 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Transferred Synthetic Data Generation for Improving Monocular Depth Estimation
May 02, 2024A major obstacle to the development of effective monocular depth estimation algorithms is the difficulty in obtaining high-quality depth data that corresponds to collected RGB images. Collecting this data is time-consuming and costly, and even data collected by modern sensors has limited range or resolution, and is subject to inconsistencies and noise. To combat this, we propose a method of data generation in simulation using 3D synthetic environments and CycleGAN domain transfer. We compare this method of data generation to the popular NYUDepth V2 dataset by training a depth estimation model based on the DenseDepth structure using different training sets of real and simulated data. We evaluate the performance of the models on newly collected images and LiDAR depth data from a Husky robot to verify the generalizability of the approach and show that GAN-transformed data can serve as an effective alternative to real-world data, particularly in depth estimation.
Low-Cost Generation and Evaluation of Dictionary Example Sentences
Apr 09, 2024Dictionary example sentences play an important role in illustrating word definitions and usage, but manually creating quality sentences is challenging. Prior works have demonstrated that language models can be trained to generate example sentences. However, they relied on costly customized models and word sense datasets for generation and evaluation of their work. Rapid advancements in foundational models present the opportunity to create low-cost, zero-shot methods for the generation and evaluation of dictionary example sentences. We introduce a new automatic evaluation metric called OxfordEval that measures the win-rate of generated sentences against existing Oxford Dictionary sentences. OxfordEval shows high alignment with human judgments, enabling large-scale automated quality evaluation. We experiment with various LLMs and configurations to generate dictionary sentences across word classes. We complement this with a novel approach of using masked language models to identify and select sentences that best exemplify word meaning. The eventual model, FM-MLM, achieves over 85.1% win rate against Oxford baseline sentences according to OxfordEval, compared to 39.8% win rate for prior model-generated sentences.
Energy-Aware Routing Algorithm for Mobile Ground-to-Air Charging
Sep 30, 2023
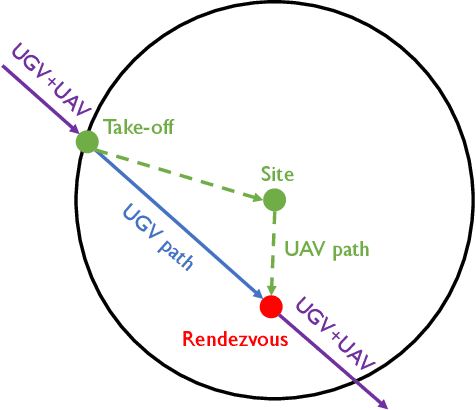
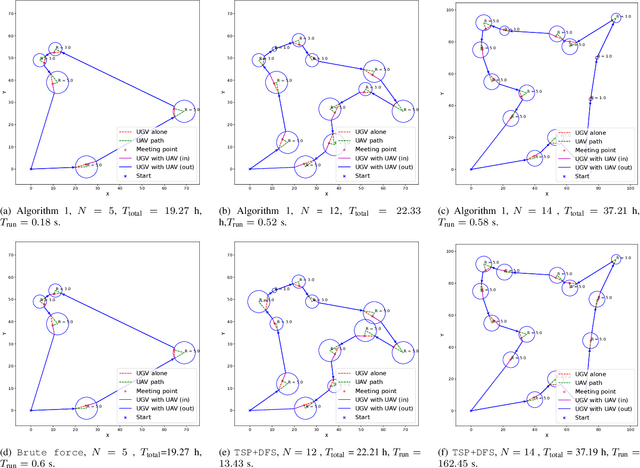
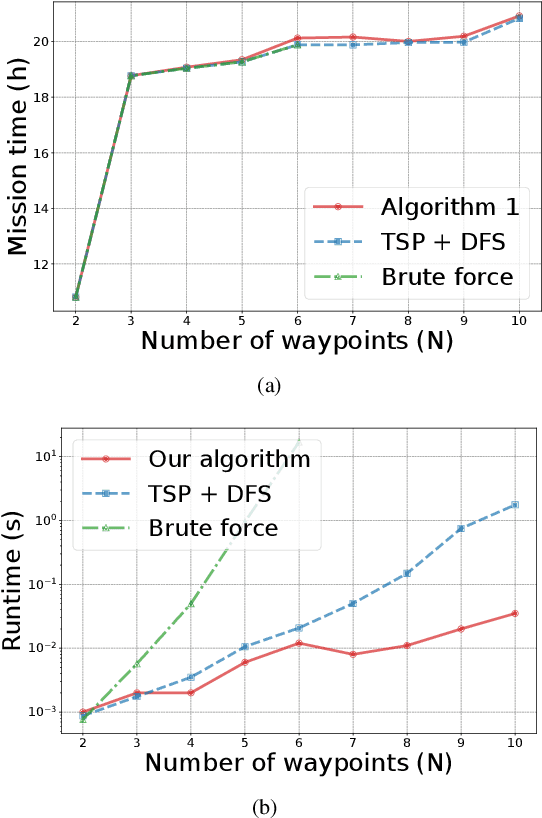
We investigate the problem of energy-constrained planning for a cooperative system of an Unmanned Ground Vehicles (UGV) and an Unmanned Aerial Vehicle (UAV). In scenarios where the UGV serves as a mobile base to ferry the UAV and as a charging station to recharge the UAV, we formulate a novel energy-constrained routing problem. To tackle this problem, we design an energy-aware routing algorithm, aiming to minimize the overall mission duration under the energy limitations of both vehicles. The algorithm first solves a Traveling Salesman Problem (TSP) to generate a guided tour. Then, it employs the Monte-Carlo Tree Search (MCTS) algorithm to refine the tour and generate paths for the two vehicles. We evaluate the performance of our algorithm through extensive simulations and a proof-of-concept experiment. The results show that our algorithm consistently achieves near-optimal mission time and maintains fast running time across a wide range of problem instances.
DAMSL: Domain Agnostic Meta Score-based Learning
Jun 06, 2021
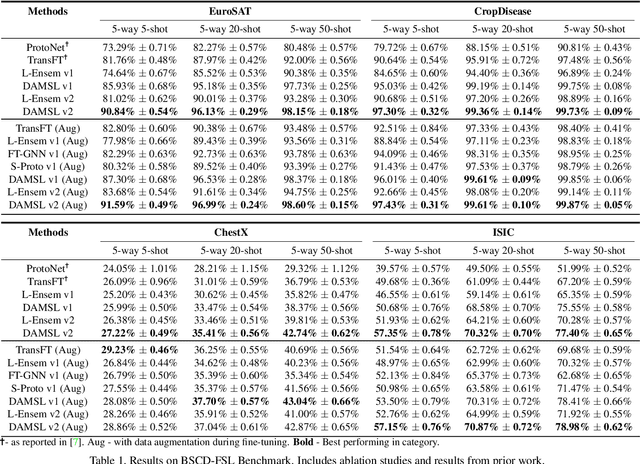
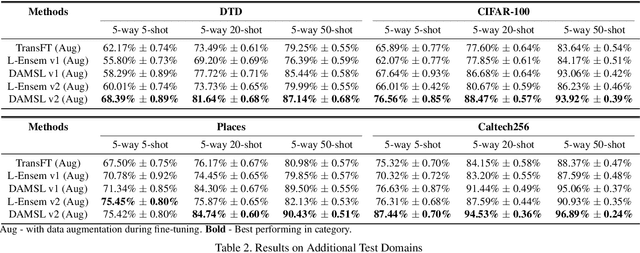

In this paper, we propose Domain Agnostic Meta Score-based Learning (DAMSL), a novel, versatile and highly effective solution that delivers significant out-performance over state-of-the-art methods for cross-domain few-shot learning. We identify key problems in previous meta-learning methods over-fitting to the source domain, and previous transfer-learning methods under-utilizing the structure of the support set. The core idea behind our method is that instead of directly using the scores from a fine-tuned feature encoder, we use these scores to create input coordinates for a domain agnostic metric space. A graph neural network is applied to learn an embedding and relation function over these coordinates to process all information contained in the score distribution of the support set. We test our model on both established CD-FSL benchmarks and new domains and show that our method overcomes the limitations of previous meta-learning and transfer-learning methods to deliver substantial improvements in accuracy across both smaller and larger domain shifts.
SB-MTL: Score-based Meta Transfer-Learning for Cross-Domain Few-Shot Learning
Dec 03, 2020



While many deep learning methods have seen significant success in tackling the problem of domain adaptation and few-shot learning separately, far fewer methods are able to jointly tackle both problems in Cross-Domain Few-Shot Learning (CD-FSL). This problem is exacerbated under sharp domain shifts that typify common computer vision applications. In this paper, we present a novel, flexible and effective method to address the CD-FSL problem. Our method, called Score-based Meta Transfer-Learning (SB-MTL), combines transfer-learning and meta-learning by using a MAML-optimized feature encoder and a score-based Graph Neural Network. First, we have a feature encoder with specific layers designed to be fine-tuned. To do so, we apply a first-order MAML algorithm to find good initializations. Second, instead of directly taking the classification scores after fine-tuning, we interpret the scores as coordinates by mapping the pre-softmax classification scores onto a metric space. Subsequently, we apply a Graph Neural Network to propagate label information from the support set to the query set in our score-based metric space. We test our model on the Broader Study of Cross-Domain Few-Shot Learning (BSCD-FSL) benchmark, which includes a range of target domains with highly varying dissimilarity to the miniImagenet source domain. We observe significant improvements in accuracy across 5, 20 and 50 shot, and on the four target domains. In terms of average accuracy, our model outperforms previous transfer-learning methods by 5.93% and previous meta-learning methods by 14.28%.
Quantifying Urban Canopy Cover with Deep Convolutional Neural Networks
Dec 03, 2019
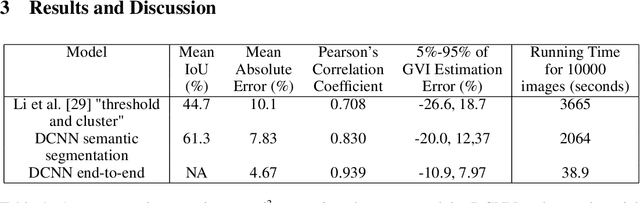
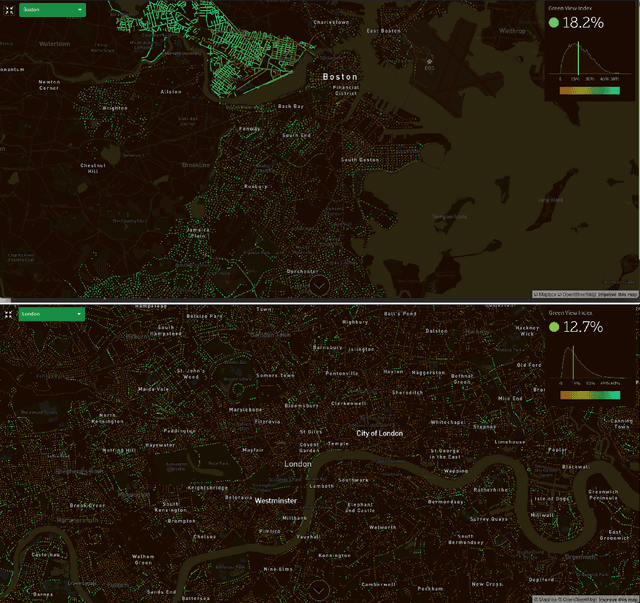

Urban canopy cover is important to mitigate the impact of climate change. Yet, existing quantification of urban greenery is either manual and not scalable, or use traditional computer vision methods that are inaccurate. We train deep convolutional neural networks (DCNNs) on datasets used for self-driving cars to estimate urban greenery instead, and find that our semantic segmentation and direct end-to-end estimation method are more accurate and scalable, reducing mean absolute error of estimating the Green View Index (GVI) metric from 10.1% to 4.67%. With the revised DCNN methods, the Treepedia project was able to scale and analyze canopy cover in 22 cities internationally, sparking interest and action in public policy and research fields.
Quantifying Legibility of Indoor Spaces Using Deep Convolutional Neural Networks: Case Studies in Train Stations
Jan 22, 2019
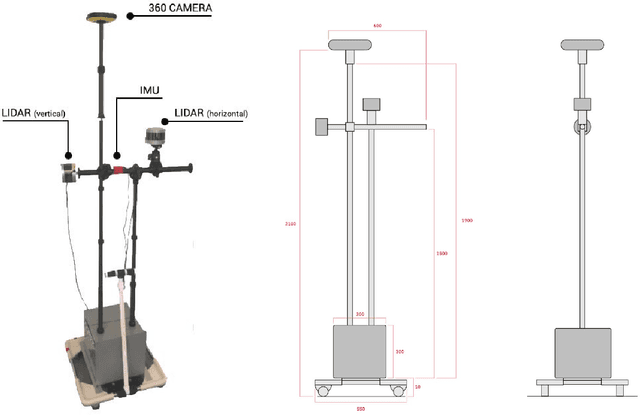
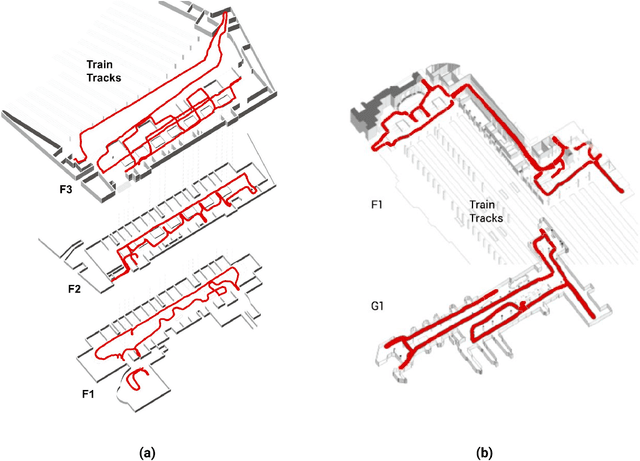

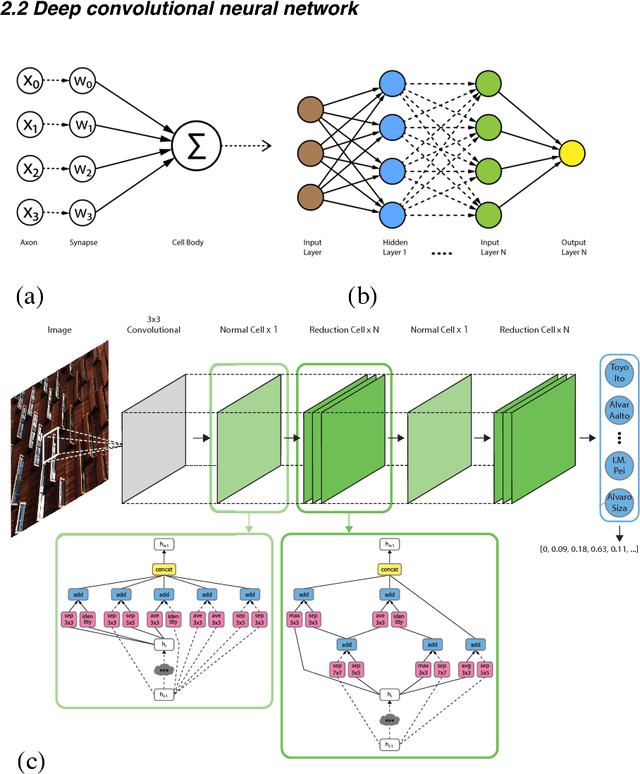
Legibility is the extent to which a space can be easily recognized. Evaluating legibility is particularly desirable in indoor spaces, since it has a large impact on human behavior and the efficiency of space utilization. However, indoor space legibility has only been studied through survey and trivial simulations and lacks reliable quantitative measurement. We utilized a Deep Convolutional Neural Network (DCNN), which is structurally similar to a human perception system, to model legibility in indoor spaces. To implement the modeling of legibility for any indoor spaces, we designed an end-to-end processing pipeline from indoor data retrieving to model training to spatial legibility analysis. Although the model performed very well (98% top-1 accuracy) overall, there are still discrepancies in accuracy among different spaces, reflecting legibility differences. To prove the validity of the pipeline, we deployed a survey on Amazon Mechanical Turk, collecting 4,015 samples. The human samples showed a similar behavior pattern and mechanism as the DCNN models. Further, we used model results to visually explain legibility in different architectural programs, building age, building style, visual clusterings of spaces and visual explanations for building age and architectural functions.
Deep Learning Architect: Classification for Architectural Design through the Eye of Artificial Intelligence
Dec 03, 2018


This paper applies state-of-the-art techniques in deep learning and computer vision to measure visual similarities between architectural designs by different architects. Using a dataset consisting of web scraped images and an original collection of images of architectural works, we first train a deep convolutional neural network (DCNN) model capable of achieving 73% accuracy in classifying works belonging to 34 different architects. Through examining the weights in the trained DCNN model, we are able to quantitatively measure the visual similarities between architects that are implicitly learned by our model. Using this measure, we cluster architects that are identified to be similar and compare our findings to conventional classification made by architectural historians and theorists. Our clustering of architectural designs remarkably corroborates conventional views in architectural history, and the learned architectural features also coheres with the traditional understanding of architectural designs.