 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerate and Edit Your Own Character in a Canonical View
Paper and Code
May 06, 2022

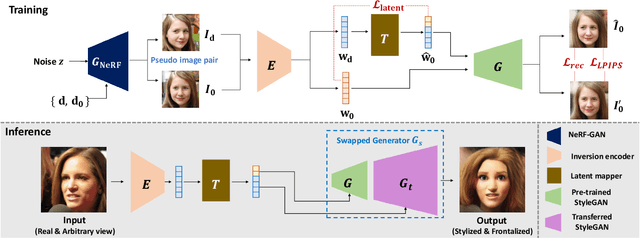

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.