 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Deployment: Auto-Curated Domain-Specific Dataset Generation via Diffusion Models
Jan 13, 2026In this paper, we present an automated pipeline for generating domain-specific synthetic datasets with diffusion models, addressing the distribution shift between pre-trained models and real-world deployment environments. Our three-stage framework first synthesizes target objects within domain-specific backgrounds through controlled inpainting. The generated outputs are then validated via a multi-modal assessment that integrates object detection, aesthetic scoring, and vision-language alignment. Finally, a user-preference classifier is employed to capture subjective selection criteria. This pipeline enables the efficient construction of high-quality, deployable datasets while reducing reliance on extensive real-world data collection.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Reference Guided Image Inpainting using Facial Attributes
Jan 19, 2023



Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

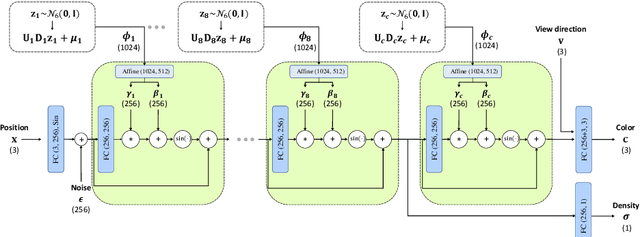
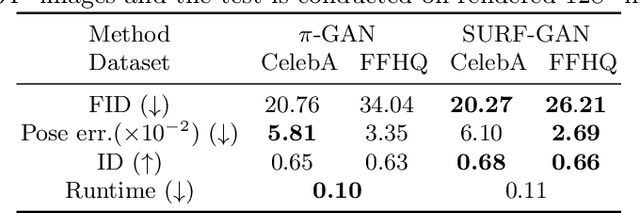
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022

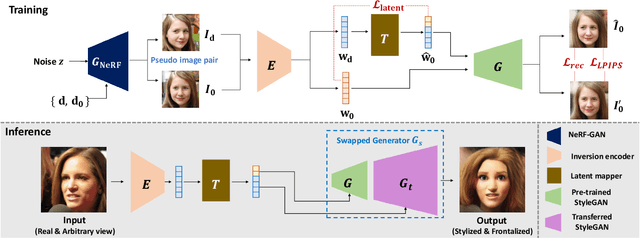

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
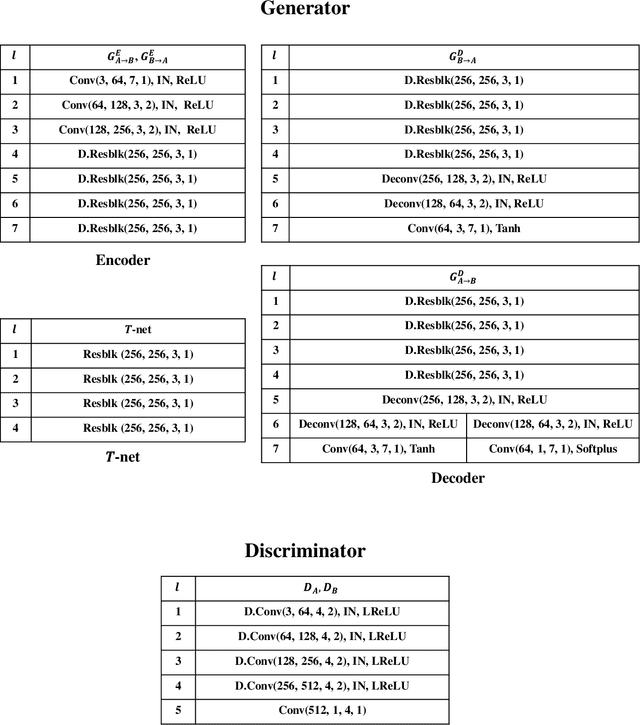


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.