 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
Paper and Code
Apr 09, 2025
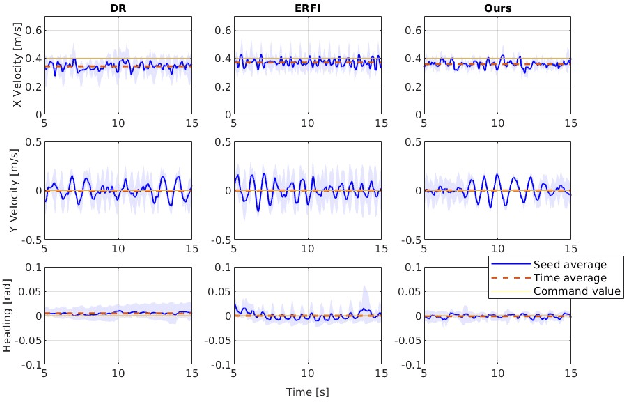
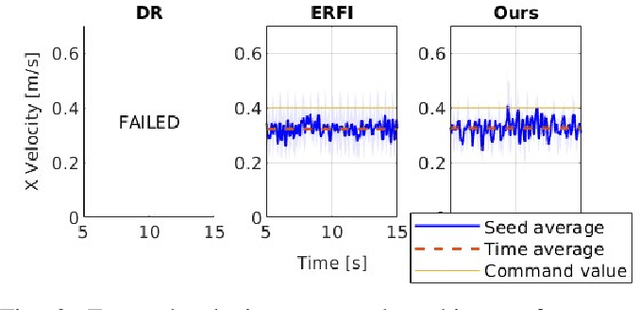
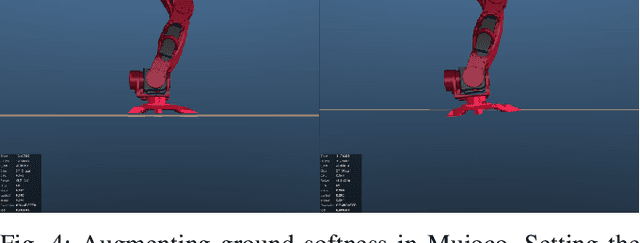
This paper proposes a novel alternative to existing sim-to-real methods for training control policies with simulated experiences. Prior sim-to-real methods for legged robots mostly rely on the domain randomization approach, where a fixed finite set of simulation parameters is randomized during training. Instead, our method adds state-dependent perturbations to the input joint torque used for forward simulation during the training phase. These state-dependent perturbations are designed to simulate a broader range of reality gaps than those captured by randomizing a fixed set of simulation parameters. Experimental results show that our method enables humanoid locomotion policies that achieve greater robustness against complex reality gaps unseen in the training domain.