 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResnet-conformer network with shared weights and attention mechanism for sound event localization, detection, and distance estimation
Jul 23, 2025This technical report outlines our approach to Task 3A of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2024, focusing on Sound Event Localization and Detection (SELD). SELD provides valuable insights by estimating sound event localization and detection, aiding in various machine cognition tasks such as environmental inference, navigation, and other sound localization-related applications. This year's challenge evaluates models using either audio-only (Track A) or audiovisual (Track B) inputs on annotated recordings of real sound scenes. A notable change this year is the introduction of distance estimation, with evaluation metrics adjusted accordingly for a comprehensive assessment. Our submission is for Task A of the Challenge, which focuses on the audio-only track. Our approach utilizes log-mel spectrograms, intensity vectors, and employs multiple data augmentations. We proposed an EINV2-based [1] network architecture, achieving improved results: an F-score of 40.2%, Angular Error (DOA) of 17.7 degrees, and Relative Distance Error (RDE) of 0.32 on the test set of the Development Dataset [2 ,3].
Domain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
May 02, 2024A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
Learning Scene Context Without Images
Nov 18, 2023Teaching machines of scene contextual knowledge would enable them to interact more effectively with the environment and to anticipate or predict objects that may not be immediately apparent in their perceptual field. In this paper, we introduce a novel transformer-based approach called $LMOD$ ( Label-based Missing Object Detection) to teach scene contextual knowledge to machines using an attention mechanism. A distinctive aspect of the proposed approach is its reliance solely on labels from image datasets to teach scene context, entirely eliminating the need for the actual image itself. We show how scene-wide relationships among different objects can be learned using a self-attention mechanism. We further show that the contextual knowledge gained from label based learning can enhance performance of other visual based object detection algorithm.
DIFAI: Diverse Facial Inpainting using StyleGAN Inversion
Jan 20, 2023Image inpainting is an old problem in computer vision that restores occluded regions and completes damaged images. In the case of facial image inpainting, most of the methods generate only one result for each masked image, even though there are other reasonable possibilities. To prevent any potential biases and unnatural constraints stemming from generating only one image, we propose a novel framework for diverse facial inpainting exploiting the embedding space of StyleGAN. Our framework employs pSp encoder and SeFa algorithm to identify semantic components of the StyleGAN embeddings and feed them into our proposed SPARN decoder that adopts region normalization for plausible inpainting. We demonstrate that our proposed method outperforms several state-of-the-art methods.
Reference Guided Image Inpainting using Facial Attributes
Jan 19, 2023



Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Controllable Face Manipulation and UV Map Generation by Self-supervised Learning
Sep 24, 2022

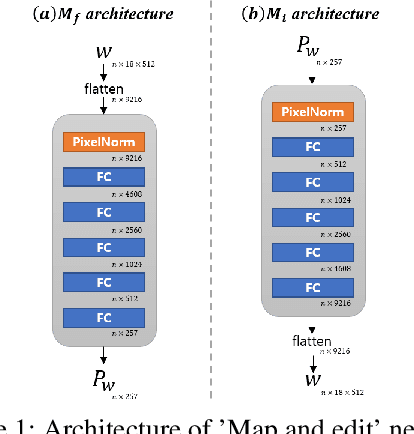
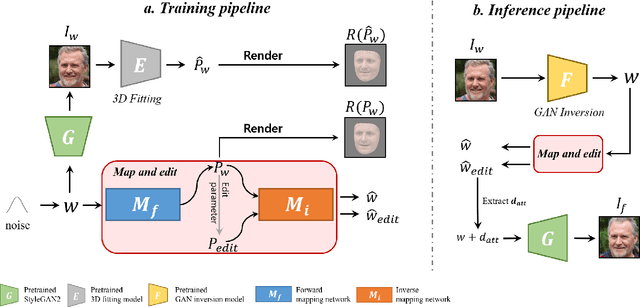
Although manipulating facial attributes by Generative Adversarial Networks (GANs) has been remarkably successful recently, there are still some challenges in explicit control of features such as pose, expression, lighting, etc. Recent methods achieve explicit control over 2D images by combining 2D generative model and 3DMM. However, due to the lack of realism and clarity in texture reconstruction by 3DMM, there is a domain gap between the synthetic image and the rendered image of 3DMM. Since rendered 3DMM images contain facial region only without the background, directly computing the loss between these two domains is not ideal and the resultant trained model will be biased. In this study, we propose to explicitly edit the latent space of the pretrained StyleGAN by controlling the parameters of the 3DMM. To address the domain gap problem, we propose a noval network called 'Map and edit' and a simple but effective attribute editing method to avoid direct loss computation between rendered and synthesized images. Furthermore, since our model can accurately generate multi-view face images while the identity remains unchanged. As a by-product, combined with visibility masks, our proposed model can also generate texture-rich and high-resolution UV facial textures. Our model relies on pretrained StyleGAN, and the proposed model is trained in a self-supervised manner without any manual annotations or datasets.
Injecting 3D Perception of Controllable NeRF-GAN into StyleGAN for Editable Portrait Image Synthesis
Jul 26, 2022

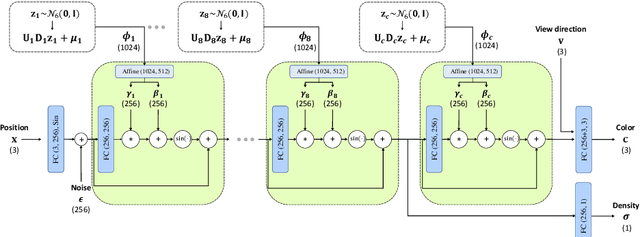
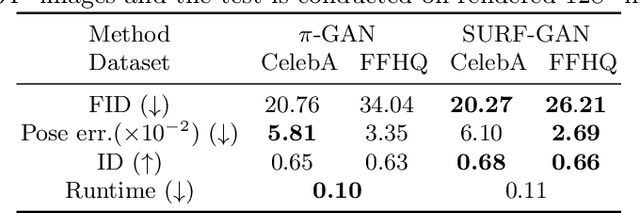
Over the years, 2D GANs have achieved great successes in photorealistic portrait generation. However, they lack 3D understanding in the generation process, thus they suffer from multi-view inconsistency problem. To alleviate the issue, many 3D-aware GANs have been proposed and shown notable results, but 3D GANs struggle with editing semantic attributes. The controllability and interpretability of 3D GANs have not been much explored. In this work, we propose two solutions to overcome these weaknesses of 2D GANs and 3D-aware GANs. We first introduce a novel 3D-aware GAN, SURF-GAN, which is capable of discovering semantic attributes during training and controlling them in an unsupervised manner. After that, we inject the prior of SURF-GAN into StyleGAN to obtain a high-fidelity 3D-controllable generator. Unlike existing latent-based methods allowing implicit pose control, the proposed 3D-controllable StyleGAN enables explicit pose control over portrait generation. This distillation allows direct compatibility between 3D control and many StyleGAN-based techniques (e.g., inversion and stylization), and also brings an advantage in terms of computational resources. Our codes are available at https://github.com/jgkwak95/SURF-GAN.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022

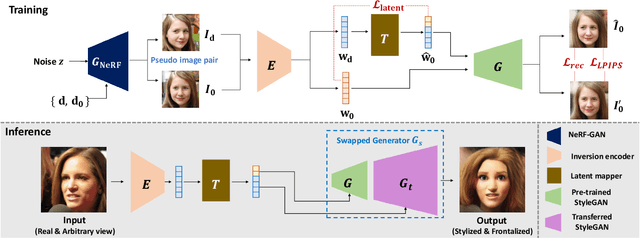

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
CPNet: Cross-Parallel Network for Efficient Anomaly Detection
Aug 13, 2021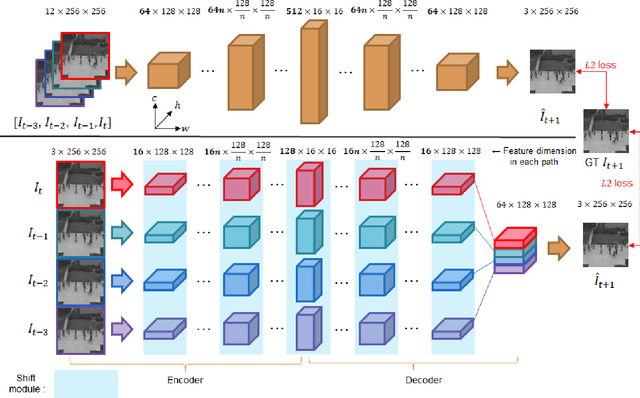
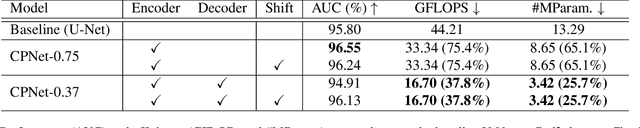
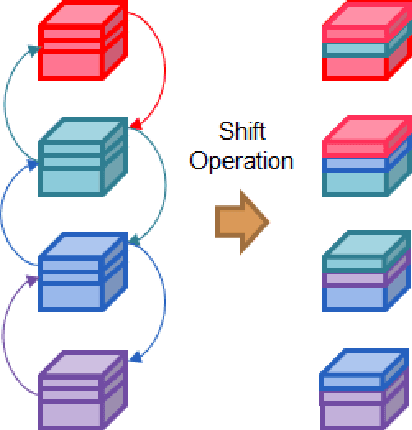
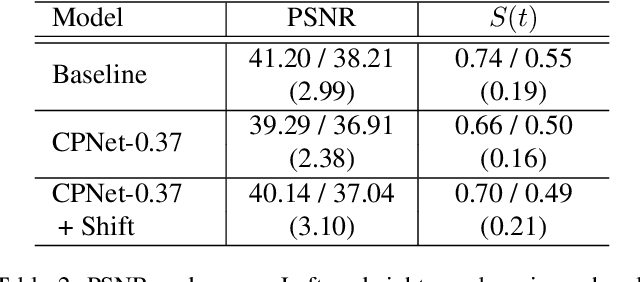
Anomaly detection in video streams is a challenging problem because of the scarcity of abnormal events and the difficulty of accurately annotating them. To alleviate these issues, unsupervised learning-based prediction methods have been previously applied. These approaches train the model with only normal events and predict a future frame from a sequence of preceding frames by use of encoder-decoder architectures so that they result in small prediction errors on normal events but large errors on abnormal events. The architecture, however, comes with the computational burden as some anomaly detection tasks require low computational cost without sacrificing performance. In this paper, Cross-Parallel Network (CPNet) for efficient anomaly detection is proposed here to minimize computations without performance drops. It consists of N smaller parallel U-Net, each of which is designed to handle a single input frame, to make the calculations significantly more efficient. Additionally, an inter-network shift module is incorporated to capture temporal relationships among sequential frames to enable more accurate future predictions.The quantitative results show that our model requires less computational cost than the baseline U-Net while delivering equivalent performance in anomaly detection.
Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations
Aug 10, 2021
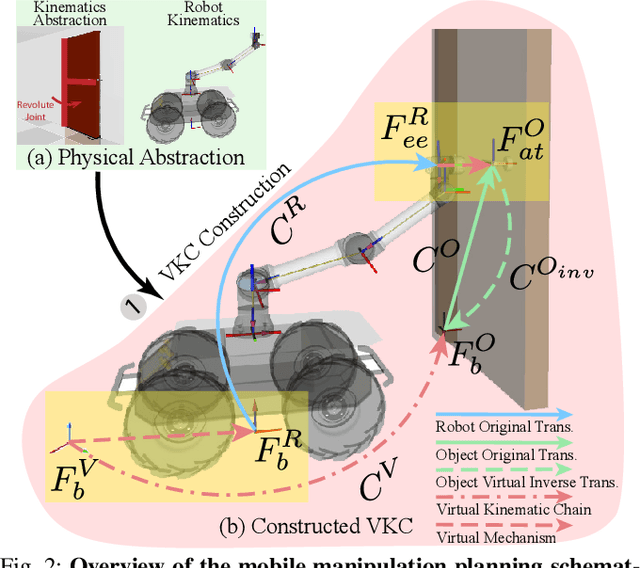

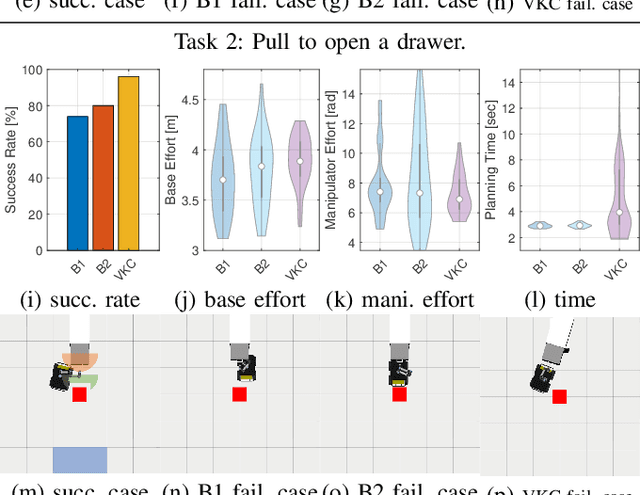
We construct a Virtual Kinematic Chain (VKC) that readily consolidates the kinematics of the mobile base, the arm, and the object to be manipulated in mobile manipulations. Accordingly, a mobile manipulation task is represented by altering the state of the constructed VKC, which can be converted to a motion planning problem, formulated, and solved by trajectory optimization. This new VKC perspective of mobile manipulation allows a service robot to (i) produce well-coordinated motions, suitable for complex household environments, and (ii) perform intricate multi-step tasks while interacting with multiple objects without an explicit definition of intermediate goals. In simulated experiments, we validate these advantages by comparing the VKC-based approach with baselines that solely optimize individual components. The results manifest that VKC-based joint modeling and planning promote task success rates and produce more efficient trajectories.