 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Normalization for Lipschitz-Constrained Policies on Learning Humanoid Locomotion
Apr 11, 2025Reinforcement learning (RL) has shown great potential in training agile and adaptable controllers for legged robots, enabling them to learn complex locomotion behaviors directly from experience. However, policies trained in simulation often fail to transfer to real-world robots due to unrealistic assumptions such as infinite actuator bandwidth and the absence of torque limits. These conditions allow policies to rely on abrupt, high-frequency torque changes, which are infeasible for real actuators with finite bandwidth. Traditional methods address this issue by penalizing aggressive motions through regularization rewards, such as joint velocities, accelerations, and energy consumption, but they require extensive hyperparameter tuning. Alternatively, Lipschitz-Constrained Policies (LCP) enforce finite bandwidth action control by penalizing policy gradients, but their reliance on gradient calculations introduces significant GPU memory overhead. To overcome this limitation, this work proposes Spectral Normalization (SN) as an efficient replacement for enforcing Lipschitz continuity. By constraining the spectral norm of network weights, SN effectively limits high-frequency policy fluctuations while significantly reducing GPU memory usage. Experimental evaluations in both simulation and real-world humanoid robot show that SN achieves performance comparable to gradient penalty methods while enabling more efficient parallel training.
Sim-to-Real of Humanoid Locomotion Policies via Joint Torque Space Perturbation Injection
Apr 09, 2025
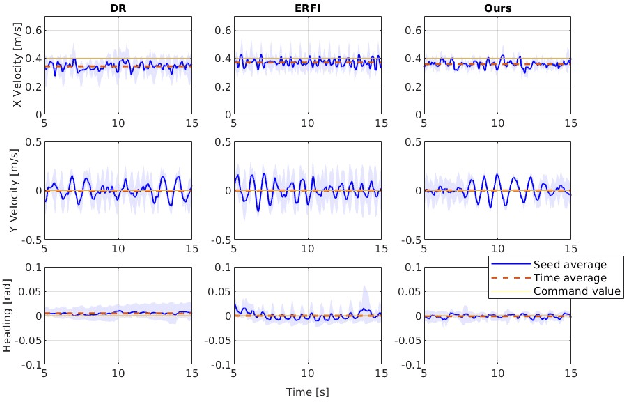
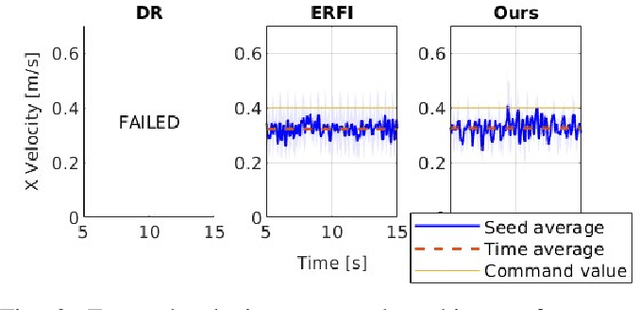
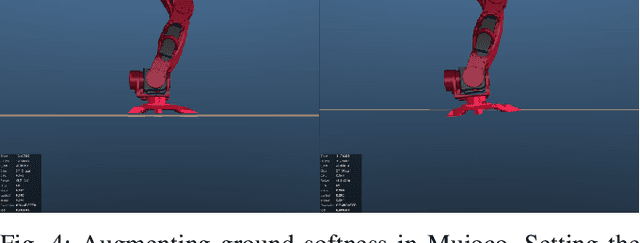
This paper proposes a novel alternative to existing sim-to-real methods for training control policies with simulated experiences. Prior sim-to-real methods for legged robots mostly rely on the domain randomization approach, where a fixed finite set of simulation parameters is randomized during training. Instead, our method adds state-dependent perturbations to the input joint torque used for forward simulation during the training phase. These state-dependent perturbations are designed to simulate a broader range of reality gaps than those captured by randomizing a fixed set of simulation parameters. Experimental results show that our method enables humanoid locomotion policies that achieve greater robustness against complex reality gaps unseen in the training domain.