 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Guided Image Inpainting using Facial Attributes
Jan 19, 2023



Image inpainting is a technique of completing missing pixels such as occluded region restoration, distracting objects removal, and facial completion. Among these inpainting tasks, facial completion algorithm performs face inpainting according to the user direction. Existing approaches require delicate and well controlled input by the user, thus it is difficult for an average user to provide the guidance sufficiently accurate for the algorithm to generate desired results. To overcome this limitation, we propose an alternative user-guided inpainting architecture that manipulates facial attributes using a single reference image as the guide. Our end-to-end model consists of attribute extractors for accurate reference image attribute transfer and an inpainting model to map the attributes realistically and accurately to generated images. We customize MS-SSIM loss and learnable bidirectional attention maps in which importance structures remain intact even with irregular shaped masks. Based on our evaluation using the publicly available dataset CelebA-HQ, we demonstrate that the proposed method delivers superior performance compared to some state-of-the-art methods specialized in inpainting tasks.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
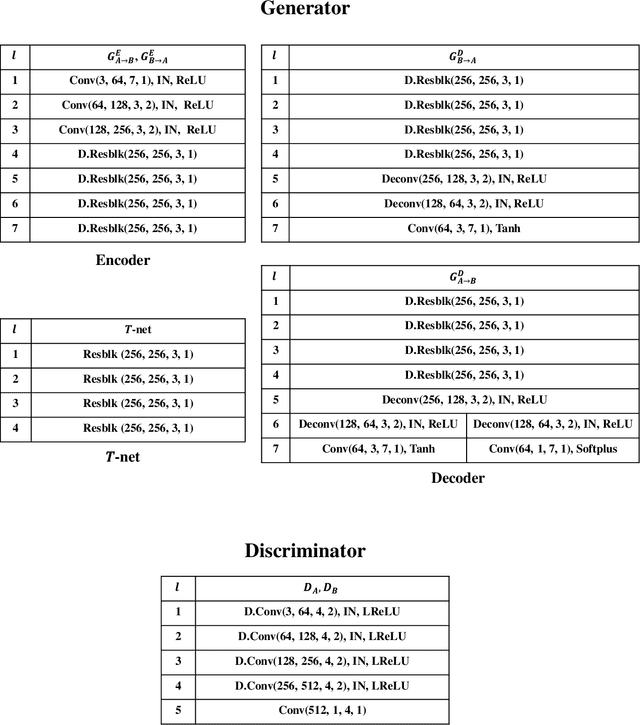


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
Memory-based Semantic Segmentation for Off-road Unstructured Natural Environments
Aug 18, 2021

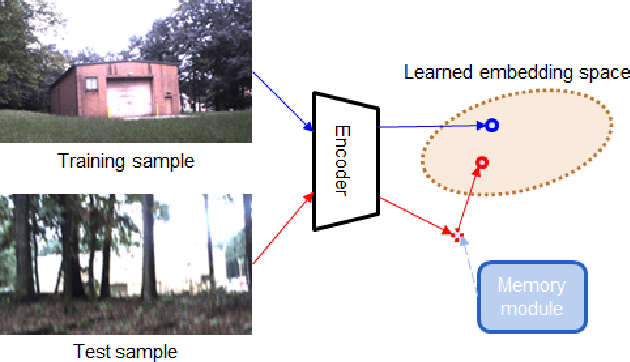
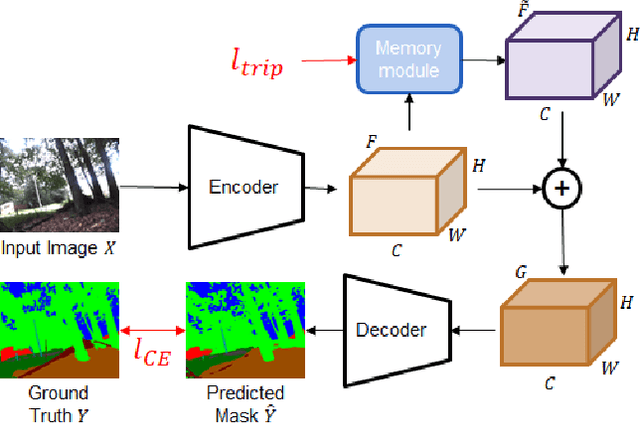
With the availability of many datasets tailored for autonomous driving in real-world urban scenes, semantic segmentation for urban driving scenes achieves significant progress. However, semantic segmentation for off-road, unstructured environments is not widely studied. Directly applying existing segmentation networks often results in performance degradation as they cannot overcome intrinsic problems in such environments, such as illumination changes. In this paper, a built-in memory module for semantic segmentation is proposed to overcome these problems. The memory module stores significant representations of training images as memory items. In addition to the encoder embedding like items together, the proposed memory module is specifically designed to cluster together instances of the same class even when there are significant variances in embedded features. Therefore, it makes segmentation networks better deal with unexpected illumination changes. A triplet loss is used in training to minimize redundancy in storing discriminative representations of the memory module. The proposed memory module is general so that it can be adopted in a variety of networks. We conduct experiments on the Robot Unstructured Ground Driving (RUGD) dataset and RELLIS dataset, which are collected from off-road, unstructured natural environments. Experimental results show that the proposed memory module improves the performance of existing segmentation networks and contributes to capturing unclear objects over various off-road, unstructured natural scenes with equivalent computational cost and network parameters. As the proposed method can be integrated into compact networks, it presents a viable approach for resource-limited small autonomous platforms.
CPNet: Cross-Parallel Network for Efficient Anomaly Detection
Aug 13, 2021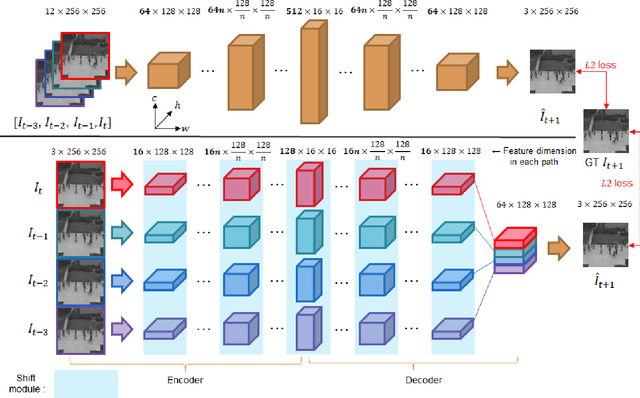
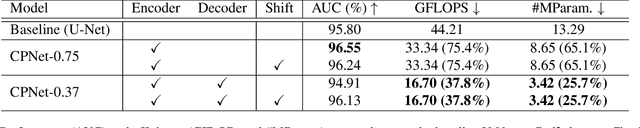
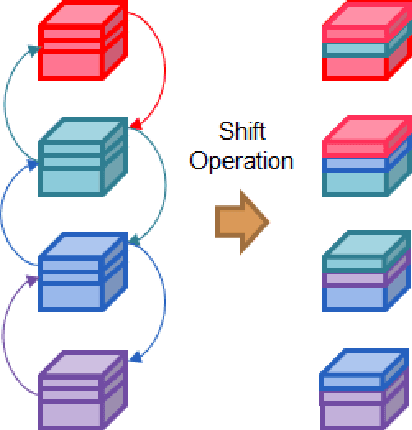
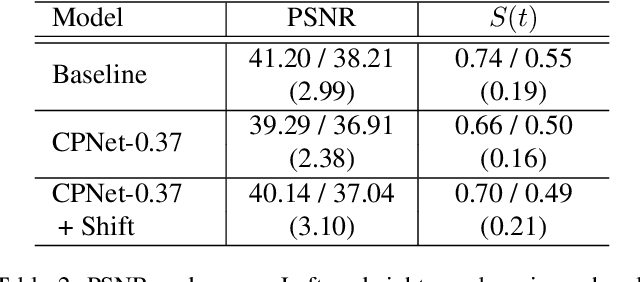
Anomaly detection in video streams is a challenging problem because of the scarcity of abnormal events and the difficulty of accurately annotating them. To alleviate these issues, unsupervised learning-based prediction methods have been previously applied. These approaches train the model with only normal events and predict a future frame from a sequence of preceding frames by use of encoder-decoder architectures so that they result in small prediction errors on normal events but large errors on abnormal events. The architecture, however, comes with the computational burden as some anomaly detection tasks require low computational cost without sacrificing performance. In this paper, Cross-Parallel Network (CPNet) for efficient anomaly detection is proposed here to minimize computations without performance drops. It consists of N smaller parallel U-Net, each of which is designed to handle a single input frame, to make the calculations significantly more efficient. Additionally, an inter-network shift module is incorporated to capture temporal relationships among sequential frames to enable more accurate future predictions.The quantitative results show that our model requires less computational cost than the baseline U-Net while delivering equivalent performance in anomaly detection.