 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFavelas 4D: Scalable methods for morphology analysis of informal settlements using terrestrial laser scanning data
Apr 23, 2021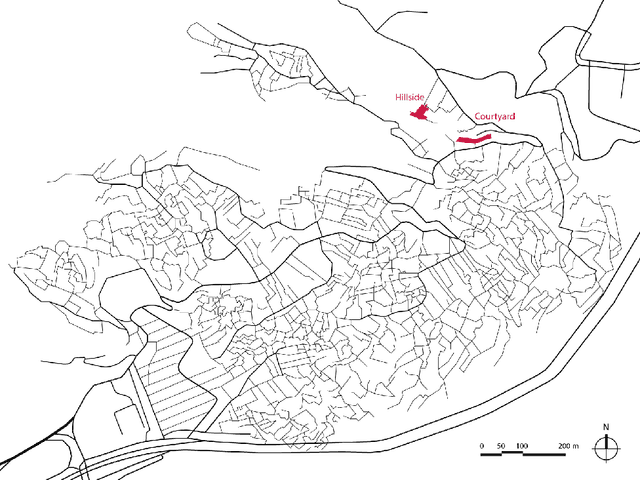

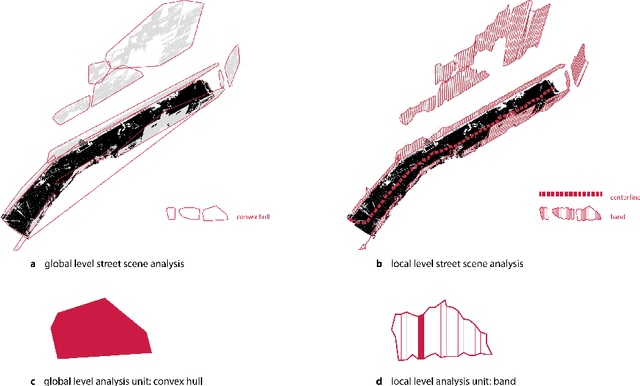
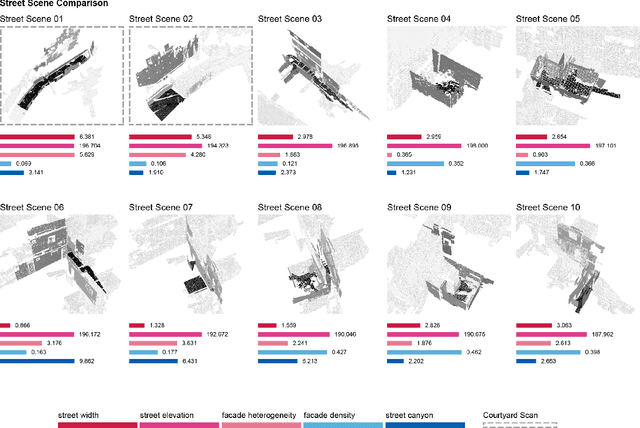
One billion people live in informal settlements worldwide. The complex and multilayered spaces that characterize this unplanned form of urbanization pose a challenge to traditional approaches to mapping and morphological analysis. This study proposes a methodology to study the morphological properties of informal settlements based on terrestrial LiDAR (Light Detection and Ranging) data collected in Rocinha, the largest favela in Rio de Janeiro, Brazil. Our analysis operates at two resolutions, including a \emph{global} analysis focused on comparing different streets of the favela to one another, and a \emph{local} analysis unpacking the variation of morphological metrics within streets. We show that our methodology reveals meaningful differences and commonalities both in terms of the global morphological characteristics across streets and their local distributions. Finally, we create morphological maps at high spatial resolution from LiDAR data, which can inform urban planning assessments of concerns related to crowding, structural safety, air quality, and accessibility in the favela. The methods for this study are automated and can be easily scaled to analyze entire informal settlements, leveraging the increasing availability of inexpensive LiDAR scanners on portable devices such as cellphones.
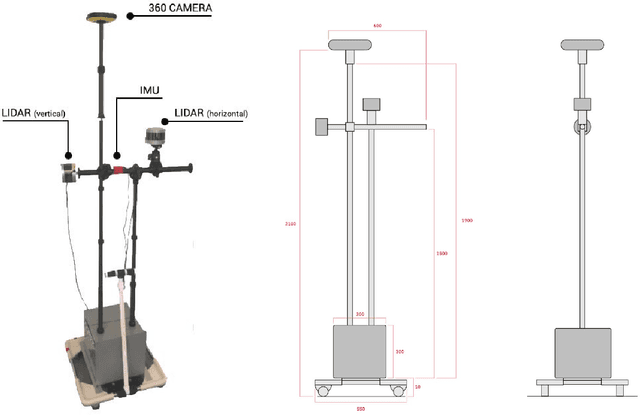
Robust Place Recognition using an Imaging Lidar
Mar 03, 2021

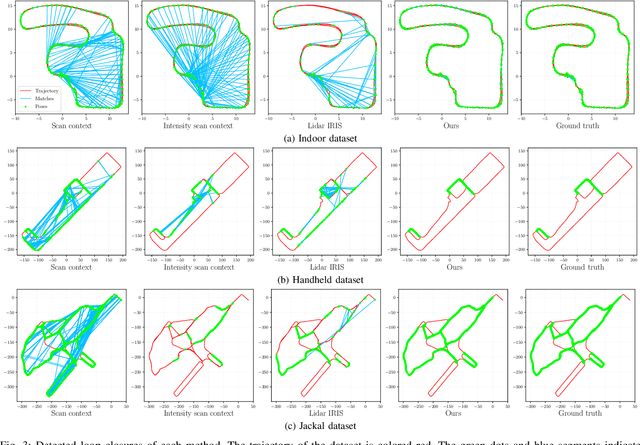

We propose a methodology for robust, real-time place recognition using an imaging lidar, which yields image-quality high-resolution 3D point clouds. Utilizing the intensity readings of an imaging lidar, we project the point cloud and obtain an intensity image. ORB feature descriptors are extracted from the image and encoded into a bag-of-words vector. The vector, used to identify the point cloud, is inserted into a database that is maintained by DBoW for fast place recognition queries. The returned candidate is further validated by matching visual feature descriptors. To reject matching outliers, we apply PnP, which minimizes the reprojection error of visual features' positions in Euclidean space with their correspondences in 2D image space, using RANSAC. Combining the advantages from both camera and lidar-based place recognition approaches, our method is truly rotation-invariant and can tackle reverse revisiting and upside-down revisiting. The proposed method is evaluated on datasets gathered from a variety of platforms over different scales and environments. Our implementation is available at https://git.io/imaging-lidar-place-recognition
Quantifying Legibility of Indoor Spaces Using Deep Convolutional Neural Networks: Case Studies in Train Stations
Jan 22, 2019
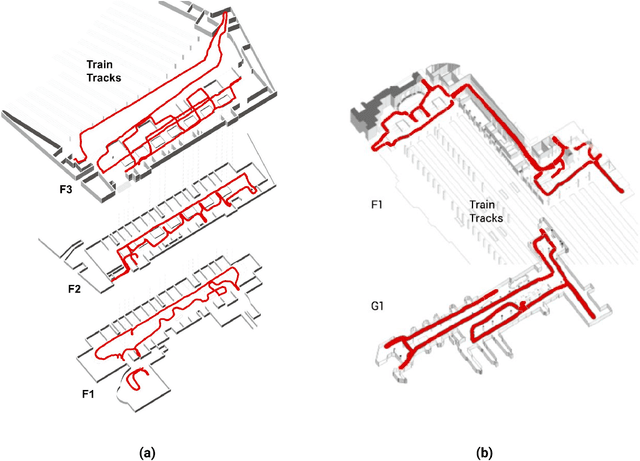

Legibility is the extent to which a space can be easily recognized. Evaluating legibility is particularly desirable in indoor spaces, since it has a large impact on human behavior and the efficiency of space utilization. However, indoor space legibility has only been studied through survey and trivial simulations and lacks reliable quantitative measurement. We utilized a Deep Convolutional Neural Network (DCNN), which is structurally similar to a human perception system, to model legibility in indoor spaces. To implement the modeling of legibility for any indoor spaces, we designed an end-to-end processing pipeline from indoor data retrieving to model training to spatial legibility analysis. Although the model performed very well (98% top-1 accuracy) overall, there are still discrepancies in accuracy among different spaces, reflecting legibility differences. To prove the validity of the pipeline, we deployed a survey on Amazon Mechanical Turk, collecting 4,015 samples. The human samples showed a similar behavior pattern and mechanism as the DCNN models. Further, we used model results to visually explain legibility in different architectural programs, building age, building style, visual clusterings of spaces and visual explanations for building age and architectural functions.
Indoor Space Recognition using Deep Convolutional Neural Network: A Case Study at MIT Campus
Oct 07, 2016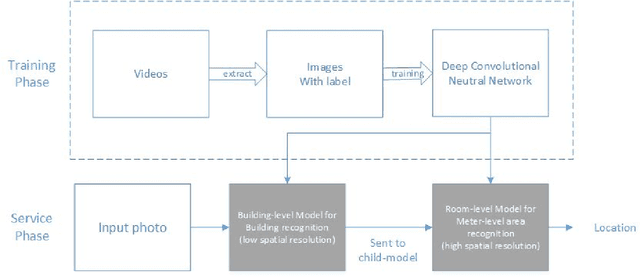
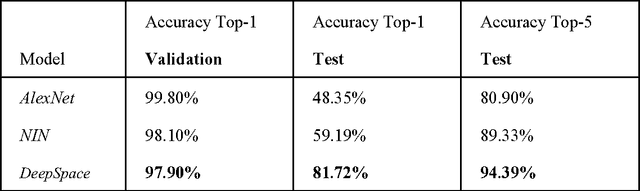
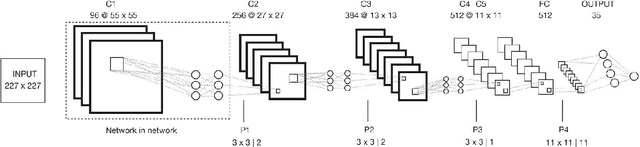
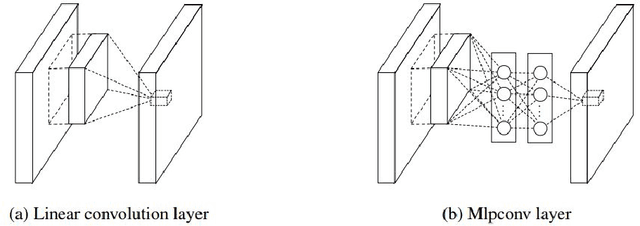
In this paper, we propose a robust and parsimonious approach using Deep Convolutional Neural Network (DCNN) to recognize and interpret interior space. DCNN has achieved incredible success in object and scene recognition. In this study we design and train a DCNN to classify a pre-zoning indoor space, and from a single phone photo to recognize the learned space features, with no need of additional assistive technology. We collect more than 600,000 images inside MIT campus buildings to train our DCNN model, and achieved 97.9% accuracy in validation dataset and 81.7% accuracy in test dataset based on spatial-scale fixed model. Furthermore, the recognition accuracy and spatial resolution can be potentially improved through multiscale classification model. We identify the discriminative image regions through Class Activating Mapping (CAM) technique, to observe the model's behavior in how to recognize space and interpret it in an abstract way. By evaluating the results with misclassification matrix, we investigate the visual spatial feature of interior space by looking into its visual similarity and visual distinctiveness, giving insights into interior design and human indoor perception and wayfinding research. The contribution of this paper is threefold. First, we propose a robust and parsimonious approach for indoor navigation using DCNN. Second, we demonstrate that DCNN also has a potential capability in space feature learning and recognition, even under severe appearance changes. Third, we introduce a DCNN based approach to look into the visual similarity and visual distinctiveness of interior space.