that achieve greater robustness against complex reality gaps unseen in the training domain.
Development of a Collaborative Robotic Arm-based Bimanual Haptic Display
Nov 11, 2024



This paper presents a bimanual haptic display based on collaborative robot arms. We address the limitations of existing robot arm-based haptic displays by optimizing the setup configuration and implementing inertia/friction compensation techniques. The optimized setup configuration maximizes workspace coverage, dexterity, and haptic feedback capability while ensuring collision safety. Inertia/friction compensation significantly improve transparency and reduce user fatigue, leading to a more seamless and transparent interaction. The effectiveness of our system is demonstrated in various applications, including bimanual bilateral teleoperation in both real and simulated environments. This research contributes to the advancement of haptic technology by presenting a practical and effective solution for creating high-performance bimanual haptic displays using collaborative robot arms.
Fast Quantum Convolutional Neural Networks for Low-Complexity Object Detection in Autonomous Driving Applications
Dec 28, 2023



Spurred by consistent advances and innovation in deep learning, object detection applications have become prevalent, particularly in autonomous driving that leverages various visual data. As convolutional neural networks (CNNs) are being optimized, the performances and computation speeds of object detection in autonomous driving have been significantly improved. However, due to the exponentially rapid growth in the complexity and scale of data used in object detection, there are limitations in terms of computation speeds while conducting object detection solely with classical computing. Motivated by this, quantum convolution-based object detection (QCOD) is proposed to adopt quantum computing to perform object detection at high speed. The QCOD utilizes our proposed fast quantum convolution that uploads input channel information and re-constructs output channels for achieving reduced computational complexity and thus improving performances. Lastly, the extensive experiments with KITTI autonomous driving object detection dataset verify that the proposed fast quantum convolution and QCOD are successfully operated in real object detection applications.
Proprioceptive External Torque Learning for Floating Base Robot and its Applications to Humanoid Locomotion
Sep 08, 2023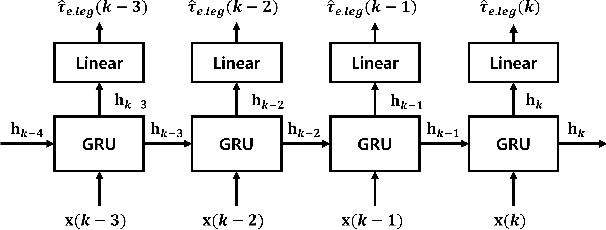
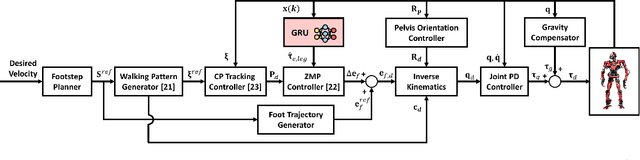
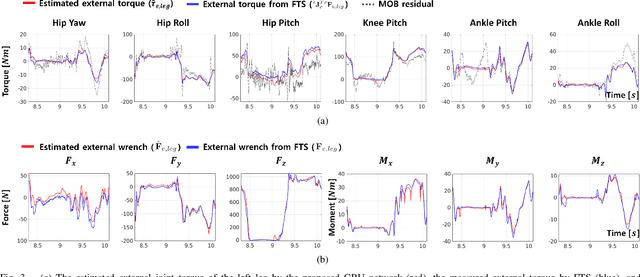
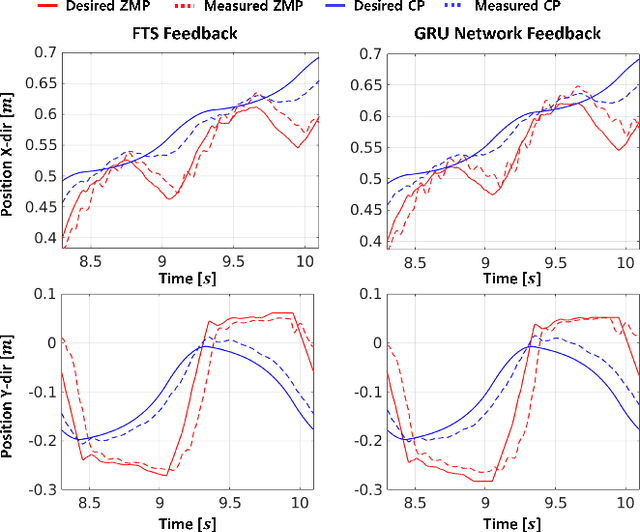
The estimation of external joint torque and contact wrench is essential for achieving stable locomotion of humanoids and safety-oriented robots. Although the contact wrench on the foot of humanoids can be measured using a force-torque sensor (FTS), FTS increases the cost, inertia, complexity, and failure possibility of the system. This paper introduces a method for learning external joint torque solely using proprioceptive sensors (encoders and IMUs) for a floating base robot. For learning, the GRU network is used and random walking data is collected. Real robot experiments demonstrate that the network can estimate the external torque and contact wrench with significantly smaller errors compared to the model-based method, momentum observer (MOB) with friction modeling. The study also validates that the estimated contact wrench can be utilized for zero moment point (ZMP) feedback control, enabling stable walking. Moreover, even when the robot's feet and the inertia of the upper body are changed, the trained network shows consistent performance with a model-based calibration. This result demonstrates the possibility of removing FTS on the robot, which reduces the disadvantages of hardware sensors. The summary video is available at https://youtu.be/gT1D4tOiKpo.
Torque-based Deep Reinforcement Learning for Task-and-Robot Agnostic Learning on Bipedal Robots Using Sim-to-Real Transfer
Apr 19, 2023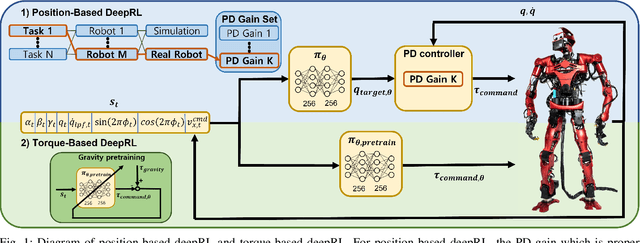
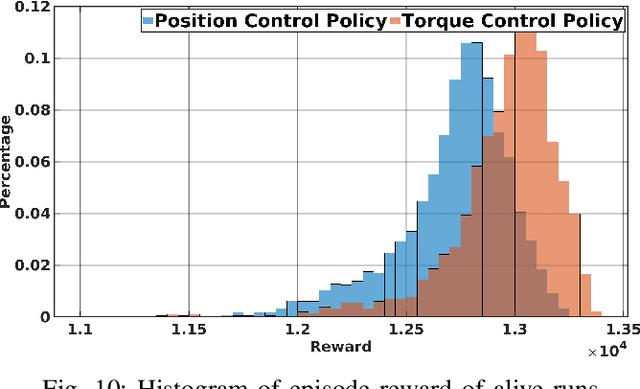
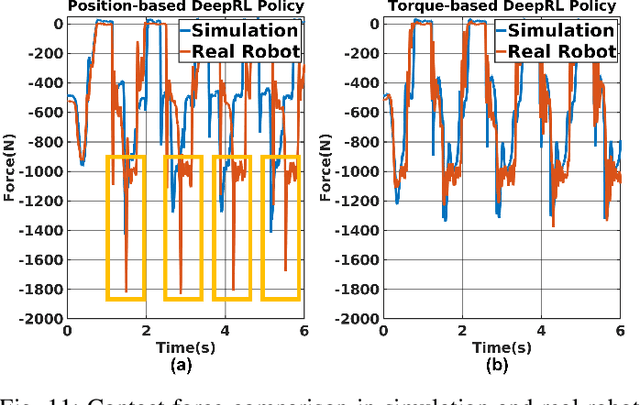

In this paper, we review the question of which action space is best suited for controlling a real biped robot in combination with Sim2Real training. Position control has been popular as it has been shown to be more sample efficient and intuitive to combine with other planning algorithms. However, for position control gain tuning is required to achieve the best possible policy performance. We show that instead, using a torque-based action space enables task-and-robot agnostic learning with less parameter tuning and mitigates the sim-to-reality gap by taking advantage of torque control's inherent compliance. Also, we accelerate the torque-based-policy training process by pre-training the policy to remain upright by compensating for gravity. The paper showcases the first successful sim-to-real transfer of a torque-based deep reinforcement learning policy on a real human-sized biped robot. The video is available at https://youtu.be/CR6pTS39VRE.
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

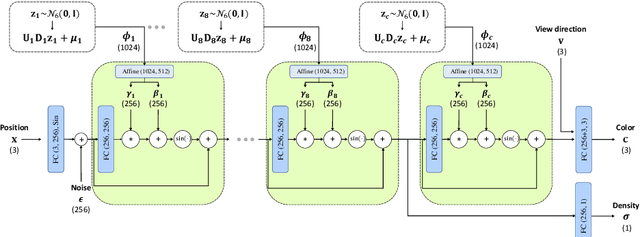
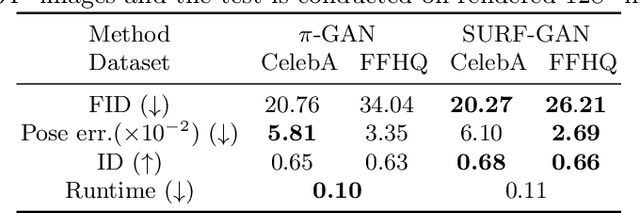
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Efficient dynamic filter for robust and low computational feature extraction
May 03, 2022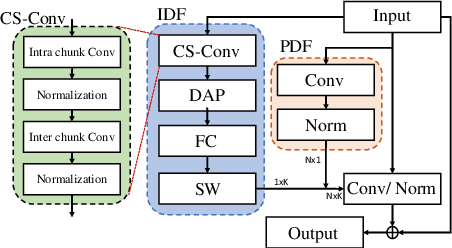
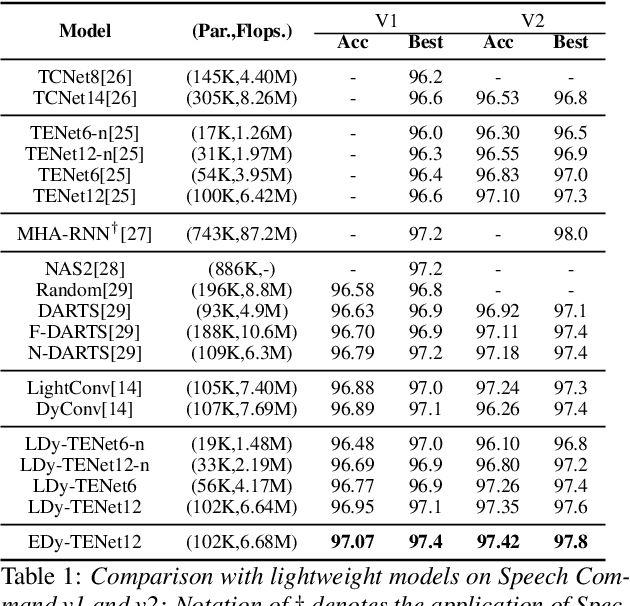
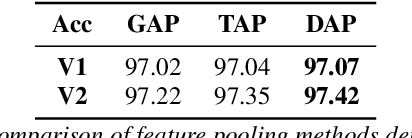
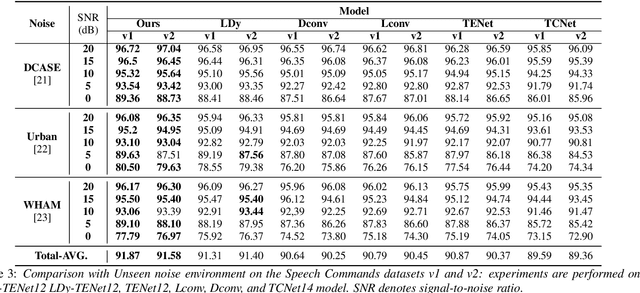
Unseen noise signal which is not considered in a model training process is difficult to anticipate and would lead to performance degradation. Various methods have been investigated to mitigate unseen noise. In our previous work, an Instance-level Dynamic Filter (IDF) and a Pixel Dynamic Filter (PDF) were proposed to extract noise-robust features. However, the performance of the dynamic filter might be degraded since simple feature pooling is used to reduce the computational resource in the IDF part. In this paper, we propose an efficient dynamic filter to enhance the performance of the dynamic filter. Instead of utilizing the simple feature mean, we separate Time-Frequency (T-F) features as non-overlapping chunks, and separable convolutions are carried out for each feature direction (inter chunks and intra chunks). Additionally, we propose Dynamic Attention Pooling that maps high dimensional features as low dimensional feature embeddings. These methods are applied to the IDF for keyword spotting and speaker verification tasks. We confirm that our proposed method performs better in unseen environments (unseen noise and unseen speakers) than state-of-the-art models.
Fetal Brain Tissue Annotation and Segmentation Challenge Results
Apr 20, 2022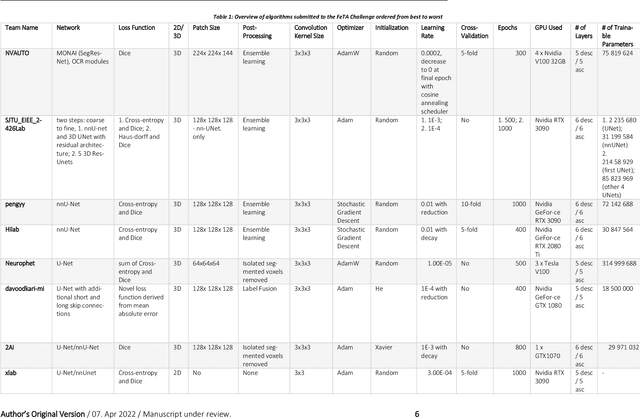
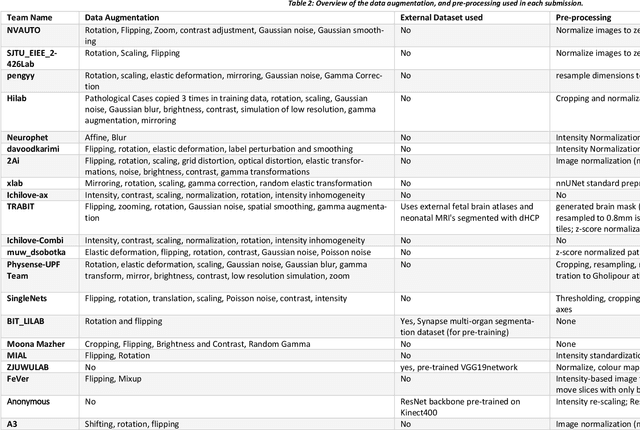
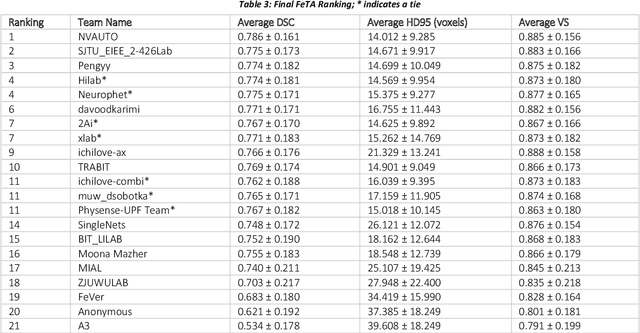
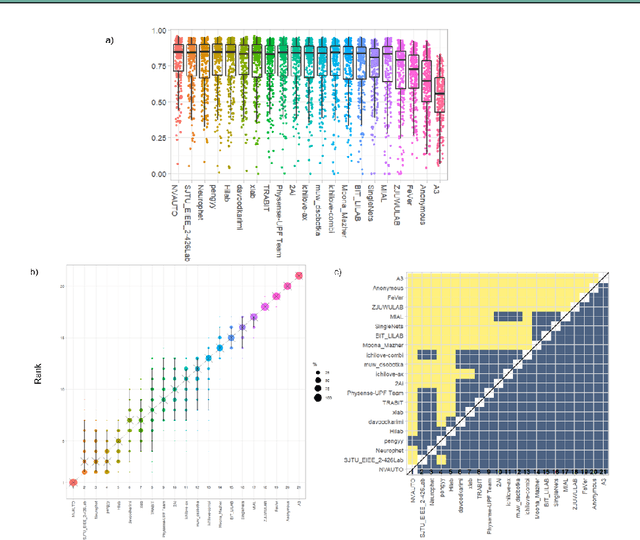
In-utero fetal MRI is emerging as an important tool in the diagnosis and analysis of the developing human brain. Automatic segmentation of the developing fetal brain is a vital step in the quantitative analysis of prenatal neurodevelopment both in the research and clinical context. However, manual segmentation of cerebral structures is time-consuming and prone to error and inter-observer variability. Therefore, we organized the Fetal Tissue Annotation (FeTA) Challenge in 2021 in order to encourage the development of automatic segmentation algorithms on an international level. The challenge utilized FeTA Dataset, an open dataset of fetal brain MRI reconstructions segmented into seven different tissues (external cerebrospinal fluid, grey matter, white matter, ventricles, cerebellum, brainstem, deep grey matter). 20 international teams participated in this challenge, submitting a total of 21 algorithms for evaluation. In this paper, we provide a detailed analysis of the results from both a technical and clinical perspective. All participants relied on deep learning methods, mainly U-Nets, with some variability present in the network architecture, optimization, and image pre- and post-processing. The majority of teams used existing medical imaging deep learning frameworks. The main differences between the submissions were the fine tuning done during training, and the specific pre- and post-processing steps performed. The challenge results showed that almost all submissions performed similarly. Four of the top five teams used ensemble learning methods. However, one team's algorithm performed significantly superior to the other submissions, and consisted of an asymmetrical U-Net network architecture. This paper provides a first of its kind benchmark for future automatic multi-tissue segmentation algorithms for the developing human brain in utero.
BERN2: an advanced neural biomedical named entity recognition and normalization tool
Jan 10, 2022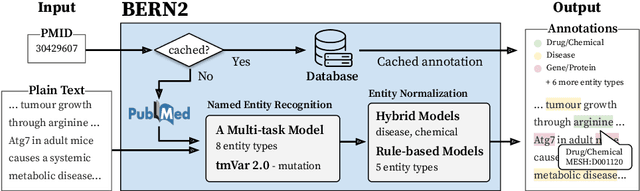

In biomedical natural language processing, named entity recognition (NER) and named entity normalization (NEN) are key tasks that enable the automatic extraction of biomedical entities (e.g., diseases and chemicals) from the ever-growing biomedical literature. In this paper, we present BERN2 (Advanced Biomedical Entity Recognition and Normalization), a tool that improves the previous neural network-based NER tool (Kim et al., 2019) by employing a multi-task NER model and neural network-based NEN models to achieve much faster and more accurate inference. We hope that our tool can help annotate large-scale biomedical texts more accurately for various tasks such as biomedical knowledge graph construction.